

导致微控制器中断延迟的原因
控制/MCU
描述
中断从高速处理器中占用了很多资源,尤其是流水线密集且每个周期能够发出多条指令的处理器。任何时候都可能有 8 到 10 条指令在运行,要么必须运行到完成,要么在正常执行恢复后取消并重新启动。
电气工程师需要检查中断对应用程序的响应速度是否足够快,并且中断的开销不会淹没主应用程序。
给定的 MCU 执行中断的速度有多快?这肯定会受到应用程序的影响,但似乎很难找到该项目的编号。
当中断发生时,CPU会保存它的一些寄存器并执行中断服务程序(ISR),然后在就绪状态下返回最高优先级的任务。中断通常是可屏蔽和可嵌套的。
为了清楚起见,延迟通常被指定为中断请求和中断服务程序中第一条指令执行之间的时间。然而,“真正的延迟”必须包括一些必须在 ISR 中完成的内务处理,这可能会导致混乱。
电气工程师通常感兴趣的值是最坏情况下的中断延迟。这是许多不同的较小延迟的总和。
中断请求信号需要与 CPU 时钟同步。根据同步逻辑,在中断请求到达 CPU 内核之前,通常最多会丢失三个 CPU 周期。
CPU 通常会完成当前指令。该指令可能需要很多周期,除法、推多或内存复制指令需要最多的时钟周期花费最多的时间。内存访问通常需要额外的周期。例如,在 ARM7 系统中,指令 STMDB SP!,{R0-R11,LR}(Push parameters and perm.)Registers 通常是最坏情况的指令。它在堆栈上存储 13 个 32 位寄存器,需要 15 个时钟周期。
存储系统可能需要额外的等待状态周期。
在当前指令完成后,CPU 执行模式切换或将寄存器(通常是 PC 和标志寄存器)压入堆栈。通常,现代 CPU(例如 ARM)执行模式切换,这比节省寄存器需要更少的 CPU 周期。
如果您的 CPU 是流水线的,则模式开关已经刷新了流水线,并且需要更多的周期来重新填充它。但我们还没有完成。在更复杂的系统中,可能有其他原因导致中断延迟。
在更复杂的系统中,可能存在导致中断延迟的其他原因。
缓存行填充导致的延迟:
如果内存系统有一个或多个缓存,这些缓存可能不包含所需的数据。然后,不仅从内存中加载所需的数据,而且在许多情况下需要执行完整的行填充,从内存中读取多个字。
缓存写回造成的延迟:
缓存未命中可能会导致行被替换。如果此行被标记为脏,则需要将其写回主存,从而导致额外的延迟。
由内存管理单元 (MMU) 转换表遍历引起的延迟:
转换表遍历可能需要相当长的时间,尤其是因为它们可能涉及缓慢的主内存访问。在实时中断处理程序中,由不包含处理程序和/或其访问的数据的转换的转换后备缓冲区 (TLB) 引起的转换表遍历会显着增加中断延迟。
由应用程序引起的延迟:
应用程序可以通过禁用中断导致额外的延迟。
中断例程引起的延迟:
如果应用程序有多个紧急中断,它们不能被屏蔽,因此可能会请求另一个,从而延长了总时间。
RTOS 引起的延迟:
RTOS 还需要暂时禁用可以调用 API 函数的中断。一些 RTOS 禁用所有中断,有效地恶化了所有中断的中断延迟,一些(如 Segger 的 embOS)仅禁用低优先级中断。
ARM7 和 ARM Cortex
ARM7 和 ARM Cortex 在中断领域有很大不同。通过在处理器中集成中断控制器,基于 Cortex-M3 处理器的微控制器具有一个中断向量入口和每个中断源的中断处理程序。这避免了重入中断处理程序的需要,这对中断延迟有负面影响。
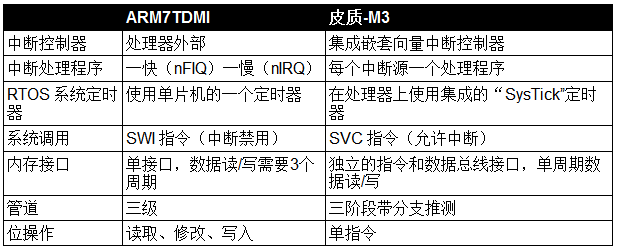
Cortex-M3 还通过逻辑加速中断处理程序的执行,以便在中断到达时自动将其通用寄存器和状态寄存器保存在堆栈中。在某些情况下,通过尾链同时到达的中断使 M3 更加高效,如图 1 所示。
基于 Cortex-M3 处理器的 MCU 的中断延迟高达 12 个周期,并且上下文切换时间《4 μs,而ARM7 《7 μs。
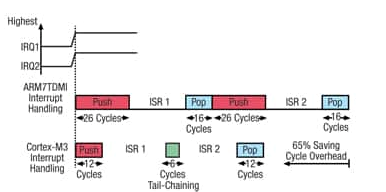
图 1:Cortex-M3 处理器上的尾链加速。
Microchip Microchip的技术工程师 Keith Curtis 表示,8 位 PIC-16/PIC-18 MCU 需要 12 到 20 个时钟周期才能到达 ISR——这取决于中断时正在进行的指令类型。然后,在 ISR 中,编译器将添加指令以确定中断的来源并推送一些寄存器。如果您使用的是汇编语言,您将放入自己需要推送的项目,也许没有。
根据应用工程师 Adrian Aur 的说法,Microchip 的 32 位 PIC32 MCU 最多需要 11 个时钟周期才能到达 ISR,您将在其中至少保存一些寄存器——最坏的情况是,所有 32 个每个都需要一个时钟周期。如果您响应最高优先级(且不可中断)的 INT7,将使用一组影子寄存器,从而使响应速度更快。然后,RTOS 可能想要进行线程更改,或者在以较低优先级运行时启用嵌套中断,这会增加一些延迟。除此之外,你应该没问题
Atmel
2008 年,电子产品杂志授予 Atmel AVR XMEGA 微控制器系列年度产品奖。最大的原因是其创新的八通道事件系统,该系统使用与数据总线分开的总线,无需 CPU 或 DMA 即可实现外设间通信。这样做的好处是可预测、低延迟、外设间信号通信、减少 CPU 使用率以及释放中断资源。
独立于 CPU 和 DMA,事件系统的响应时间永远不会超过 I/O 时钟的两个时钟周期(通常为 62.5 ns)。
XMEGA 使用哈佛架构,程序存储器与数据分离。使用单级流水线访问程序存储器。在执行一条指令时,会预取下一条指令。快速访问 RISC 寄存器文件(32 x 8 位通用工作寄存器)增强了性能。在一个时钟周期内,XMEGA 可以将寄存器文件中的两个任意寄存器馈送到 ALU,执行请求的操作,并将结果写回任意寄存器。
所有已启用中断的中断响应时间至少为五个 CPU 时钟周期。在这五个时钟周期内,程序计数器被压入堆栈。五个时钟周期后,执行中断的程序向量。跳转到中断处理程序需要三个时钟周期。
如果在执行多周期指令期间发生中断,则该指令在中断服务之前完成。如果在设备处于睡眠模式时发生中断,则中断执行响应时间增加五个时钟周期。此外,响应时间会增加从所选睡眠模式开始的启动时间。
从中断处理程序返回需要五个时钟周期。在这五个时钟周期内,程序计数器从堆栈中弹出,堆栈指针递增。
-
使用TLE9877微控制器通过LIN端口检测PWM信号会有延迟,为什么?2024-07-17 1018
-
#硬声创作季 #无人机微控制器技术 54 28、微控制器的中断系统醉 2022-12-13
-
电梯的基础原理:微控制器jf_10480160 2022-12-14
-
什么是微控制器2011-11-14 3742
-
如何才能选到合适的微控制器?2021-11-01 922
-
有没有什么方法可以根据时钟周期数给微控制器延迟2022-12-01 410
-
微控制器不断收到IVOR1错误是怎么回事?2023-04-06 683
-
PrimeCell矢量中断控制器(PL190)技术参考手册2023-08-02 738
-
LM3S系列微控制器中断优先级应用笔记2010-03-26 949
-
基于STR7 ARM微控制器的IRQ中断防御体系2010-12-11 1120
-
关于AVR微控制器采用单周期指令集原因的介绍2018-07-06 4173
-
什么是微控制器?如何编程微控制器?2020-08-21 13431
-
ARDUINO微控制器外部中断处理2022-10-27 1036
-
如何在PIC16F877A微控制器中使用中断2023-01-25 3896
-
MAXQ微控制器中断编程2023-02-20 1656
全部0条评论

快来发表一下你的评论吧 !
