

三篇基于迁移学习的论元关系提取
描述
引言
随着越来越多的机器学习应用场景的出现,而现有表现比较好的监督学习需要大量的标注数据,标注数据是一项枯燥无味且花费巨大的任务,所以迁移学习受到越来越多的关注。本次论文分享介绍了三篇基于迁移学习的论元关系提取。
数据概览
基于迁移学习和主动学习的论元关系提取(Efficient Argument Structure Extraction with Transfer Learning and Active Learning)
论文地址:https://arxiv.org/pdf/2204.00707
该篇文章针对提取论元关系提出了基于Transformer的上下文感知论元关系预测模型,该模型在五个不同的领域中显著优于依赖特征或仅编码有限上下文的模型。为了解决数据标注的困难,作者通过迁移学习利用现有的注释好的数据来提高新目标域中的模型性能,以及通过主动学习来识别少量样本进行注释。
一个用于集成论辩挖掘任务的大规模数据集(IAM: A Comprehensive and Large-Scale Dataset for Integrated Argument Mining Tasks)
论文地址:https://arxiv.org/pdf/2203.12257
该篇文章为了使论辩中繁琐的过程自动化,提出了一个大规模数据集IAM,该数据集可用于一系列论辩挖掘任务,包括主张提取、立场分类、证据提取等。之后进一步提出了与论辩准备过程相关的两个新的论辩挖掘任务:(1)基于立场分类的主张提取,(2)主张-证据对提取。对每个集成任务分别采用流水线方法和端到端方法进行试验。
社会讨论中的无监督知识迁移有助于论辩挖掘吗?(Can Unsupervised Knowledge Transfer from Social Discussions Help Argument Mining?)
论文地址:https://arxiv.org/pdf/2203.12881
虽然基于Transformer的预训练语言模型可以在许多NLP任务中取得最好的结果,但是标注数据的缺乏和论证高度依赖领域的本质限制了此类模型的性能。文章提出了一种迁移学习的策略来解决,利用CMV做为数据集,微调选择性掩码语言模型,并且提出了基于prompt的策略来预测论元间的关系。
论文细节

论文动机
识别论元结构在论辩挖掘领域里是一项非常重要的任务。从正式文本,例如法律文件、科学文献到线上帖子,识别论元结构在识别各个领域的中心论点和推理过程方面发挥着重要作用。对于给定一个命题,该文章需要在给定文本窗口中从其他命题中预测与该命题之间的关系(支持或者反对)。但是一个巨大的挑战是需要捕捉命题之间的长期依赖关系。下图展示了识别论元关系的一个例子,该例子为同行评审和在线评论中的论点摘录。右边表示论元结构被标记为命题之间的支持关系。尽管文本之间的主题或词汇存在差异,但我们看到两篇文本都具有相似结构的长期依赖关系,表明识别论元之间的关系可能会跨度很大,因此需要理解更长的上下文。

由于现有的方法需要高质量的标注数据、为了解决长期依赖从而人工设计的自定义特征以及模型训练,导致时间复杂度非常高。因此文章的主要目标是设计一个方便研究者在新领域的文本中更快更精确地提取出论元关系模型。文章首先提出了一种上下文感知的论元关系预测模型,该模型可以通过微调Transformer获得。对于给定的命题,模型对该命题的更多相邻的命题进行编码,不仅仅是编码紧挨的命题。此外,由于标注论元结构即使是对于有经验的标注人员来说依然很困难,所以文章第二个目标是通过少量的数据来有效的训练模型。文章提出了两种互补的方法:(1)迁移学习可以调整在不同域中现有注释数据上训练的模型,或利用未标记的域内数据来进行更好的表示学习。(2)主动学习基于样本获取策略选择新域中的样本,以优化训练性能。
论元关系预测模型
任务定义
将一篇文本切分为多个命题来预测命题到命题是否存在支持或反对关系,其中目标命题称为“头部”,命题称为“尾部”,为了方便起见,文章给出了“头部”的先验知识。
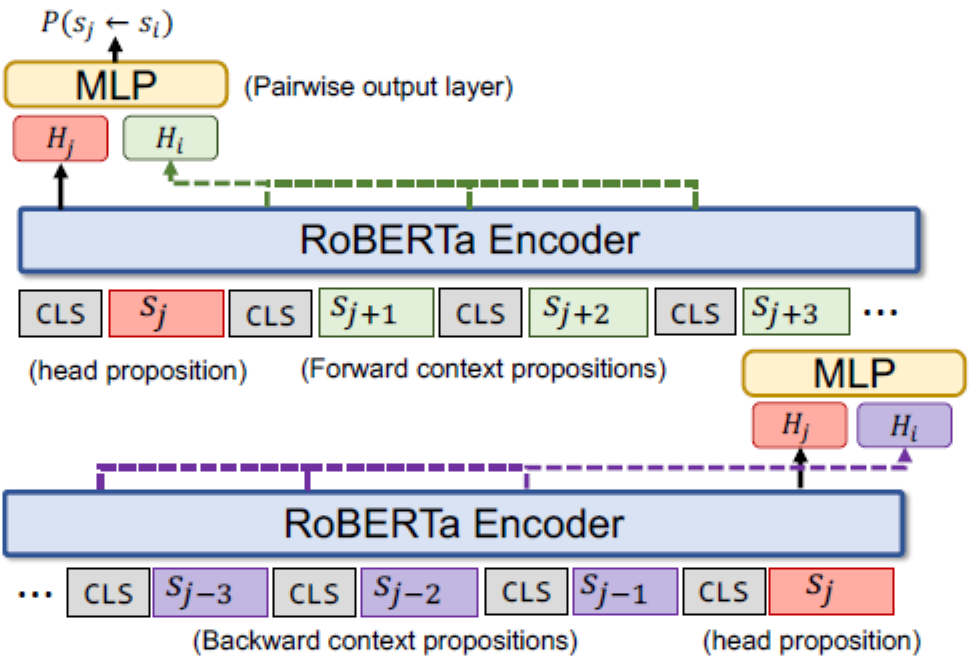
上下文感知模型
下图表示了该模型,模型是建立在RoBERTa之上,RoBERTa包含多层,每一层都使用双向多头自注意力机制。对于每一个”头部“命题,文章编码了在它之前的个命题(紫色表示)以及它之后的个命题(绿色表示),命题之间通过[CLS]分开。表示的最后一层状态,每一个和分别与拼接后传给配对输出层,从而预测命题到命题的概率。
预测概率公式为:
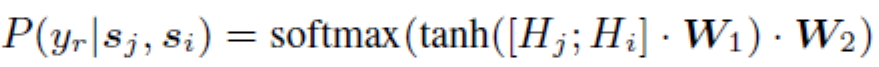
其中表示三类:支持、反对和无关。和表示训练参数。
主动学习策略
文章考虑了一个基于池主动学习策略,训练集的标签最初是不可用的,并且进行次学习过程。在第次迭代中,利用给定的数据获取策略选择个样本,将这些数据标注之后添加到数据池构成,模型在上训练。
与模型无关的数据获取策略
通过模型获取的数据可能不适用于接下来的模型,这是主动学习的一个弊端。因此作者设计了与模型无关的数据获取策略。
NOVEL-VOCAB促使命题使用更多未观察到的单词,假设单词在数据池中出现的频率为,则对于未标注的样本的得分为:
其中是样本中单词的频率。有着最高得分的样本会被选中来标注。
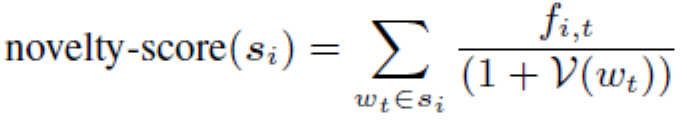
DISC-MARKER旨在通过匹配以下18个论述标记来选择更多的关系链接。

数据集及相关领域
Domain 1: Peer Reviews
AMPERE包含了400篇ICLR 2018年的文章评审,每一个命题被标注为evaluation、request、fact、reference和quote。文章在AMPERE的基础之上将命题之间的关系标注为支持或者反对,新的数据集命名为**AMPERE++**。最终结果为400篇评审包含3636对关系,其中300篇做为训练集,20篇做为验证集,80篇做为测试集。并且文章另外收集了42K篇评审用在自监督学习中来提高表示学习。
Domain 2: Essays
命题被标注为premise、claim和major claim,支持与反对关系只能存在于premise到premise或者claim,并且命题之间不能跨段落。其中282篇文章做为训练集,20篇文章做为验证集,80篇文章做为测试集,同样作者另外收集了26K篇文章用来自监督表示学习。
Domain 3: Biomedical Paper Abstracts
AbstRCT语料库包含700篇论文摘要,主要主题是疾病的随机对照试验。其中350篇摘要做为训练集,50篇做为验证集,300篇做为测试集。作者另外收集了133K篇未标注的摘要用做自监督学习。
Domain 4: Legal Documents
ECHR包含了42篇关于欧洲人权法院的法律文件,其中27篇做为训练集,7篇做为验证集,8篇做为测试集。
Domain 5: Online User Comments
Cornell eRulemaking Corpus来自于线上论坛,其中501篇做为训练集,80篇做为验证集,150篇做为测试集。
实验结果
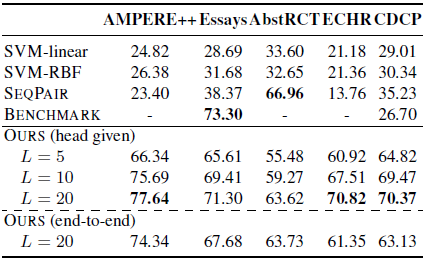
监督学习结果
下表表明了除了Essays和AbstRCT,上下文感知模型均优于基线模型,在这两个数据集上特征丰富的SVM性能要优于上下文感知模型。AbstRCT有着更高的正样本率,表明上下文感知模型在对抗不平衡的训练数据上面要更加鲁棒。
迁移学习结果
上一节中的结果显示了不同域之间的巨大性能差异。带有少量标记样本的域,例如AbstRCT和CDCP,会导致更差的性能。此外,注释某些领域的论元结构更加复杂。我们假设理解论元关系的基本推理能力可以跨域共享,因此作者研究了迁移学习,它利用具有相似任务标签(transductive)或相同目标域的未标记数据(inductive)做为现有数据。具体来说,作者在所有传输对上进行了全面的迁移学习实验,其中模型首先在源域上训练并在目标域上进行微调。
Transductive TL 下表的上半部分显示,从 AMPERE++ 迁移而来的模型中有四分之三的模型实现了更好的性能。但是,当从其他四个数据集进行传输时,性能偶尔会下降。这可能是由于不同的语言风格和论元结构、源域大小或由于过度依赖论述标记而导致模型无法学习良好的表示。总体而言,AMPERE++ 始终有利于论元结构理解不同领域,展示了其在未来研究中的潜力。
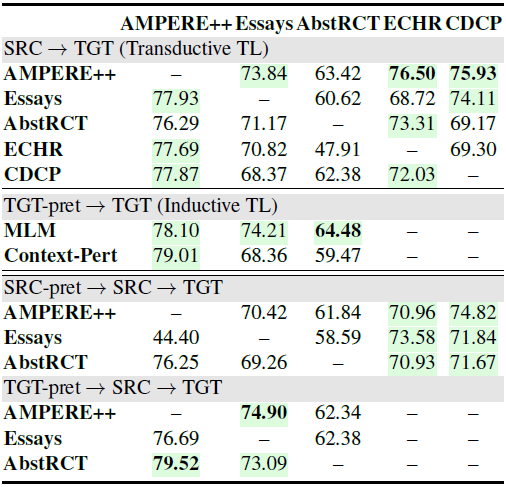
Inductive TL 作者考虑了归纳式的迁移学习并且设置了两个任务:
(1)掩码模型预测(MLM):随机选择15%的输入数据做为预测;
(2)上下文感知的句子扰动(Context-Pert):它将每个文档打包成一个由[CLS]分割的句子序列,其中20%被来自其他文档的随机句子替换,另外20%在同一个文档中打乱, 其余不变。
预训练目标是预测每个句子的扰动类型。结果在上表的中间部分,其中MLM对所有三个领域都有好处。Context-Pert进一步提高了AMPERE++的性能,但降低了其他两个域的性能。
Combining Inductive and Transductive TL 此外,作者证明了添加自监督学习做为Transductive迁移学习的额外预训练步骤可以进一步提高性能。从上表的下半部分来看,预训练模型比标准的Transductive迁移学习得到了一致的改进。值得注意的是,使用目标域进行预训练会比使用源域数据产生更好的结果。这意味着更好的目标域语言表示学习比更强大的源域模型更有效。
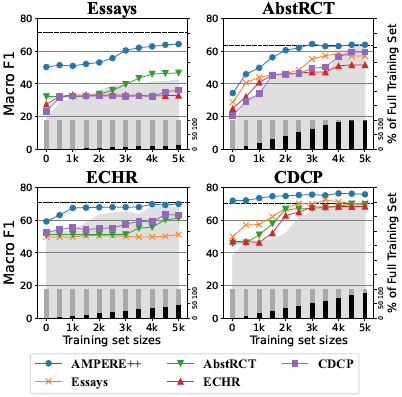
Effectiveness of TL in Low-Resource Setting 为了定量地证明迁移学习如何使低资源目标域有效,我们控制训练数据的大小并对每个域进行Transductive迁移学习。下图描绘了训练数据从0到5,000变化的趋势,增量为500。在所有数据集中,AMPERE++作为源域产生了最好的迁移学习结果:使用不到一半的目标训练集。一般来说,当使用较少的训练数据时,迁移学习会带来更多的改进。
主动学习结果
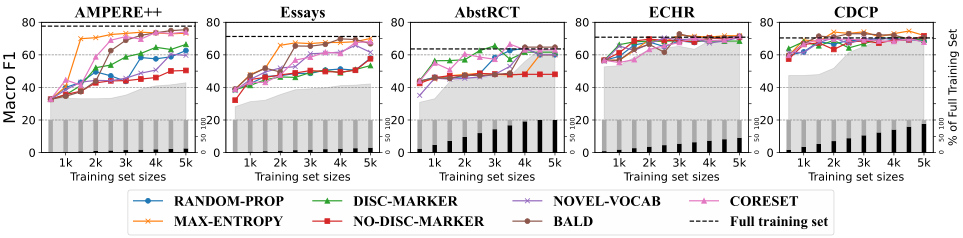
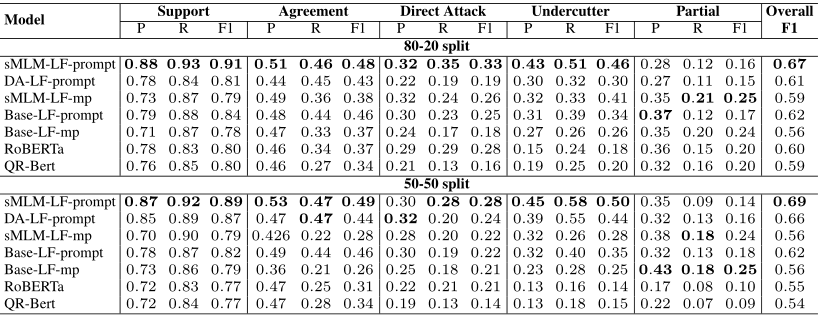
下图展示了所有策略的F1得分,从图中可以看出,标注数据越多,性能越好。MAX-ENTROPY,BALD和CORESET三种基于模型的方法获得更好的性能,不依赖模型的方法也产生了相对较好的结果。对于AMPERE++和AbstRCT,DISC-MARKER被证实是一个很好的启发式选择。在论文领域中,由于论述标记大量使用,所以它的得分相对较低,不使用论述标记会导致性能下降。值得注意的是,在不依赖任何训练模型的情况下,特定于任务的数据获取策略可以有效地标记论元关系。


论文动机
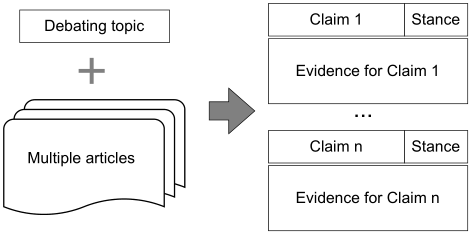
传统的论辩通常需要人工准备过程,包括阅读大量文章,选择主张,确定主张的立场,为主张寻找证据等。论辩挖掘做为论辩系统中的核心,近年来受到了广泛关注。一些论辩挖掘任务和数据集被用来自动化实现AI论辩,文章的目标是实现论辩论准备过程的自动化,如图所示。具体来说,提供论辩主题和几篇相关的文章,从这些主张中提取它们的立场,以及支持这些主张的证据。
然而现有的工作没有能够完成这一系列的任务(主张提取、立场分类、证据提取),因此文章提出了IAM数据集来解决这个难题。为了更好地协调这些任务,文章提出了两个新的集成任务:基于立场分类的主张提取(CESC)和主张-证据对提取(CEPE)。这两个任务不对现有的任务进行处理,而是将相关的主要任务整合在一起,这样在准备辩论的过程中更实际、更有效。CESC任务可以分为两个子任务:主张检测任务和立场分类任务。直观上,我们在CESC任务上进行实验,采用流水线方法将两个子任务结合起来。由于这两个子任务是相辅相成的,所以我们也采用了端到端的多标签分类模型(支持、反对、无关系)。CEPE任务由主张检测任务和证据检测任务组成。与注释过程类似,利用多任务模型同时提取主张和证据及其配对关系。
IAM数据集
数据收集
作者从线上论坛广泛的收集了123个论辩主题,对于每个主题,收集了大约10篇来自英文维基百科的文章,总共收集了1010篇文章,共69,666个句子。
数据标注
标注过程分为两个阶段:
对给定话题检测主张;
对给定主张检测证据。
下表表示了一个例子,主题是”人工智能会取代人类吗?“以及标注好的主张。主张被标记为“C_index”,证据被标记为“E_index”。对于立场,“+1”代表支持该主题的当前主张,而“-1”代表反对该主题的主张。一个证据可以支持多个主张,同样一主张也可以由多个证据来支持。

数据集分析
该数据集包含123个话题,可以应用于各个子任务。下表展示了数据集的统计信息,句子的长度平均21个单词,数据集还计算了每个”主张-证据“句子对之间共享的词汇的平均百分比为20.14%;而语料库中任意两个句子之间的比例仅为8.73%。这说明提取“主张-证据”对是一项合理的任务,因为“主张-证据”的词汇共享比例高于其他句子对。

任务
现存的子任务
主张提取:给定一个特定的论辩主题和相关文章,自动从文章中提取主张。因为主张是关键的论元,所以主张提取任务是基础性任务。
立场分类:给定一个主题和为其提取的一组主张,确定每个主张是支持该主题还是反对该主题。
证据提取:给定一个具体的主题、相关的主张和可能相关的文章,需要该模型自动确定这些文档中的证据。
集成的任务
主张提取-立场分类(CESC):由于主张有着明确的立场,因此立场明确的句子很有可能成为主张。立场识别可能有利于主张提取,因此将任务一与任务二合并,即给定一个特定的主题和相关的文章,从文章中提取主张,也确定主张对该主题的立场。
主张-证据对提取(CEPE):文章假设主张提取和证据提取之间相辅相成,所以结合任务一和任务三,即给定一个特定的主题和相关的文章,从文章中提取主张-证据对。
方法
句子配对分类
将句子对连接起来,并输入到预训练模型中,以获得“[CLS]”标记的隐藏状态。之后,一个线性分类器将预测两个句子之间的关系。任务一到任务三都可以表示为一个二分类任务,交叉熵做为损失函数。
由于任务一和任务三的数据标签是不平衡的,主张和证据的总数要远小于句子总数,因此可以利用负采样来解决。在这两个任务训练过程中,对于每一个主张或者证据,随机选取一定数量的非主张或非证据句子做为负样本,这些负样本连同所有的主张和证据共同构成了每个任务的新的训练数据集。
多标签模型用于CESC
文章将主题和句子配对输入到预训练模型中,输出标签为支持、反对和无关。由于无关的数量要远大于支持和反对的数量,因此采用负采样来保证更加平衡的训练过程。
多任务模型用于CEPE
首先将主题和文章中各个句子连接起来做为主张候选集,文章中的句子序列做为证据候选集。将主张提取和证据提取定义为序列标注问题,主张候选集和证据候选集输入到预训练模型中得到嵌入表示。为了预测两句话是否构成主张-证据对,文章采用填表的方法,将主张候选集的每个句子与证据候选集的每个句子配对,形成一个表,所有三个特征(即主张候选集、证据候选集、表格)都通过注意力引导的多交叉编码层相互更新。最后,两个序列特征用于预测其序列标签,表格特征用于每个主张和证据之间的配对预测。与流水线方法相比,该多任务模型具有更强的子任务协调能力,因为两个子任务之间的共享信息是通过多交叉编码器显式学习的。
实验结果
现有任务的主要结果
1.主张提取:下表展示了任务一的性能,RoBERTa-base性能略优于BERT-base-cased。
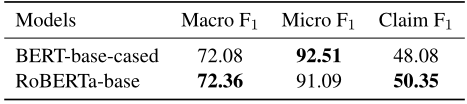
2.立场分类:下表说明两种类型的主张F1得分相近,并且RoBERTa-base性能优于BERT-base-cased。
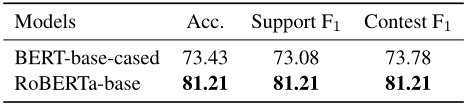
3.证据提取:下表显示了任务3上的性能。同样,RoBERTa模型比BERT模型性能更好。对于这个任务,作者实验了两种设置:(1)给定主题和主张(T+C),(2)仅给定主张(C),从候选句子中识别证据。对于(T+C)设置,只需将主题和主张连接为一个句子,并与证据候选集配对,以预测它是否是特定主题下给定主张的证据。对比这两种设置的结果,添加主题的句子作为输入并没有进一步显著提高性能,这说明主张与证据的关系更密切,而主题并不是证据提取的决定性因素。
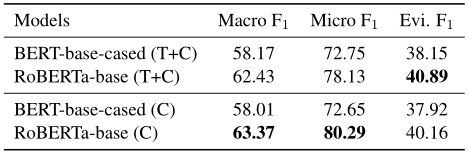
集成任务的主要结果
CESC任务:下表显示了CESC任务的两种方法的结果。对于两种方法,在训练过程中为每个正样本(主张)随机选取5个负样本。流水线模型独立训练两个子任务,然后将它们连接到一起,以预测一个句子是否为主张以及句子的立场。虽然它在每个子任务上都取得了最好的性能,但总体性能不如多标签模型。结果表明,识别主张的立场有利于主张提取任务,这种多标签模型有利于集成CESC任务。

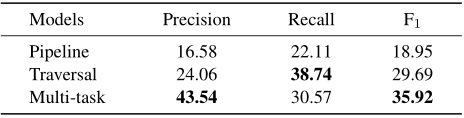
CEPE任务:下表显示了不同方法之间的总体性能比较。除了前面提到的流水线和多任务模型,文章还添加了另一个基线模型,命名为“遍历”。在该模型中,所有可能的“主题+主张候选句”和“证据候选句”被连接起来,并输入到句子对分类模型中。遍历模型和多任务模型在F1总分上都优于流水线模型,这意味着同时处理这两个子任务的重要性。多任务模型的性能优于遍历模型,说明多任务体系结构具有较强的子任务协调能力。


论文动机
线上论辩文本:用户在网上来回发布的帖子引发的讨论,反映了大规模的意见互动。下图表示了两个用户连续发帖中的论元标注,红色代表主张,蓝色代表前提。

标注数据的缺乏:之前的研究试图以半监督的方式利用大量的未标记数据,然而这种方法要求论元被定义在句子级别,因此在预测过程中会添加额外的跨度。BERT虽然可以解决特定任务上的数据稀缺问题,但是BERT学习到的语言表示依然限制了此类模型的表达能力。
因此,作者提出了基于Transformer的迁移学习方法。作者从CMV社区中使用大量未标记数据做为论辩知识来源,基于Transformer的预训练模型使用掩码语言模型(MLM)在数据集上微调,不像之前随机掩码单词来预测,作者掩码几个帖子中特定的标记来进行预测,将这种方法命名为选择性掩码语言模型(sMLM)。为了充分利用基于sMLM语言模型训练,作者提出了基于prompt的方法来预测论元之间的关系。
选择性语言模型(sMLM)
CMV的结构
讨论论坛方便用户可以发帖子以及在下面进行评论,其他用户可以回复原帖或者评论。最终可以形成类似于以原帖为根节点的树形结构,从根节点到叶子节点的路径可以被视为两个或多个用户独立的对话路径,将该路径称为“线程”。
sMLM微调
作者选择特定的词来掩码,而不是随机选择。作者选择多个标记,表明意见、因果关系、反驳、事实陈述、假设、总结和一些额外的词,这些词根据上下文的不同有多种用途。下图表示sMLM需要预训练语言模型来根据上下文预测红色单词。
由于CMV线程将对话分为评论/帖子级别以及线程级别。作者试图探索在不同的论辩挖掘任务中文本大小的影响。为此作者使用提出的sMLM对BERT进行微调,并在线程机制中训练Longformer模型,Longformer使用稀疏的全局的注意力机制,即少量单词关注全部单词来获得长期依赖。

论元识别
在选择性微调之后,作者要在线程中识别论元类型。由于在单词级别上进行的检测,所以使用标准的BIO标注模式,即.
论元关系识别
作者提出基于prompt的方法来预测论元之间的关系。如下图所示,试图对USER-1和USER-2提出的主张之间的关系进行分类,分别用红色和绿色突出显示;通过追加提示模板,线程被转换为提示输入。语言模型将提示标记序列转换为固定维度的向量,掩码标记位置对应的向量用于关系分类。

实验结果
数据集
作者使用CMV做为数据集,其中99%的数据做为训练集,1%的数据用来检验sMLM模型的准确率。数据集包括3051条原帖以及293,297条评论,共有34,911个用户,120,031个线程。
论元识别
下表展示了论元识别的结果。首先,从现有性能最好的基于LSTM的方法(精度为0.54)转移到BERT时(精度为0.62),可以看到字符级标记精度得分的巨大差异。这种差异是意料之中的,因为像BERT这样的预训练语言模型在CMV这样的小型数据集中提供了先机。尽管字符级标记的精度提高了,但是精确论元匹配的微平均F1得分在使用RoBERTa之前并没有增加太多。使用sMLM微调进行训练的Longformer在论元识别的F1总得分方面明显优于其他模型。然而,与评论级上下文(RoBERTa)相比,选择性语言模型的影响在线程级上下文(即Longformer)的情况下更为突出。
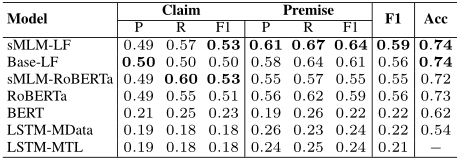
论元关系识别
下表给出了CMV数据集上论元关系识别的结果。考虑传统的平均池化方法,在这种方法中,我们观察到sMLM预先训练的Longformer在训练集为80%和测试集为20%的情况下提高了3个点,而在训练集和测试集各为50%的情况下保持相似的性能。此外,无论使用Longformer还是sMLM,基于prompt的方法始终优于平均池化方法。
审核编辑 :李倩
-
测度论学习入门(电子版)2019-04-08 1727
-
迁移学习训练网络2019-09-09 1816
-
NLPIR在文本信息提取方面的优势介绍2019-09-12 1397
-
【木棉花】学习笔记--分布式迁移2021-09-05 1935
-
【木棉花】学习笔记--分布式迁移+回迁2021-09-07 2570
-
迁移学习2022-04-21 11448
-
概率论与数理统计学习资料2010-02-13 1266
-
人工智能、机器学习、深度学习三者关系分析2018-01-04 7601
-
论华为的客户关系管理:客户关系是一种投资2018-12-03 3334
-
基于脉冲神经网络的迁移学习算法2021-05-24 1675
-
基于模糊选项关系 的关键属性提取综述2021-06-07 732
-
基于迁移深度学习的雷达信号分选识别2022-03-02 2516
-
一文详解迁移学习2023-08-11 8116
-
预训练和迁移学习的区别和联系2024-07-11 3182
-
如何精准提取MOSFET沟道迁移率2025-05-19 2256
全部0条评论

快来发表一下你的评论吧 !
