

深度嵌入式应用程序的多核微控制器驱动性能
控制/MCU
描述
虽然多核处理在个人计算机中的广泛采用肯定已经提升了它们的地位,但这种趋势背后的真正好处可能并不那么明显,尤其是对于深度嵌入式应用程序的开发人员而言。
实际上,许多计算密集型设备在某种程度上使用了多处理器架构。一段时间以来,移动电话使用多核设备,这些设备本身取代了多个分立处理器。随着基于一系列架构的多核处理器变得广泛可用,同样水平的整合也席卷了其他应用领域,例如工业控制、电信和网络。现在越来越清楚的是,推动使用多核设备的动力正在推动嵌入式领域多核微控制器的发展。
对更多处理能力的需求是毋庸置疑的,但多核设备的功效有时是这样的;人们普遍认为,在大多数应用程序中,多核的好处不会超过四核。
在深度嵌入式应用中,这些好处可能更难以识别,尤其是随着低端和低成本 32 位微控制器的普及。然而,虽然这些设备显然功能强大,但它们的使用不一定是互补的;创建一个定制的多处理平台可能很困难。集成设备制造商现在正在介入,创建低水平设计的设备,以提供同质和异构多核微控制器。
统一架构
在基本层面上,多核设备提供了两全其美;大多数微控制器指令集非常擅长控制任务,但不一定擅长数据处理。修改该指令集(以及因此底层架构)以添加以数据为中心的指令已变得更加普遍,并产生了有时称为统一架构的东西,但可能更常见的是数字信号控制器 (DSC)。
DSC 已经面世一段时间了,它代表了迈向完整“多核”微控制器的第一步。他们解决的应用通常反映了在微控制器传统上很强大或正在寻求变得强大的应用中,对“不仅仅是控制”的需求不断增长。电机控制就是一个例子,但许多 DSC 的目标是更通用的以控制为中心的应用,并集成了一系列外围设备来支持这一点。
一个例子是飞思卡尔的 56F807它基于飞思卡尔的 56800 内核,结合了类似 MCU 的功能和 DSP 的处理能力。该内核遵循哈佛架构,包括三个能够并行运行的执行单元,每个指令周期最多可进行六个操作。它还保留了“C 友好”格式,从而减少了在汇编程序级别对设备进行编程以实现高效代码执行的必要性。56F807 具有两个脉冲宽度调制器,每个都提供三个互补的可编程输出,飞思卡尔将其描述为特定于应用的功能。
Microchip的dsPIC 系列在 DSC 产品领域也很强大。 这还具有哈佛架构,具有修改后的指令集和指令预取机制,旨在帮助维持吞吐量和可预测的执行,并辅以在单个周期内执行的大多数指令。DSP 引擎具有一个 17 x 17 位乘法器、40 位 ALU、两个 40 位饱和累加器和一个 40 位双向桶形移位器。
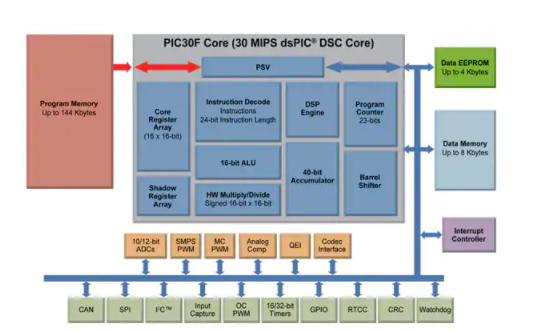
图 1:Microchip 的 dsPIC 具有统一的指令集,可将 DSP 和 MCU 功能结合在一个器件中。
对称处理
微控制器多核路径的下一个演进步骤是引入了具有相同内核的两个实例的设备,或同质多核设备。由于它们共享资源,这些设备的即时好处是两倍的处理性能,不到两倍的价格(或系统功率)。
更重要的是它提供了对对称多处理的访问;通过在两个核心而不是一个核心上同时运行给定任务的能力。每个相同的内核都代表一个“统一”架构,因为它通常基于经过修改的哈佛架构,具有专门设计用于提供 DSP 和 MCU 功能的指令集。
对于 Analog Devices 的ADSP -BF561,处理块具有两个 Blackfin®核心。它被称为微信号架构 (MSA),被描述为一种正交的类似 RISC 的指令集,在单指令集架构中提供 SIMD(单指令多数据)功能和多媒体功能。每个相同的内核都具有两个 16 位乘法器、两个 40 位累加器、两个 40-ALU、四个 8 位视频 ALU 和一个 40 位移位器,具有独立的 L1 缓存,但共享 L2 缓存和统一的内存架构。
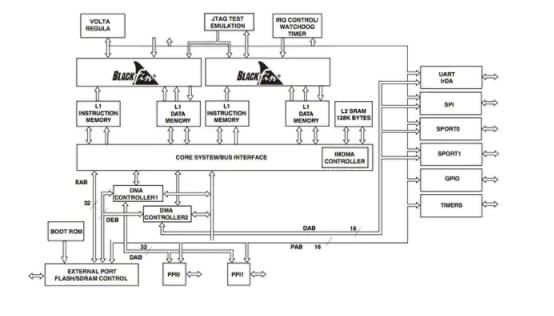
图 2:Analog Devices 的 Blackfin 内核是其 ADSP-BF561 的核心。
多媒体处理是一项要求很高的应用,并且越来越多地在嵌入式层面得到解决,因此出现了 ADSP-BF561 等设备,以及最近飞思卡尔的i.MX6 系列。该系列可扩展设备具有一个通用平台,支持单核、双核和四核变体,采用主要兼容引脚和软件的格式,基于 ARM ® Cortex™-A9 内核。内核运行频率高达 1.2 GHz,支持 ARMv7、NEON、VFPv3 和 Trustzone。
这些设备被飞思卡尔归类为应用处理器,主要针对汽车(信息娱乐)和消费(智能设备)市场,但已迅速被 SBC(单板计算机)供应商采用,作为更成熟的 x86 架构的替代品,这要归功于它们的低功耗和高性能凭据,以及运行包括 Linux 在内的一系列操作系统的能力。它们从单核到四核的可扩展性使其成为 SBC 供应商的理想选择,因为它们能够使用通用平台提供一系列性能点。
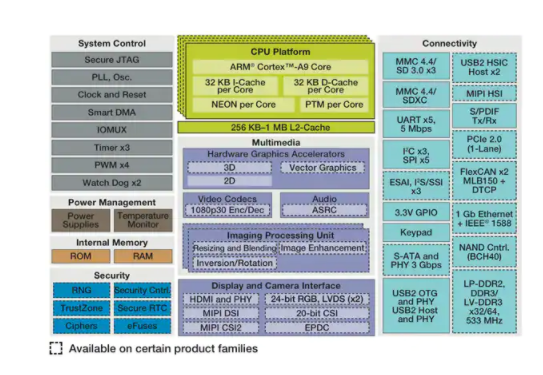
图 3:飞思卡尔的 i.MX6 系列应用处理器从单核设备扩展到四核设备。
非对称处理
虽然始终需要原始处理能力,但处理更多且通常不同的数据的需求也在增加。这催生了一类更新的多核微控制器,它将两个或更多具有特定但不同功能优势的内核结合在一起。这些设备通常被称为异构多核设备,并且通常具有两个具有非常不同配置文件的内核。
传统形式的非对称多核处理来自NXP 的 LPC43xx 系列。 它被描述为非对称 DSC,具有 ARM 的 Cortex-M4 和 Cortex-M0,它们使用处理器间通信协议进行通信。这允许 -M4 专注于数字信号处理任务,而 -M0 满足应用程序的控制方面。该概念允许将更简单的任务卸载到较小的核心上,从而最大化更强大核心的处理带宽,以进行计算密集型数字运算,这实际上是一般协同处理,特别是非对称处理的核心。
为允许处理器进行通信而实现的协议使用共享 SRAM 作为邮箱,其中一个处理器为另一个处理器引发中断以“检查”邮箱,当接收处理器引发中断作为响应时,该邮箱得到确认。除了传统的模拟和数字通用 I/O 之外,LPC43xx 还具有状态可配置的定时器子系统,而生产的每个设备也都有唯一的标识符。
大规模并行
虽然飞思卡尔的 i.MX6 系列(目前)扩展到四核设备,但下一步是沿着这条曲线进一步向大规模并行架构发展。在处理世界中,这并不少见。许多网络处理器在对称处理架构中具有相同内核的多个实例化。然而,在嵌入式领域,大规模并行微控制器并不常见,在许多工程师看来,可能仍然没有必要。
但是,它们有一个使用案例,特别是在工业自动化和机器人等分布式实时应用中。在这个领域,纯粹的处理能力无法始终克服系统级限制,例如通信骨干网的速度或需要硬实时做出反应。
在这些情况下,在应用点部署低成本但功能强大的微控制器是有意义的,因此它们能够更好地连接传感器和执行器,而不会延迟将大量数据传回中央处理器。
这描述了初创公司XMOS ®最近开发的架构的关键应用领域,该架构以大规模并行格式实现了大量相对简单的 MCU。xCORE _多核架构意味着它能够同时运行多个实时任务,因为它保持完全确定的时序,这是 XMOS 方法的一个关键优势。它通过组合具有共享资源但单独的寄存器文件的多个逻辑内核来实现这一点。每个逻辑核心都获得了由 xTIME 时序和同步技术控制的有保证的处理能力;正是这项技术赋予了 xCORE 独特的可预测性和实时响应能力。
逻辑核心排列在块中,每个块具有多达八个逻辑核心。然后这些瓦片在给定设备中以倍数排列,这意味着有 1、2 或 4 个瓦片可提供 4、6、8、10、12、16 和 32 个逻辑处理器内核的设备。这种方法的一个主要特点是它可以返回的低延迟;XMOS 表示,虽然其他 MCU 报告的响应时间为数十毫秒,但 xCORE 设备的响应时间是在 10 ns 的分辨率下测量的。这种嵌入式性能的另一个特点是它的灵活性。xCORE 设备不是“硬连线”外设,而是在软件中实现外设。这些软件定义的外围设备是使用 I/O 端口、逻辑处理器和 SRAM 的组合构建的,大多数外围设备只适合一个逻辑处理器。
结论
虽然已经很多,但多核 MCU 的可用性将会增加;ARM 的“big.LITTLE”技术以锁步格式将其两个 Cortex-A 类内核匹配在一起,这允许应用软件根据当前的性能需求在任一内核上运行,而不会错过时钟节拍。这可以延长大部分时间处于睡眠模式的便携式设备的电池寿命,而不会在需要时牺牲性能。
另一个为什么在单个设备中可以使用多个内核的例子是克服嵌入式闪存的速度限制。通过在两个小型低成本内核(例如 Cortex-M0)上以非对称方式划分任务,可以在使用低成本嵌入式存储器的同时访问内核的全部性能。实现嵌入式闪存的成本通常决定了当今 MCU 的成本,因此通过使用以互补方式工作的两个内核,可以有效地消除瓶颈。这种方法的一个例子来自东芝,它最近宣布了其首款基于 Cortex-M0 的多核 MCU。通过使用两个内核,嵌入式闪存的速度限制得到缓解。
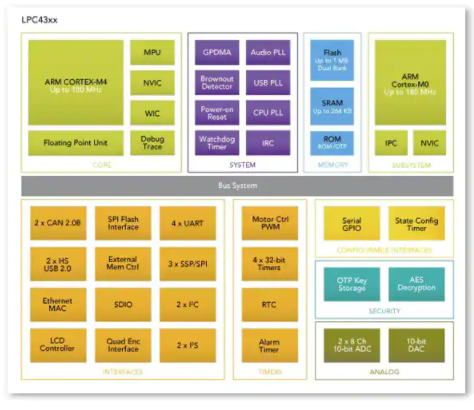
图 4:结合高端和低端处理器可以提供低功耗的性能。
随着现在 32 位 MCU 的量产价格低于 1 美元,很明显,对这种性能水平的需求已经存在,因此,与大多数应用领域一样,性能越高越好,特别是如果它带有很少或不增加系统功率。虽然“免费”性能可能过于令人期待,但与 MCU 中通常存在的许多其他资源相比,嵌入式内核现在的物理尺寸更小,所需的功率也更少。预计在不久的将来会出现更多的多核 MCU 似乎是合理的。
-
XLF210-512-TQ128:高性能多核微控制器的深度剖析2026-04-27 259
-
MAX32510:深度安全防护的嵌入式微控制器2026-03-26 290
-
如何使用NYASM微控制器应用程序2022-06-15 1418
-
使用ARM Cortex和STM32的嵌入式系统微控制器2021-08-03 1623
-
嵌入式Linux应用程序例程2021-07-30 1384
-
多核MCU可用于简化嵌入式设计 精选资料推荐2021-07-19 1432
-
如何使用LPC2000微控制器进行嵌入式软件结构的设计2019-02-25 1257
-
如何为嵌入式应用选择合适的微控制器2018-12-21 2556
-
基于ARM核的系列微控制器的嵌入式开发工具MDK2018-06-10 1628
-
多核微控制器提供新的嵌入式期权2017-07-20 989
-
时间触发嵌入式系统设计模式(使用8051微控制器开发可靠应用2008-10-28 3278
全部0条评论

快来发表一下你的评论吧 !
