

关于英特尔4处理节点技术详解
处理器/DSP
描述
今年最受期待的演讲之一来自英特尔,他在展会上概述了即将推出的英特尔 4 工艺的物理和性能特征,该工艺将用于定于 2023 年发布的产品。英特尔的发展4 工艺对英特尔来说是一个重要的里程碑,因为它是英特尔第一个采用 EUV 的工艺,也是第一个超越陷入困境的 10nm 节点的工艺——这使英特尔第一次有机会重回正轨,重新获得晶圆厂的霸主地位。
英特尔计划于周二在题为“具有针对高密度和高性能计算优化的高级 FinFET 晶体管的英特尔 4 CMOS 技术”的演讲/论文中发表他们的英特尔 4 演示。但今天早上,在展会开始前,他们重新发布了论文及其所有相关数据,让我们第一次看到英特尔正在获得什么样的几何形状,以及有关所使用材料的更多信息。
Intel 4 以前称为 Intel 的 7nm 工艺,是 Intel 第一次在其芯片上使用 EUV 光刻技术。很长一段时间内,EUV 的使用既可以让英特尔绘制更先进的制造节点所需的那种更小的特征,同时让英特尔通过今天的多核技术减少所需的制造步骤数量。图案化 DUV 技术。不同寻常的是,英特尔发现自己是进入 EUV 的三大晶圆厂中的最后一家——该公司将 EUV 传递给 10nm 代,因为他们觉得它还没有准备好,然后延迟 10nm 和 7nm 推迟了英特尔的 EUV 采用点显著地。因此,英特尔将在 EUV 驱动的收益基础上迅速崛起,尽管他们仍然需要弥补失去的时间和台积电的经验优势。
英特尔 4 的开发对公司来说也是一个关键时刻,因为它最终让他们摆脱了陷入困境的 10nm 工艺。虽然英特尔已经设法制造出适合其 10 纳米工艺节点的产品——尤其是他们最新的 10 纳米增强型 SuperFin 变体,我们更好地称为英特尔 7——但它并非完全没有太多的血汗和岁月。英特尔认为,他们试图用 10nm 一次做太多事情——无论是在缩放方面还是在太多新的制造技术方面——这反过来又让他们倒退了好几年,因为他们解开了这些混乱,发现并迭代出了什么问题。不出所料,英特尔在他们的第一个 EUV 节点上没有那么激进,而且公司总体上采取了更加模块化的开发方法,允许实施新技术(并且,
今年最受期待的演讲之一来自英特尔,他在展会上概述了即将推出的英特尔 4 工艺的物理和性能特征,该工艺将用于定于 2023 年发布的产品。英特尔的发展4 工艺对英特尔来说是一个重要的里程碑,因为它是英特尔第一个采用 EUV 的工艺,也是第一个超越陷入困境的 10nm 节点的工艺——这使英特尔第一次有机会重回正轨,重新获得晶圆厂的霸主地位。
英特尔计划于周二在题为“具有针对高密度和高性能计算优化的高级 FinFET 晶体管的英特尔 4 CMOS 技术”的演讲/论文中发表他们的英特尔 4 演示。但今天早上,在展会开始前,他们重新发布了论文及其所有相关数据,让我们第一次看到英特尔正在获得什么样的几何形状,以及有关所使用材料的更多信息。
Intel 4 以前称为 Intel 的 7nm 工艺,是 Intel 第一次在其芯片上使用 EUV 光刻技术。很长一段时间内,EUV 的使用既可以让英特尔绘制更先进的制造节点所需的那种更小的特征,同时让英特尔通过今天的多核技术减少所需的制造步骤数量。图案化 DUV 技术。不同寻常的是,英特尔发现自己是进入 EUV 的三大晶圆厂中的最后一家——该公司将 EUV 传递给 10nm 代,因为他们觉得它还没有准备好,然后延迟 10nm 和 7nm 推迟了英特尔的 EUV 采用点显著地。因此,英特尔将在 EUV 驱动的收益基础上迅速崛起,尽管他们仍然需要弥补失去的时间和台积电的经验优势。
英特尔 4 的开发对公司来说也是一个关键时刻,因为它最终让他们摆脱了陷入困境的 10nm 工艺。虽然英特尔已经设法制造出适合其 10 纳米工艺节点的产品——尤其是他们最新的 10 纳米增强型 SuperFin 变体,我们更好地称为英特尔 7——但它并非完全没有太多的血汗和岁月。英特尔认为,他们试图用 10nm 一次做太多事情——无论是在缩放方面还是在太多新的制造技术方面——这反过来又让他们倒退了好几年,因为他们解开了这些混乱,发现并迭代出了什么问题。不出所料,英特尔在他们的第一个 EUV 节点上没有那么激进,而且公司总体上采取了更加模块化的开发方法,允许实施新技术(并且,
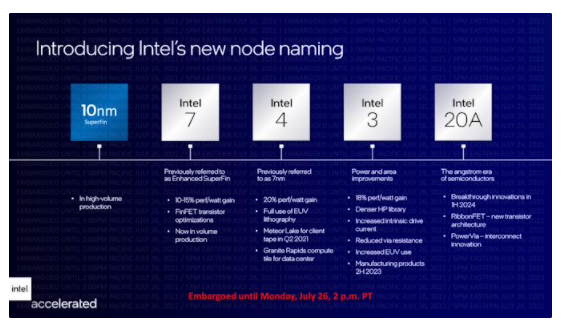
反过来,英特尔 4 将首先用于英特尔即将推出的 Meteor Lake 客户端 SoC,该 SoC 有望成为英特尔第 14 代酷睿处理器家族的基础。尽管要到 2023 年才发货,但英特尔已经按照公司典型的启动流程在他们的实验室中启动并运行了 Meteor Lake 。除了在工艺技术上取得显着进步外,Meteor Lake 还将成为英特尔的第一个基于 tile/chiplet 的客户端 CPU,它使用混合用于 I/O、CPU 内核和 GPU 内核的 tile。

Intel 4 物理参数:密度比 Intel 7 高 2 倍,钴继续使用
深入英特尔 4 进程,英特尔已着手解决一些不同的问题。首先,当然是密度。英特尔正在努力保持摩尔定律的活力,虽然 Dennard 缩放的同时死亡意味着在每一代上点亮两倍数量的晶体管不再是一件简单的事情,更高的晶体管密度可以在相同的硬件上提供更小的芯片,或者使用更新的设计投入更多的内核(或其他处理硬件)。
比较英特尔 4 和英特尔 7
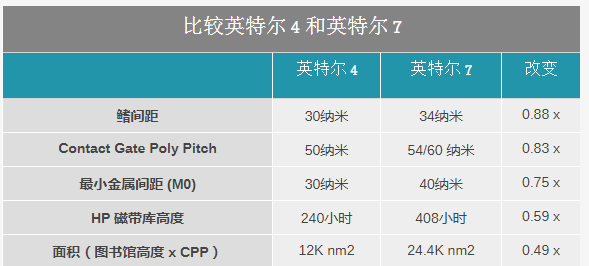
英特尔在本周的论文中发布的数据中,英特尔 4 的鳍片间距降至 30 纳米,是英特尔 7 的 34 纳米间距的 0.88 倍。同样,接触栅之间的间距现在为 50nm,低于之前的 60nm。但最重要的是,最低层 (M0) 的最小金属间距也是 30nm,是 Intel 7 上 M0 间距大小的 0.75 倍。
英特尔的库高度也被降低了。Intel 4 上高性能库的单元高度为 240nm,仅为 Intel 7 上 HP 单元高度的 0.59 倍。
因此,英特尔声称英特尔 4 的密度比英特尔 7 增加了 2 倍——或者更具体地说,晶体管的尺寸减少了一半——这是传统的全节点晶体管密度的改进。
由于芯片是二维结构,英特尔为此使用的度量标准是将 HP 单元高度乘以接触的多晶硅间距,这实际上是单元的宽度。在这种情况下,英特尔 7 获得 24,408 nm 2,英特尔 4 获得平坦的 12,000 nm 2,是基于英特尔 7 的单元面积的 0.49 倍。
当然,并非每种类型的结构都以相同的因素与新的工艺节点进行扩展,英特尔 4 也不例外。据该公司称,英特尔 4 上的 SRAM 单元的大小仅为英特尔 7 上相同单元的 0.77 倍左右。因此,虽然标准化逻辑单元的密度翻了一番,但 SRAM 密度(对于等效 SRAM 类型)仅提高了 30% 左右。
而且,不幸的是,虽然英特尔在谈论标准单元的密度,但他们并没有正式披露实际的晶体管密度数据。目前,英特尔告诉我们的是,整体晶体管密度与他们目前提供的 2 倍数字相得益彰。根据我们对英特尔 7 及其 HP 库每 mm 2密度 8000 万个晶体管的了解,英特尔 4 的 HP 库将达到 160MTr/mm 2左右。
由于这些数字是针对英特尔的低密度高性能库的,因此显而易见的后续问题将是针对高密度库的数字——传统上,这些数字会进一步压缩以换取降低的时钟速度。然而事实证明,英特尔不会为英特尔 4 开发高密度库。相反,英特尔 4 将是一个纯粹的高性能节点,高密度设计将伴随后续节点英特尔 3 出现。
这一不同寻常的发展源于英特尔在工艺节点开发方面的模块化努力。在未来五年左右的时间里,英特尔基本上采用了类似滴答滴答的策略进行节点开发,英特尔基于新技术(例如 EUV 或高 NA 机器)开发了一个初始节点,然后在此基础上开发了更多的节点。精炼/优化的继任者。就英特尔 4 而言,虽然它在英特尔的晶圆厂内为 EUV 做重要的开创性工作,但该公司更大的计划是让英特尔 3 成为其长期、长寿命的 EUV 节点。
所有这一切都意味着英特尔不需要英特尔 4 的高密度库,因为它计划在一年左右的时间内被功能更全面的英特尔 3 所取代。由于英特尔 3 在设计上与英特尔 4 兼容,因此可以清楚地看到英特尔如何在时间表允许的情况下推动其自己的设计团队使用后者的流程。英特尔代工服务客户也将处于类似的境地——他们可以使用英特尔 4,但 IFS 更专注于提供对英特尔 3 的访问和设计帮助。
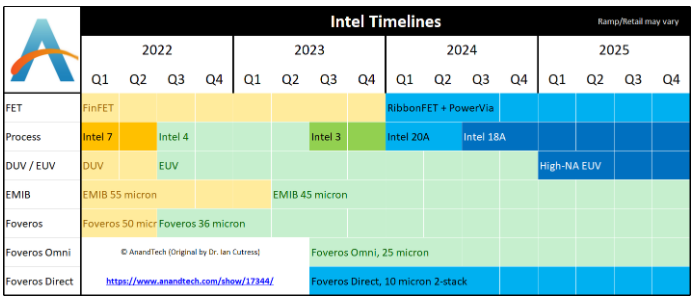
回到 Intel 4 本身,与 Intel 的 10nm 工艺相比,新节点对金属层进行了重大更改。众所周知,英特尔在其 10nm 工艺的最底层用钴代替了铜,该公司认为出于晶体管寿命(抗电迁移)的原因,这是必要的。不幸的是,从性能(时钟速度)的角度来看,钴并没有那么好,长期以来一直怀疑转向钴是英特尔 10nm 开发的主要绊脚石之一。
反过来,对于英特尔 4,英特尔正在后退半步。该公司仍在其工艺中使用钴,但现在他们使用的不是纯钴,而是他们所谓的增强铜 (eCu),即铜包覆钴。eCu 背后的理念是两全其美,保持掺杂铜金属化层的性能,同时仍获得钴的抗电迁移优势。
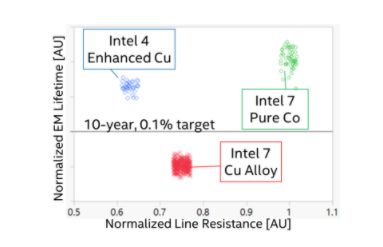
比较了不同冶金选项的电迁移寿命和线路电阻。
虽然英特尔不再使用纯钴,但在某些方面,他们对钴的使用总体上正在增加。英特尔的 10nm 工艺仅将钴用于接触栅极和前两个金属层,而英特尔 4 正在将 eCu 的使用扩展到前 5 个金属层。因此,芯片中完整金属层堆栈中最低的三分之一使用的是英特尔的钴包铜。然而,英特尔已经从栅极本身中去除了钴。现在是纯钨,而不是钨和钴的混合物。
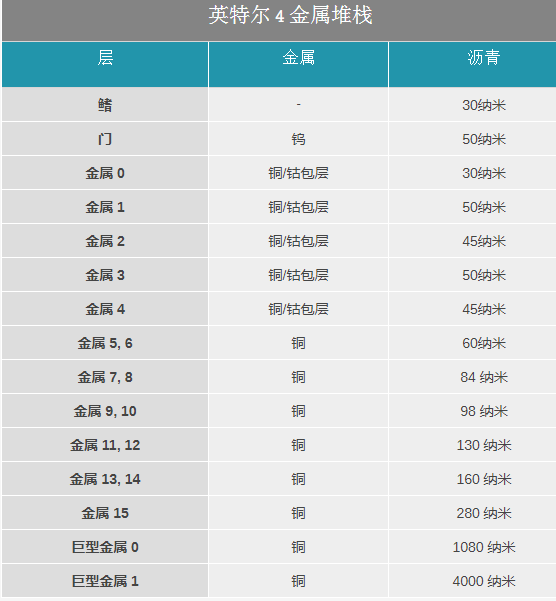
总而言之,英特尔 4 的金属层数量比英特尔 7 有所增加。后者有 15 个用于逻辑的金属层,而英特尔 4 挤进了第 16层。这与通常的两层电源布线相连,英特尔称其为巨型层,因为它们的间距相对较大,分别为 1080nm 和 4000nm。
除了更紧密的栅极和金属层间距之外,英特尔还通过更改互连设计规则来提高密度的另一个领域。在 Intel 4 中,Intel 已经转向他们所谓的网格互连设计,简而言之,它只允许按照预定网格放置金属层之间的通孔。以前,过孔可以放置在任何地方,这具有一定的灵活性,但也有其他权衡。
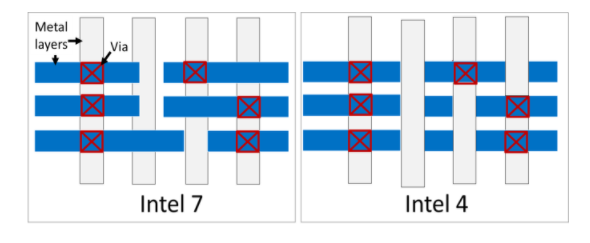
设计规则从传统(左)更改为网格(右),通过降低电容来提高产量和性能
据英特尔称,网格的使用通过减少可变性提高了工艺的产量,以及它们如何优化设计。该开关还有一个额外的好处,就是让英特尔不必为他们的互连使用复杂的、多图案的 EUV。
最后,如前所述,EUV 的使用还允许英特尔减少制造芯片所需的步骤数量(和掩模数量)。虽然该公司没有提供绝对数量,但相对而言,英特尔 4 需要的掩模数量比英特尔 7 少 20%。如果英特尔不这样做,所需掩模的数量反而会激增 30% 左右,因为需要多模式步骤。
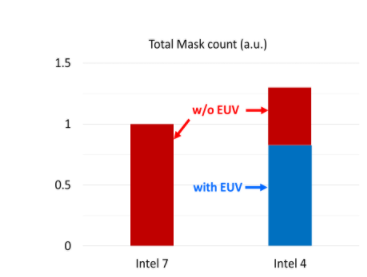
广泛使用 EUV 可实现特征缩放和工艺简化
EUV 的使用也对英特尔的产量产生了积极影响。尽管该公司没有提供确切的数字,但步骤数量的减少减少了任何会在晶圆上引入缺陷的错误的机会。
英特尔 4 性能:等功率下性能提高 21.5%/等频下功率降低 40%
抛开密度改进不谈,英特尔在英特尔 4 工艺中看到了什么样的性能改进?简而言之,英特尔在频率和能效方面都获得了高于平均水平的收益。
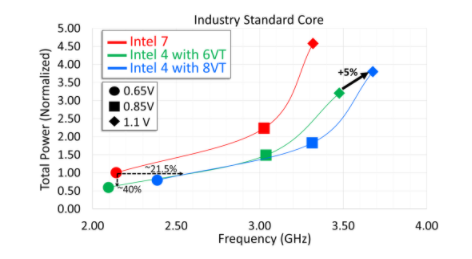
行业标准内核的电路分析显示,在 0.65V 电压下,与 Intel 7 相匹配的电源性能提升了 21.5%。在高压下,8VT 流量比 6VT 可实现 5% 的性能增益。
在 0.65v 的等功率下,英特尔的时钟速度与英特尔 7 相比提高了 21.5%。话虽如此,0.65v 处于曲线的低端,英特尔的图表确实显示随着你走得更远,收益递减电压;在 0.85v 及以上时,等功率增益接近 10%。据英特尔称,他们可以通过使用专为更高阈值电压 (8VT) 设计的电池再挤出 5% 左右的电量,但与标准电池相比,其总功耗会更高。
如果我们从另一端来看,英特尔报告称,英特尔 4 在电源效率方面的收益更大。在等频(在本例中为 2.1GHz 左右)下,英特尔的功耗降低了 40%。随着频率的增加,收益再次递减(直到英特尔 7 达到其实际极限),但它比性能/频率增益更一致。这反映了我们在其他进程节点上看到的情况——包括英特尔 7 在其发布时——在这些节点中,较新的节点正在以比它们实现更高时钟速度的速度更快的速度降低功耗。可以想象,一个基于 Intel 4 进程的完整 CPU 可以节省大量电力——只要您不介意它的时钟频率不会比以前更高。
总而言之,英特尔论文中概述的性能提升反映了他们迄今为止一直声称的性能提升,例如在去年夏天的工艺路线图更新中讨论的英特尔 4 的每瓦性能提升 20%。去年,英特尔一直在接近英特尔 4 开发的终点线,因此正如他们的论文概述的那样,他们似乎正在实现性能提升。
同时,英特尔还报告了从英特尔 7 到英特尔 4 成本扩展的良好发展,尽管该公司再次没有提供具体数字。1 个 EUV 层最终确实比 1 个 DUV 层更昂贵,但由于 EUV 消除了一堆多重图案,它有助于通过减少总步骤数来降低总成本。转向 EUV 也减轻了英特尔的资金压力,因为英特尔 4 不需要那么多的洁净室空间(尽管总体上绝不是很小的数量)。
最终,随着英特尔希望在 2023 年推出 Meteor Lake 和其他第一代英特尔 4 产品,英特尔能够以多快的速度让他们的新工艺节点启动并运行到大批量制造的标准,还有待观察。随着英特尔实验室中已经有 Meteor Lake 样品,英特尔离最终进入 EUV 时代越来越近。但对于英特尔来说,实现他们的所有目标不仅意味着扩大希尔斯伯勒开发工厂的生产规模,而且还需要掌握将其工艺复制到爱尔兰和其他英特尔工厂的有趣任务,这些工厂将用于英特尔 4。
-
英特尔发布至强6处理器产品2024-09-23 1309
-
苹果M3芯片和英特尔酷睿i9处理器哪个强2024-03-08 9343
-
英特尔x86处理器市占率为68.7%,AMD则上升至31.3%2023-02-14 2013
-
英特尔十代酷睿i7处理器也有TVB加速技术2020-04-14 7938
-
浪潮发布基于英特尔至强铂金9200处理器的HPC系统2019-12-24 3914
-
英特尔至强E-2200处理器现可用于入门级服务器2019-11-29 4429
-
国产CPU性能接近i3处理器,与英特尔i5看齐2018-08-28 6468
-
新人福利!英特尔至强E3处理器面市,专为入门级工作站打造2018-07-14 4907
-
英特尔酷睿i9处理器助力打造极致的游戏和内容创建体验2018-04-12 10644
-
英特尔在CES发布酷睿i7处理器和VR体验技术2017-01-05 2217
-
三星麻烦了 英特尔将为苹果iPhone供给ARM芯片2013-03-12 3546
-
英特尔发布只需0.28V电源电压驱动的x86处理器2012-02-23 1436
-
英特尔赛扬440处理器产品简介2011-12-07 2252
-
支持嵌入式计算的基于英特尔赛扬处理器U3405、P4500和P4505的平台2011-03-11 3694
全部0条评论

快来发表一下你的评论吧 !
