

浅谈微控制器的音频编码技术
音视频及家电
描述
将语音和声音生成添加到产品中可以大大提高产品的可用性和适销性,并且不需要添加单独的数字信号处理器 (DSP) 或专门的音频处理器来实现。微控制器 (MCU) 供应商已经实现了 DSP 扩展,为曾经被认为过于复杂而无法在专用 DSP 平台上实现的算法带来实时解码。
此外,音频处理提供了大量的折衷方案,设计人员可以利用这些折衷方案在相对低速的 8 位 MCU 上播放复杂的音频。例如,可以在相对简单的 MCU(如Microchip Technology )上实现标准自适应差分脉冲编码调制 (ADPCM) 算法的简单版本 PIC16无需任何 DSP 扩展。
旨在减少存储大小的音频编码技术分为两类。第一种方法称为波形编码,它使用波形本身的已知属性。波形编码的优点是它试图在不知道信号是如何创建的情况下对信号进行编码。这允许编解码器应用于不同形式的音频,即使该算法可能是为语音而设计的。
面向语音的波形编解码器通常利用以下观察结果:语音信号取小值而不是大值的概率更高。因此,语音处理器可以通过量化具有更精细步长的较小样本和具有粗步长的大样本来降低比特率。通过使用语音的一个固有特性可以进一步降低比特率:连续语音样本之间的高相关性。
可以对连续样本之间的差异进行编码,而不是对语音信号本身进行编码。这种方法是一种相对简单的方法,它在每个样本上重复,从一个样本到下一个样本的开销很小。ADPCM 是使用这种技术的波形算法的一个例子。
另一种压缩或编码形式是使用创建音频信号方式的模型。这可以显着提高压缩率,而不会对重构后的音频质量产生负面影响。例如,通常用于蜂窝电话网络的语音编解码器使用声道的简化模型。
语音通常在较短的时间间隔内保持相对恒定,并且可以使用一组参数来定义如何重建短时间的语音:通常是音调和幅度。然后可以将这些参数而不是编码样本存储或传输到接收器。该技术需要对输入语音信号进行大量处理,并需要内存来存储和分析语音区间。这种类型的处理器(称为声码器或混合编码器)的示例是执行线性预测编码 (LPC) 或码激励线性预测编码 (CELP) 的处理器。
GSM 电话标准使用 CELP 将实时语音压缩为需要小于 10 kb/s 的带宽的流。对于非电话用途,Speex 编解码器提供了 CELP 算法的有效实现,并可作为开源代码使用。许多 MCU 库(例如 Microchip Technology 为 PIC32MX 系列开发的库)都实现了 Speex 编解码器。
MPEG2 第 3 层 (MP3) 音频编解码器使用人类听觉模型而不是声音系统来确定如何最好地压缩音频流。当今许多领先的音频编解码器都是有损的感知编解码器,其工作原理是大脑无法听到某些被其他更响亮的信号“掩盖”的音频信号。因此,它们不值得编码,从而更容易以较低比特率的数据流渲染音频。
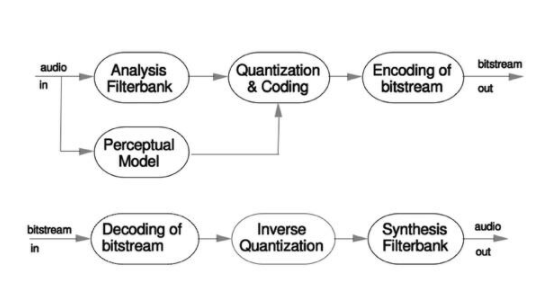
图 1:感知编解码器的框图。(来源:弗劳恩霍夫)
其他高质量音频编解码器使用波形形成的方法,这些是典型的无损算法,例如免费无损音频编解码器 (FLAC),其开发是为了解决为通用数据流开发的算法对音频数据的问题。大多数传统的面向文本的数据压缩技术,例如 ZIP 和 GZip,都依赖于这样一种理解,即文本信息中存在高度冗余,但流中的数据值之间几乎没有相关性。压缩器构建常用数据字符的字典,然后使用更短的位序列进行识别。例如,一个空格字符可能占用三位;一个 ‘x’ 五个或六个,很少使用超过八位的符号。这是霍夫曼编码的核心。然而,
例如,对文本文件压缩器中使用的 Huffman 编码的改进是 LZW 算法,它超越了单个符号到短序列——例如,“anti”在文本中比“atni”更常见。类似地,一些机器代码指令和地址范围在软件中比其他的更常见。那些经常重复的序列在压缩器构建的字典中被赋予最短的符号。非常罕见的序列的编码版本可能会比源中的对应版本更长。
在音频中,单个样本通常相互之间具有很强的相关性,但序列并不完全重复。正如我们在 ADPCM 中看到的那样,连续样本的值通常相似,但至关重要的是,它们并不相同。这破坏了为文本或机器代码设计的压缩系统有效编码样本流的能力。FLAC 算法通过使用类似于 ADPCM 所采用的线性预测作为编码样本数据的第一阶段来解决这个问题。这留下了一系列不相关的值——称为残差或误差信号——可以进行熵编码。FLAC 使用 Golomb-Rice 方法而不是 Huffman 编码——这一系列代码适用于小值比大值更可能出现的情况。
通常,Golomb 代码使用可调参数 M 将值分为两部分。第一个是除以M;第二个是余数。第一部分存储为一元代码——其中数字 n 由 n-1 个“0”数字表示,后跟终止“1”,反之亦然。这允许更密集地打包较小的值。这种编码方案的 Rice 变体使 M 成为 2 的倍数,以提高微处理器的效率——例如,除法可以实现为简单的移位操作。余数使用截断二进制编码进行编码,这是另一种针对小残差优化的方案。
对于嵌入式系统,MP3 4当需要高质量音频但存储空间非常宝贵时,这将是最常见的方案。该系统的核心是感知模型,它基于对大脑处理音频信息方式的多年研究。一般来说,一个频率的响亮声音会掩盖附近频率的安静声音。它们不一定被完全屏蔽,但这意味着可以以较低的分辨率对具有安静信号的频带进行编码,并将更多的比特分配给具有较大信号的频带。
因此,第一阶段是使用滤波器组将传入的时域信号分成一组窄频率范围。然后对其进行分析以确定每个频段的掩蔽阈值,并以此确定该频段的允许噪声水平。允许的噪声级别将决定可以将多少位应用于该频带 - 位越少,重建音频时将产生的量化噪声量越大。
音频本身使用改进的离散余弦变换 (MDCT) 进行处理,以将时域信号转换为频域信息。使用来自感知模型的信息,算法可以继续进行量化。所选择的技术是幂律量化器,它以较低的分辨率对较大的值进行编码。这执行了一定程度的噪声整形,提高了较小信号的准确性。
然后使用霍夫曼编码对量化级别进行编码——这部分算法是无损的,与使用霍夫曼编码的其他数据压缩一样。即使在幂律量化和霍夫曼编码之后,输出数据流的速率也可能高于为编码器设置的速率。需要提高量化级别来生成适合 MP3 的 128 kbit/s、96 kbit/s 或其他典型设置的流。
为了提供所需的输出速率,量化器通常使用两个嵌套的迭代循环来实现。内部循环是速率循环,修改整体编码器速率,直到输出流处于足够低的比特率。这是通过应用更大的量化步长来实现的。外环使用感知模型提供的掩蔽阈值对量化噪声进行整形。此外部循环要求的每项更改都需要进一步通过内部循环,以确保输出比特率低于其阈值。外循环继续进行,直到每个频带的噪声低于掩蔽阈值。由于迭代次数较多,编码过程很难保证实时运行。
MP3 采用了其他更复杂的方案,例如为 Ogg 格式开发的 Vorbis 开源编解码器5,以及用于 MP3 标准后续版本的 AAC 编解码器。然而,它们使用相同的广泛方案,只是简单地提高了光谱分辨率等因素。例如,AAC 使用的 MDCT 算法使用 1024 条频率线,而不是 MP3 的 576 条。
由于不需要运行感知模型和两个限速循环,因此从这些有损格式进行解码的计算强度远低于编码——允许在各种嵌入式处理器上实现。此外,MP3 标准的设计者努力减少其包含的规范元素的数量。只有数据表示和解码器被视为规范,即使那样,解码器也不是以精确位的方式指定的,而是以公式的形式指定的,该公式具有可用于检查实现与使用双精度算术执行的实现的测试。这使得使用定点或浮点算术实现解码器成为可能。已经编写了完全兼容的解码器,它们使用短至 20 位的定点字。
MP3 解码器完全在大量 32 位 MCU 的能力范围内,例如采用 ARM7 或 Cortex-M3 处理器内核的那些。此外,对于 ARM 等流行架构,提供了可简化 MP3 实现的参考代码以及 Vorbis 和 FLAC 6转码器的完整源代码。
在过去的 20 年中,研究人员开发了高效的方法来执行计算密集度最高的步骤 - DCT - 如果没有快速 32 位乘法指令,则使用转换来减少所需的加法总数。例如,Helix 实现在 ARM7 内核上运行时,可以支持 44.1 kHz 的采样率,以在 26 MHz 的时钟速率下以 128 kbit/s 的输入流实现立体声输出。
如果有更高性能的 DSP 指令可用,则可以优化音频处理,为系统功能留出更多空间。例如,意法半导体 STM32系列 MCU 中使用的 Cortex-M3 内核具有 32 位乘法和累加指令,非常适合处理音频数据。它还执行分支推测以提高需要分支的循环中的性能。例如,用于生成余弦值的许多查找表算法使用少量分支。STM32F10x
_附带一个 DSP 库,除了转码外,它还实现了音频处理中使用的许多功能。例如,该库包括用于执行有限和无限脉冲响应滤波的例程,这些滤波通常用于操纵音频流并去除或增强某些频带。FFT 函数可用于实时音频分析。
其他架构也非常适合音频压缩和解压缩算法。飞思卡尔 ColdFire 系列MCU 为音频处理提供了成本优化的解决方案。MCF5249等设备实现增强型乘法累加单元,该单元非常适合运行音频滤波器和相关算法,并包括用于与 ADC 和 DAC 通信的 I²S 端口。MCF5249 针对记录和播放系统进行了优化,因为它包括与闪存和基于 IDE 的硬盘驱动器的直接接口。
Atmel AT32UC3A3支持高达 50 kHz 的音频采样率,并在其已经高效的指令流水线中添加了一组 DSP 指令。它可以通过 I²S 总线与音频 ADC 通信,甚至包括自己的比特流 DAC,使其成为音频播放设备的理想平台。
DSP 扩展包括饱和算术,而不是像传统 MCU 算术那样使大值溢出寄存器并强制其回绕,而是简单地允许值达到最大值。这提供了一个与音频过滤器更兼容的结果,并且避免了过滤循环中需要分支来检查溢出,从而大大提高了性能。DSP 扩展还添加了多种乘法指令。
Microchip PIC32MX基于 MIPS RISC 架构,提供处理 FLAC、MP3 和其他音频编解码器所需的核心性能水平。该公司还为多种算法提供音频库,包括 ADPCM 转码和 Speex。
ADI公司的ADSP-BF527在信号处理功能方面更进了一步,提供了广泛的 DSP 指令,实现了完整的 MCU 功能,以帮助实现高级音频应用,例如可能需要一系列高级语音和音频编解码器的 IP 语音电话以及用于多声道音频输入和输出。多达 12 个直接内存访问 (DMA) 可从处理器内核卸载数据传输开销,从而为 DSP 和控制操作提供更多空间。
音频现在是许多嵌入式系统的关键部分,而不仅仅是音乐播放器和语音记录器。可用的编解码器和编码技术使优化特定应用程序的存储和播放成为可能。Digi-Key 等分销商提供的各种具有音频功能的 MCU 为设计人员提供了选择最适合目标系统的设备的机会。
概括
本文概述了当今使用的关键音频压缩和编码标准,并描述了许多适合运行它们的 MCU 架构和实现。
-
电梯的基础原理:微控制器jf_10480160 2022-12-14
-
微控制器的发展怎么样2019-06-25 2257
-
语音编码和解码免费Speex音频编解码器的微控制器2020-05-29 2642
-
如何使用STM32微控制器的DAC生成音频和波形?2021-11-19 1995
-
32位微控制器设计的单芯片DRM数字音频编解码器技术2011-02-12 3147
-
使用STM32F0xx系列微控制器的DAC模块实现音频和生产波形2016-05-18 1456
-
基于ST公司的STM32微控制器系列在音频方面的应用源代码2016-05-20 725
-
微控制器的音频编码与压缩2017-07-17 1173
-
如何选择可用于音频捕获与回放的微控制器2019-02-13 3512
-
什么是微控制器?如何编程微控制器?2020-08-21 13364
-
浅谈32位微控制器概念及作用2020-12-31 7478
-
微控制器布局2022-08-15 2431
-
浅谈嵌入式设计的低功耗微控制器2022-08-17 1235
-
CS201音频播放器微控制器英文手册2022-09-08 720
-
浅谈如何评估TI C2000系列微控制器程序的堆栈使用情况2022-10-31 936
全部0条评论

快来发表一下你的评论吧 !
