

改进企业IT欺诈预防
描述
任何商业或行业,从零售、医疗保健到金融服务,都会受到欺诈的影响。欺诈的成本可能是惊人的。欺诈损失每 1 美元 减轻金融公司约 4 美元的成本 。 2018 年至 2023 年间,在线卖家将 网上支付欺诈损失 1300 亿美元 。
通过使用 AI 和大数据分析,企业可以实时有效地防止欺诈企图。
这篇文章讨论了需要考虑的基础设施因素,例如性能、硬件和用于实施欺诈预防策略的人工智能软件的类型。
交易前和交易后欺诈检测
在讨论欺诈检测之前,让我们先明确预防和检测之间的区别。欺诈预防描述了管理和消除欺诈的总体努力。欺诈检测只是识别欺诈活动的能力。
欺诈检测有两种方法,这两种方法都是综合欺诈预防战略所必需的。
Pre-transaction detection: 在交易完成之前检测并阻止试图欺诈的交易。当在事务之前检测到异常数据或行为时,事务被阻止。
Post-transaction detection: 根据数据分析或交易后输入,在交易完成后识别欺诈交易。然后是损害缓解。
理想的方法是在未遂欺诈发生之前检测并阻止其发生。当交易后发现欺诈时,唯一的办法是评估损害,通知相关方,并努力从欺诈损害中恢复。
尽管欺诈永远无法完全消除,但在制定欺诈风险管理计划时,交易前和交易后的欺诈工作都很重要。
开发有效反欺诈解决方案的最佳企业 IT 实践
如果欺诈预防像速溶早餐麦片一样简单,你只需加热水搅拌即可。有效预防欺诈只需要一个标准服务器和软件。对的不完全是这样。
防欺诈软件显然至关重要,但仅选择任何硬件和软件组合并不能确保成功。尽管欺诈预防“解决方案”在企业中广泛存在,但欺诈仍在不断增加,在这一过程中造成了财务损失。
企业 IT 必须确保多个基础架构元素到位:
人工智能驱动软件:由于传统的静态智能不如人工智能的动态智能有效,因此存在人工智能驱动的欺诈解决方案的趋势。为了防止复杂的欺诈企图,软件必须学习。因此,人工智能必须处于核心地位。
加速性能 :实时人工智能驱动的欺诈检测需要尽可能高的性能。延迟会影响客户体验。通过性能,可以实时评估更多欺诈因素,从而实现更准确的欺诈检测。
可用性和规模 :需要一个高可用的扩展架构来支持 24-7 天的数据接收和预防。
如果没有这三个组成部分,效率会降低,这可能会给企业和客户带来更大的欺诈损失。
人工智能驱动的软件
人工智能驱动的软件已经在企业中普及。通过人工智能训练的欺诈预防模型,可以基于模型训练迭代评估和调整检测真实欺诈的准确性。培训后,预防解决方案作为推断应用程序运行,以评估和阻止潜在的欺诈交易。然后,来自应用程序的数据反馈到模型,以进行重新训练,提高准确性和效率。然后使用连续重新训练的模型更新生产应用程序等。
随着 机器学习 ( ML )和 深度学习( DL )越来越多地应用于不断增长的数据集,随着原始数据准备用于训练,在数据预处理和特征工程中, Apache Spark 已变得流行。它还用作分析工作负载的数据执行引擎。 GPU 以加速深度学习和人工智能工作负载的方式并行和加速数据处理查询。 RAPIDS 通常用于 GPU 加速基础架构中的 accelerate Spark 以及 ML / DL 框架。
此外,像 NVIDIA Morpheus 这样的人工智能框架可以在无监督的情况下运行,以标记异常活动并增强欺诈预防工作。基于人工智能的欺诈预防是动态的,可以自动适应威胁。
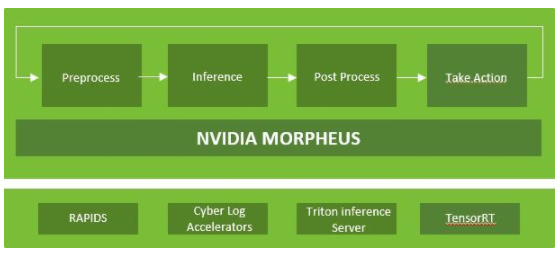
图 1 NVIDIA Morpheus 驱动框架示例
加速性能
是的,需要速度,尤其是交易前欺诈检测。
交易前检测
如果没有硬件加速,由于欺诈预防软件分析每笔交易,执行交易的客户可能会因无法接受的延迟而感到不便。处理速度慢会影响客户满意度,商家实现的收入更少。标准 CPU 足以预防遗留欺诈,但已不再适用。
由企业级 GPU 支持的基于人工智能的现代解决方案在速度和准确性上可以更有效。高性能 GPU 加速可以在给定的时间范围内评估更多的风险因素。或者,可以在更短的时间内评估相同数量的风险因素。
交易后检测
交易后欺诈检测不受实时约束。尽管如此, GPU 加速可以带来好处。更快的处理能力允许在给定的时间段内评估更多的数据。
与交易前结果一样,交易后结果可用于更新前后处理模型,以改善未来结果(推断)。
其他性能注意事项
IT 部门可能仅仅根据事务速度错误地评估服务器性能要求。然而,初始模型训练和基于来自推理应用程序的输入反馈数据的重新训练也需要高性能。
如果没有 GPU 加速,初始训练可能需要数小时或数天,再训练的时间可能长得令人无法接受。结果时间不仅仅是 GPU 时钟频率。一些 GPU 未被认证为企业级,并且缺乏大量 GPU 内存或足够数量的内核来提供快速训练结果。
是的,大型欺诈预防模型的培训可以在云中以性能和规模执行。不幸的是,经过多次训练迭代后,云处理周期可能会很昂贵。
幸运的是,可以使用代表性数据子集或较低分辨率精度参数,在企业 GPU 加速的工作站上以迭代方式经济高效地在本地执行模型训练。这使得在数据科学工作站或支持 GPU 的服务器的资本支出之后,初步模型培训的成本基本上是免费的。
经过初步培训后,可以在大型数据集上以更高的效率在云端或企业服务器或服务器集群中执行全面培训。
可用性和规模
欺诈者从不睡觉,因此企业欺诈预防也无法休息。事务应用程序不间断运行,因此防欺诈软件也必须这样做。企业 IT 基础设施必须为预防解决方案提供弹性和可用性。正如我所指出的,性能很重要,但当它不总是可用时,它否定了任何性能优势。
正如我之前所讨论的,欺诈和相关损害每年都在增加。预防解决方案必须无缝扩展以适应这种情况。
可用性和可扩展性要求不能局限于服务器。例如,网络可能满足所需吞吐量和延迟的规范,但事实是突发网络流量可能会导致足够的网络拥塞,从而导致欺诈检测被跳过、无法接受的延迟或超时。因此,在构建高级反欺诈解决方案时,不能忽视网络的鲁棒性和冗余性。
为欺诈解决方案构建 AI 友好的基础设施
随着时间的推移,您的人工智能驱动的解决方案能否获得成功所需的性能、可用性和规模?假设基于人工智能的防欺诈软件正确,它还必须确保正确的基础设施。正如我前面所讨论的,这意味着随着防欺诈数据和工作负载的增加,基础设施可以加速性能、不间断运行,以及无缝扩展基础设施投资的灵活性。
提供支持欺诈预防和人工智能驱动的企业解决方案的企业级 IT 基础设施也是一项挑战。正确的产品组合解决了企业欺诈预防的性能、可用性和扩展需求,同时支持其他人工智能框架和工具。从用于模型开发的移动和桌面工作站,到用于数据中心推理和大规模培训的服务器和软件。
关于作者
André Franklin 是 NVIDIA 数据科学营销团队的一员,专注于 NVIDIA 支持的工作站和服务器的基础设施解决方案。他在多个企业解决方案方面拥有丰富的经验,包括 NetApp 、 Hewlett-Packard enterprise 和具有预测分析功能的灵活存储阵列。安德烈居住在加利福尼亚州北部,以驾驶无线电控制的模型飞机、滑冰和拍摄大自然远足而闻名。
审核编辑:郭婷
-
芯盾时代全渠道交易反欺诈平台中标安徽省农信社2025-08-14 1441
-
红色警戒!深度伪造欺诈蔓延全球,ADVANCE.AI助力出海企业反欺诈新升级2024-06-12 1515
-
化工企业如何做好仪表自动化设备的预防性维修工作2022-11-10 1450
-
Redis欺诈检测方案及机器学习算法2022-10-28 2481
-
网络欺诈检测系统的应用优势是什么2021-07-23 1086
-
如何使用人工智能(AI)解决更广泛的欺诈领域2021-02-18 1965
-
为什么要起草企业AI来打击刺激欺诈的原因2020-09-10 1775
-
人工智能在金融风控领域的应用: 声纹反欺诈2020-03-21 1719
-
如何避免比特币欺诈广告2020-02-16 2109
-
组织可以采用人工智能技术来加强欺诈检测2019-10-08 2640
-
区块链技术是进行反欺诈的最佳解决方案吗2019-07-05 1662
-
改进RPE算法的神经网络在客户欺诈预测中的应用2010-01-03 472
-
信用卡欺诈行为多层动态检测模型2009-12-25 1142
-
防止信用卡欺诈的系统设计2009-08-15 581
全部0条评论

快来发表一下你的评论吧 !
