

使用NVIDIA Merlin库构建基于会话的建议
描述
推荐系统可以帮助您发现新产品并做出明智的决策。然而,在许多依赖于推荐的领域,如电子商务、新闻和流媒体服务,用户可能无法跟踪,或者根据当时的需求,用户的口味可能会迅速变化。
基于会话的推荐系统是顺序推荐的一个子领域,最近很受欢迎,因为它们可以在任何给定的时间点根据用户的情况和偏好推荐项目。在这些领域中,捕捉用户对项目的短期或上下文偏好很有帮助。
在本文中,我们将介绍基于会话的推荐任务,该任务由 NVIDIA Merlin 平台的 Transformers4Rec 库支持。然后,我们展示了使用 Transformers4Rec 在几行代码中创建基于会话的推荐模型是多么容易,最后,我们展示了使用 NVIDIA Merlin 库的端到端基于会话的推荐管道。
Transformers4Rec 库功能
NVIDIA Merlin 团队于 ACM RecSys’21 发布,通过利用最先进的 Transformers 体系结构,为顺序和基于会话的推荐任务设计并公开了 NVIDIA Merlin Transformers4Rec 库。该库可由研究人员扩展,对从业者来说很简单,在工业部署中又快速又可靠。
它利用了 拥抱面( HF )变压器 库中的 SOTA NLP 体系结构,可以在 RecSys 域中快速试验许多不同的 transformer 体系结构和预训练方法。
Transformers4Rec 还帮助数据科学家、行业从业者和院士构建推荐系统,该系统可以利用同一会话中过去用户交互的短序列,然后动态建议用户可能感兴趣的下一个项目。
以下是 Transformers4Rec 库的一些亮点:
灵活性和效率: 构建块模块化,与 vanilla PyTorc h 模块和 TF Keras 层兼容。您可以创建自定义体系结构,例如,使用多个塔、多个头/任务和损耗。 Transformers4Rec 支持多个输入功能,并提供可配置的构建块,这些构建块可以轻松组合用于定制体系结构。
与集成 HuggingFace Transformers : 使用最前沿的 NLP 研究,并为 RecSys 社区提供最先进的 transformer 体系结构,用于顺序和基于会话的推荐任务。
支持多种输入功能: Transformers4Rec 支持使用任何类型的顺序表格数据的高频变压器。
与无缝集成 NVTabular 用于预处理和特征工程。
Production-ready: 导出经过培训的模型以用于 NVIDIA Triton 推理服务器 在单个管道中进行在线特征预处理和模型推理。
开发您自己的基于会话的推荐模型
只需几行代码,就可以基于 SOTA transformer 体系结构构建基于会话的模型。下面的示例显示了如何将强大的 XLNet transformer 体系结构用于下一个项目预测任务。
正如您可能注意到的,使用 PyTorch 和 TensorFlow 构建基于会话的模型的代码非常相似,只有几个不同之处。下面的代码示例使用 Transformers4Rec API 使用 PyTorch 和 TensorFlow 构建基于 XLNET 的推荐模型:
#from transformers4rec import torch as tr
from transformers4rec import tf as tr
from merlin_standard_lib import Schema schema = Schema().from_proto_text("")
max_sequence_length, d_model = 20, 320
# Define input module to process tabular input-features and to prepare masked inputs
input_module = tr.TabularSequenceFeatures.from_schema( schema, max_sequence_length=max_sequence_length, continuous_projection=64, aggregation="concat", d_output=d_model, masking="clm",
) # Define Next item prediction-task prediction_task = tr.NextItemPredictionTask(hf_format=True,weight_tying=True) # Define the config of the XLNet architecture
transformer_config = tr.XLNetConfig.build( d_model=d_model, n_head=8, n_layer=2,total_seq_length=max_sequence_length
)
# Get the PyT model
model = transformer_config.to_torch_model(input_module, prediction_task)
# Get the TF model
#model = transformer_config.to_tf_model(input_module, prediction_task)
为了证明该库的实用性和 transformer 体系结构在用户会话的下一次点击预测中的适用性, NVIDIA Merlin 团队使用 Transformers4Rec 赢得了两次基于会话的推荐比赛:
2021 WSDM WebTour 研讨会挑战赛 通过预订。 com ( NVIDIA solution )
Coveo 2021 SIGIR 电子商务研讨会数据挑战赛 ( NVIDIA solution )
使用 NVIDIA Merlin 构建端到端、基于会话的推荐管道的步骤
图 3 显示了使用 NVIDIA Merlin Transformers4Rec 的基于会话的推荐管道的端到端管道。
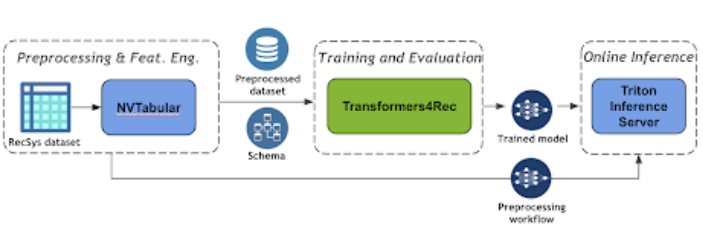
图 3 :基于端到端会话的推荐管道
NVTabular 是一个用于表格数据的功能工程和预处理库,旨在快速、轻松地操作用于培训大规模推荐系统的 TB 级数据集。它提供了一个高级抽象,以简化代码,并使用 RAPIDS cuDF library。
NVTabular 支持深度学习 (DL) 模型所需的不同特征工程转换,例如分类编码和数值特征归一化。它还支持特征工程和生成顺序特征。有关支持的功能的更多信息,请参见此处。
在下面的代码示例中,您可以很容易地看到如何创建一个 NVTabular 预处理工作流,以便在会话级别对交互进行分组,并按时间对交互进行排序。最后,您将获得一个已处理的数据集,其中每一行表示一个用户会话以及该会话的相应顺序特征。
import nvtabular as nvt
# Define Groupby Operator
features = ['session_id', 'item_id', 'timestamp', 'category']
groupby_features = features >> nvt.ops.Groupby( groupby_cols=["session_id"], sort_cols=["timestamp"], aggs={ 'item_id': ["list", "count"], 'category': ["list"], 'timestamp': ["first"], }, name_sep="-") # create dataset object
dataset = nvt.Dataset(interactions_df)
workflow = nvt.Workflow(groupby_features)
# Apply the preprocessing workflow on the dataset sessions_gdf = workflow.transform(dataset).compute()
使用 Triton 推理服务器 简化人工智能模型在生产中的大规模部署。 Triton 推理服务器使您能够部署和服务您的模型进行推理。它支持许多不同的机器学习框架,例如 TensorFlow 和 Pytork 。
机器学习( ML )管道的最后一步是将 ETL 工作流和经过训练的模型部署到产品中进行推理。在生产设置中,您希望像在培训( ETL )期间那样转换输入数据。例如,在使用 ML / DL 模型进行预测之前,应该对连续特征使用相同的规范化统计信息,并使用相同的映射将类别编码为连续 ID 。
幸运的是, NVIDIA Merlin 框架有一个集成机制,可以将预处理工作流(用 NVTABLAR 建模)和 PyTorch 或 TensorFlow 模型作为 NVIDIA Triton 推理的集成模型进行部署。集成模型保证对原始输入应用相同的转换。
下面的代码示例展示了使用 NVIDIA Merlin 推理 API 函数创建集成配置文件,然后将模型提供给 TIS 是多么容易。
import tritonhttpclient
import nvtabular as nvt workflow = nvt.Workflow.load("") from nvtabular.inference.triton import export_tensorflow_ensemble as export_ensemble
#from nvtabular.inference.triton import export_pytorch_ensemble as export_ensemble
export_ensemble( model, workflow, name="", model_path="", label_columns=["
只需几行代码,就可以为 NVIDIA PyTorch 推理服务器提供 NVTabular 工作流、经过培训的 Triton 或 TensorFlow 模型以及集成模型,以便执行端到端的模型部署。 使用 NVIDIA Merlin 推理 API ,您可以将原始数据集作为请求(查询)发送到服务器,然后从服务器获取预测结果。
本质上, NVIDIA Merlin 推理 API 使用 NVIDIA Triton ensembling 特性创建模型管道。 NVIDIA Triton ensemble 表示一个或多个模型的管道以及这些模型之间输入和输出张量的连接。
结论
在这篇文章中,我们向您介绍了 NVIDIA Merlin Transformers4Rec ,这是一个用于顺序和基于会话的推荐任务的库,它与 NVIDIA NVTabular 和 NVIDIA Triton 推理服务器无缝集成,为此类任务构建端到端的 ML 管道。
关于作者
Ronay Ak 是 NVIDIA RAPIDS 团队的数据科学家。
GabrielMoreira 是 NVIDIA ( NVIDIA ) Merlin 团队的高级研究员,致力于推荐系统的深度学习,这是他的博士学位的重点。他曾担任首席数据科学家和软件工程师多年。
审核编辑:郭婷
-
无法在GRID K1上启动超过2个编码会话2018-09-11 3251
-
NVIDIA Grid K2会话冻结2018-09-14 2444
-
XenDesktop 7.6和GRID会话被冻结2018-09-21 1666
-
Nvidia M6网卡能否通过会话桌面将高清视频用于最终用户瘦客户端设备?2018-09-27 2609
-
为什么nvidia不建议将m10用于SolidWorks2018-10-09 7189
-
思科开源AI会话平台MindMeld2019-05-14 3209
-
NVIDIA GPU再创壮举,距真正会话AI又进一步!2019-08-15 6029
-
NVIDIA正式发布Merlin 1.0版本2022-03-23 2444
-
如何使用NVIDIA Merlin推荐系统框架实现嵌入优化2022-04-02 2716
-
NVIDIA Merlin可使用开源规范构建块开发和优化推荐系统2022-04-15 1524
-
NVIDIA Merlin GPU推荐系统加速大模型训练和推理2022-07-05 2242
-
NVIDIA 人工智能开讲 | Merlin HugeCTR 与 DeepRec 的深度合作以及最新技术进展2022-11-21 1243
-
NVIDIA 人工智能开讲 | Merlin 与 DeepRec 的深度合作以及最新技术进展2022-11-22 921
-
如何搭建高效推荐系统?用Milvus和NVIDIA Merlin搭建高效推荐系统2023-11-01 2179
-
NVIDIA Merlin 助力陌陌推荐业务实现高性能训练优化2023-11-09 982
全部0条评论

快来发表一下你的评论吧 !
