

多平面图像的单视图合成
电子说
描述
Single-View View Synthesis with Multiplane Images
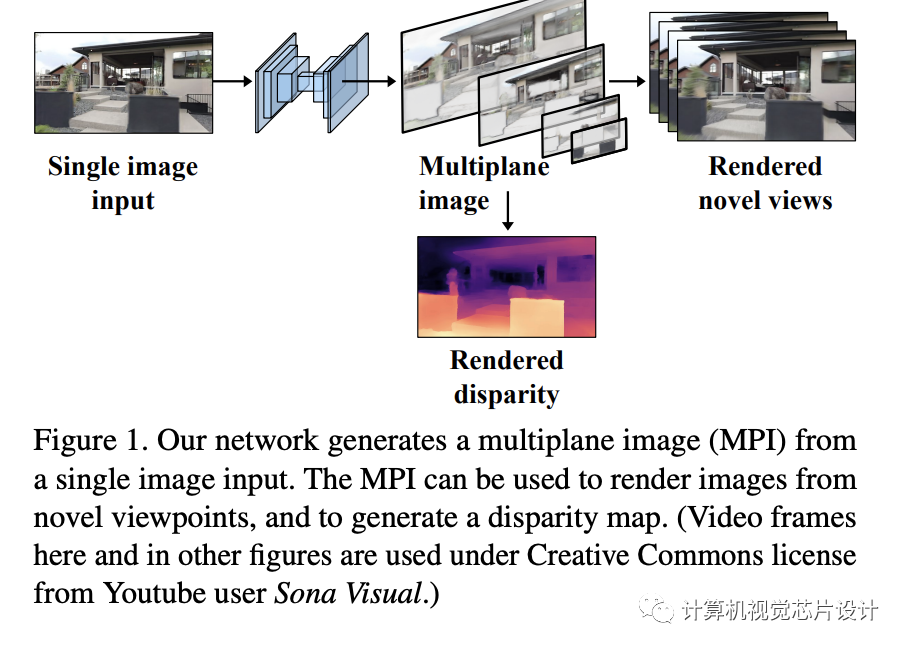
最近在视图合成方面的一系列工作使用深度学习来生成多平面图像——一种以相机为中心的分层 3D 表示——给定两个或多个已知视点的输入图像。我们将此表示应用于单视图视图合成,这是一个更具挑战性但可能具有更广泛应用的问题。我们的方法直接从单个图像输入中学习预测多平面图像,并且我们引入了用于监督的尺度不变视图合成,使我们能够在在线视频上进行训练。我们展示了这种方法适用于几个不同的数据集,它还生成了合理的深度图,并且它学会了在背景层中填充前景对象边缘后面的内容。
ASSET: Autoregressive Semantic Scene Editing with Transformers atHigh Resolutions

我们提出了资产,一种神经架构,用于根据用户对其语义分割图的编辑自动修改输入的高分辨率图像。我们的架构基于具有新颖注意力机制的转换器。我们的关键思想是在高分辨率下稀疏变换器的注意力矩阵,由在较低图像分辨率下提取的密集注意力引导。虽然以前的注意力机制在处理高分辨率图像时计算成本太高,或者在阻碍远程交互的特定图像区域内受到过度限制,但我们新的注意力机制在计算上既高效又有效。我们的稀疏注意力机制能够捕捉远程交互和上下文,从而合成场景中有趣的现象,例如景观到水面上的反射或与景观的其余部分一致的论坛,这些是以前的卷积网络无法可靠生成的和变压器方法。我们提供定性和定量结果,以及用户研究,证明我们方法的有效性。
我们的代码和数据集可在我们的项目页面上找到:https://github.com/DifanLiu/ASSET
审核编辑 :李倩
-
电气平面图设计说明2023-09-18 3790
-
DeepMind人工智能可以将平面图像生成3D图像2018-07-03 2443
-
基于多视图特征投影与MFPSDL图像分类方法2017-11-30 1185
-
LabVIEW如何能够将三维平面图控件输出的图像从word 和 excel打印输出2015-11-22 3886
-
用cad绘制的一份室内平面图操作步骤2015-11-12 681
-
综合布线平面图,需要的拿去、2014-03-11 5589
-
如何将平面图像转换成立体图像的方法研究2010-06-23 1151
-
基于平面图像实现三维仿真场景的技术方法研究2009-09-15 934
-
绘制平面图形2009-07-31 4504
-
房屋底层平面图2009-06-10 9862
-
防雷接地平面图2008-10-13 861
-
全厂防雷平面图2008-10-08 657
全部0条评论

快来发表一下你的评论吧 !
