

如何使用Python OpenCV进行面部标志检测
触控感测
描述
面部标志的检测是检测面部各个部位的过程,例如眉毛、眼睛、鼻子、嘴巴和下巴。有许多应用程序使用面部地标检测技术。
今天我们将使用相同的 OpenCV 和 Raspberry Pi 进行人脸标志检测。来自 dlib 库的预训练面部标志检测器模块将用于检测面部关键面部结构的位置,python OpenCV 将用于可视化检测到的面部部分。
所需组件
硬件组件
树莓派 3
Pi 相机模块
软件和在线服务
开放式CV
数据库
Python3
在继续这个 Raspberry Pi 3 面部地标检测之前,首先,我们需要在这个项目中安装 OpenCV、imutils、dlib、Numpy 和一些其他依赖项。OpenCV 在这里用于 数字图像处理。数字图像处理最常见的应用是 物体检测、 人脸识别和 人数统计。

要了解有关如何将 Pi 相机与 Raspberry Pi 连接的更多信息,请按照我们 之前的教程进行操作。
在树莓派中安装 OpenCV
这里 OpenCV 库将用于 Raspberry Pi QR 扫描仪。要安装 OpenCV,首先,更新 Raspberry Pi。
sudo apt-get 更新
然后安装在 Raspberry Pi 上安装 OpenCV 所需的依赖项。
sudo apt-get install libhdf5-dev -y sudo apt-get install libhdf5-serial-dev –y sudo apt-get install libatlas-base-dev –y sudo apt-get install libjasper-dev -y sudo apt-get install libqtgui4 –y sudo apt-get install libqt4-test –y
之后,使用以下命令在 Raspberry Pi 中安装 OpenCV。
pip3 安装 opencv-contrib-python==4.1.0.25
安装 imutils: imutils 用于执行一些必要的图像处理功能,例如平移、旋转、调整大小、骨架化,以及使用 OpenCV 更轻松地显示 Matplotlib 图像。因此,使用以下命令安装 imutils :
pip3 安装 imutils
安装 dlib:dlib是现代工具包,其中包含用于解决实际问题的机器学习算法和工具。使用以下命令安装 dlib。
pip3 安装 dlib
安装NumPy:NumPy是科学计算的核心库,包含强大的 n 维数组对象,提供集成 C、C++ 等的工具。
Pip3 安装 numpy
如何使用 dlib 检测面部部位
我们将使用 dlib 库的预训练面部标志检测器来检测映射到面部面部结构的 68 个 (x, y) 坐标的位置。dlib 面部地标预测器在iBUG 300-W 数据集上进行训练。下面给出了包含 68 个坐标索引的图像:

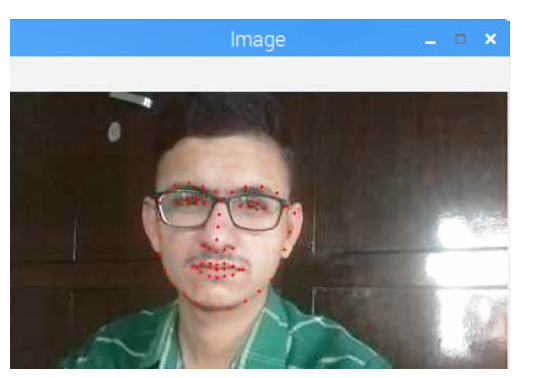
对 Raspberry Pi 进行面部地标检测编程
页面末尾给出了带有 dlib 的预训练面部标志检测器的面部部件识别的完整 Python 代码。在这里,我们将解释代码的一些重要部分,以便更好地理解。
因此,像往常一样,通过包含所有必需的库来启动代码。
从 imutils 导入 face_utils 将 numpy 导入为 np 导入参数解析 导入 imutils 导入 dlib 导入简历2 从 picamera.array 导入 PiRGBArray 从 picamera 导入 PiCamera
然后初始化相机对象并将分辨率设置为 (640, 480),帧速率设置为 30 fps
相机 = PiCamera() camera.resolution = (640, 480) 相机.帧率 = 30
现在在接下来的几行中,使用参数解析器提供面部标志预测器的路径。
ap = argparse.ArgumentParser()
ap.add_argument("-p", "--shape-predictor", required=True,
help="面部地标预测路径")
args = vars(ap.parse_args())
在接下来的几行中,初始化基于 HOG 的 dlib 的预训练面部检测器并加载预训练的面部特征预测器。
检测器 = dlib.get_frontal_face_detector() 预测器 = dlib.shape_predictor(args["shape_predictor"])
然后使用capture_continuous函数开始从 Raspberry Pi 相机捕获帧。
对于 camera.capture_continuous(rawCapture, format="bgr", use_video_port=True) 中的帧:
图像 = frame.array
cv2.imshow("帧", 图片)
键 = cv2.waitKey(1) & 0xFF
rawCapture.truncate(0)
使用键盘键“S”捕获特定帧。然后调整捕获的图像大小并将其转换为灰度。
如果键 == ord("s"):
图像 = imutils.resize(图像,宽度 = 400)
灰色 = cv2.cvtColor(图像,cv2.COLOR_BGR2GRAY)
使用 dlib 库的检测器功能来检测捕获图像中的人脸。
rects = 检测器(灰色,1)
拍摄执行人脸检测的照片,确定人脸标志,并将 68 个点转换为 NumPy 数组。分别循环每个面部区域。
枚举(rects)中的(i,rect):
形状 = 预测器(灰色,矩形)
形状 = face_utils.shape_to_np(形状)
然后,获取原始图像的副本并用于循环以在图像上绘制面部部分的名称。文本颜色将为红色,您可以通过更改 RGB 值将其更改为另一种颜色。
对于 face_utils.FACIAL_LANDMARKS_IDXS.items() 中的 (name, (i, j)):
克隆 = image.copy()
cv2.putText(克隆, 名称, (10, 30), cv2.FONT_HERSHEY_SIMPLEX,
0.7, (0, 0, 255), 2)
现在我们将遍历检测到的面部部位,并使用OpenCV绘图功能在这些面部部位上绘制圆圈。您可以关注此OpenCV 文档以获取有关绘图功能的更多信息
对于形状 [i:j] 中的 (x, y):
cv2.circle(克隆, (x, y), 1, (0, 0, 255), -1)
现在在接下来的几行中,我们将通过计算特定面部部分坐标的边界框来将每个面部部分提取为单独的图像。提取的图像将被调整为 250 像素。
(x, y, w, h) = cv2.boundingRect(np.array([shape[i:j]])) 投资回报率 = 图像[y:y + h, x:x + w] roi = imutils.resize(roi, width=250, inter=cv2.INTER_CUBIC)
现在在代码的最后几行中,显示面部部位及其名称和该部位的单独图像。使用 ESC 键更改面部区域。
cv2.imshow("ROI", roi)
cv2.imshow("图像", 克隆)
cv2.waitKey(0)
测试面部识别器
要测试项目,请创建一个目录并使用以下命令导航到该目录:
mkdir face-part-detector cd face-part-detector
现在从此链接下载 shape_predictor_68_face_landmarks.dat 文件,然后将shape_predictor_68_face_landmarks.dat文件提取并复制到该库中,然后打开一个名为detect.py的新文件并粘贴下面给出的代码。
现在使用以下命令启动 python 代码:
python3 detect.py --shape-predictor shape_predictor_68_face_landmarks.dat
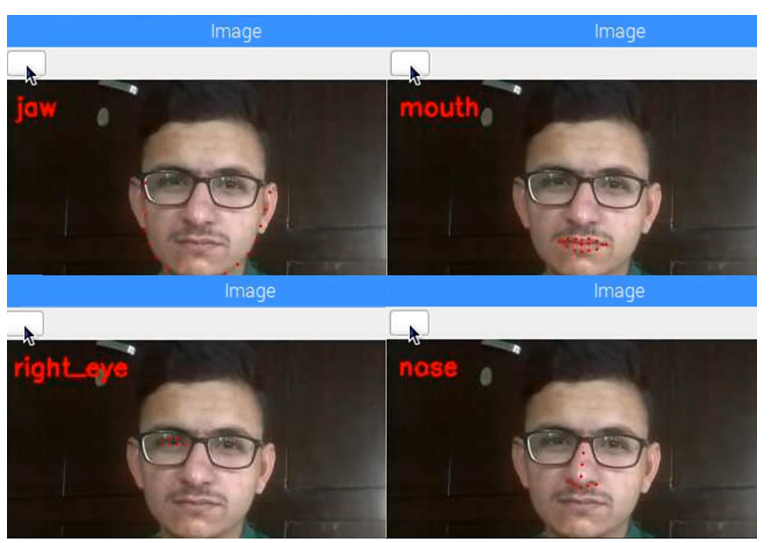
您将看到一个窗口,显示您的相机的实时视图。然后按“S”键从实时流中选择一帧。您会在嘴巴区域看到红点。使用 ESC 键查看其他面部零件。
从 imutils 导入 face_utils
将 numpy 导入为 np
导入参数解析
导入 imutils
导入 dlib
导入简历2
从 picamera.array 导入 PiRGBArray
从 picamera 导入 PiCamera
从 PIL 导入图像
相机 = PiCamera()
camera.resolution = (640, 480)
相机.帧率 = 30
rawCapture = PiRGBArray(相机,尺寸=(640,480))
# 构造参数解析器并解析参数
ap = argparse.ArgumentParser()
ap.add_argument("-p", "--shape-predictor", required=True,
help="面部地标预测路径")
args = vars(ap.parse_args())
检测器 = dlib.get_frontal_face_detector()
预测器 = dlib.shape_predictor(args["shape_predictor"])
对于 camera.capture_continuous(rawCapture, format="bgr", use_video_port=True) 中的帧:
图像 = frame.array
cv2.imshow("帧", 图片)
键 = cv2.waitKey(1) & 0xFF
rawCapture.truncate(0)
如果键 == ord("s"):
图像 = imutils.resize(图像,宽度 = 300)
灰色 = cv2.cvtColor(图像,cv2.COLOR_BGR2GRAY)
rects = 检测器(灰色,1)
# 循环人脸检测
枚举(rects)中的(i,rect):
# 确定面部区域的面部标志
形状 = 预测器(灰色,矩形)
形状 = face_utils.shape_to_np(形状)
# 分别循环面部部分
对于 face_utils.FACIAL_LANDMARKS_IDXS.items() 中的 (name, (i, j)):
# 在图像上显示人脸部分的名称
克隆 = image.copy()
cv2.putText(克隆, 名称, (10, 30), cv2.FONT_HERSHEY_SIMPLEX,
0.7, (0, 0, 255), 2)
# 在特定的面部部分绘制圆圈
对于形状 [i:j] 中的 (x, y):
cv2.circle(克隆, (x, y), 1, (0, 0, 255), -1)
# 提取人脸区域的ROI作为单独的图像
(x, y, w, h) = cv2.boundingRect(np.array([shape[i:j]]))
投资回报率 = 图像[y:y + h, x:x + w]
roi = imutils.resize(roi, width=250, inter=cv2.INTER_CUBIC)
# 显示特定的面部部分
cv2.imshow("ROI", roi)
cv2.imshow("图像", 克隆)
cv2.waitKey(0)
# 可视化所有面部地标
对于 (x, y) 的形状:
cv2.circle(图像, (x, y), 1, (0, 0, 255), -1)
cv2.imshow("图像",图像)
cv2.waitKey(0)
-
使用OpenVINO™模型的OpenCV进行人脸检测,检测到多张人脸时,伺服电机和步入器电机都发生移动是为什么?2025-03-07 599
-
如何利用NuMicro® M55M1 ML MCU进行面部标志检测应用?2025-09-05 409
-
没有专利的opencv-python 版本2025-12-13 732
-
Python中使用OpenCV2026-07-21 339
-
Python—OpenCV入门教程_python opencv2026-07-22 126
-
如何使用Python中的OpenCV模块检测颜色2023-02-09 1870
-
如何使用OpenCV、Python和深度学习在图像和视频中实现面部识别?2018-07-17 8994
-
使用Python和OpenCV实现行人检测的资料合集免费下载2020-06-01 1464
-
西门子PLC的内部标志与寄存器2021-04-04 19230
-
Linux Debian与Python、Flask和OpenCV识别面部2022-08-24 1014
-
使用opencv和python进行智能火灾检测2022-11-02 827
-
使用Xbox Kinect和OpenCV进行面部识别2023-07-04 713
-
opencv-python和opencv一样吗2024-07-16 3390
-
如何使用树莓派+OpenCV实现姿态估计和面部特征点追踪?2025-08-13 1754
-
如何使用树莓派与OpenCV实现面部和运动追踪的云台系统?2025-08-14 3253
全部0条评论

快来发表一下你的评论吧 !
