

JDK8 Stream数据流效率分析
描述
JDK8 Stream 数据流效率分析
Stream 是Java SE 8类库中新增的关键抽象,它被定义于 java.util.stream (这个包里有若干流类型:Stream 代表对象引用流,此外还有一系列特化流,如 IntStream,LongStream,DoubleStream等 )。
Java 8 引入的的Stream主要用于取代部分Collection的操作,每个流代表一个值序列,流提供一系列常用的聚集操作,可以便捷的在它上面进行各种运算。集合类库也提供了便捷的方式使我们可以以操作流的方式使用集合、数组以及其它数据结构;
stream 的操作种类
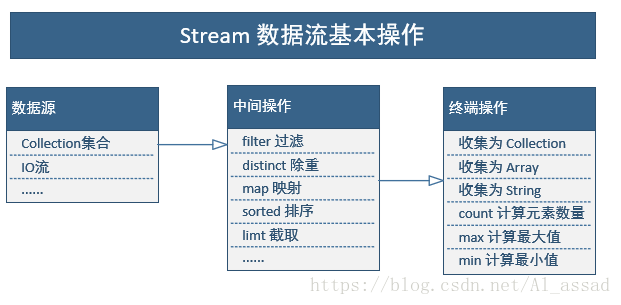
①中间操作
- 当数据源中的数据上了流水线后,这个过程对数据进行的所有操作都称为“中间操作”;
- 中间操作仍然会返回一个流对象,因此多个中间操作可以串连起来形成一个流水线;
-
stream提供了多种类型的中间操作,如filter、distinct、map、sorted等等;
②终端操作
-
当所有的中间操作完成后,若要将数据从流水线上拿下来,则需要执行终端操作;
-
stream对于终端操作,可以直接提供一个中间操作的结果,或者将结果转换为特定的collection、array、String等;
stream 的特点
①只能遍历一次:
数据流的从一头获取数据源,在流水线上依次对元素进行操作,当元素通过流水线,便无法再对其进行操作,可以重新在数据源获取一个新的数据流进行操作;
②采用内部迭代的方式:
对Collection进行处理,一般会使用 Iterator 遍历器的遍历方式,这是一种外部迭代;
而对于处理Stream,只要申明处理方式,处理过程由流对象自行完成,这是一种内部迭代,对于大量数据的迭代处理中,内部迭代比外部迭代要更加高效;
stream 相对于 Collection 的优点
注无存储: 流并不存储值;流的元素源自数据源(可能是某个数据结构、生成函数或I/O通道等等),通过一系列计算步骤得到;
- 函数式风格: 对流的操作会产生一个结果,但流的数据源不会被修改;
- 惰性求值: 多数流操作(包括过滤、映射、排序以及去重)都可以以惰性方式实现。这使得我们可以用一遍遍历完成整个流水线操作,并可以用短路操作提供更高效的实现;
-
无需上界: 不少问题都可以被表达为无限流(
infinite stream):用户不停地读取流直到满意的结果出现为止(比如说,枚举 完美数 这个操作可以被表达为在所有整数上进行过滤);集合是有限的,但流可以表达为无线流; -
代码简练: 对于一些
collection的迭代处理操作,使用 stream 编写可以十分简洁,如果使用传统的collection迭代操作,代码可能十分啰嗦,可读性也会比较糟糕;
stream 和 iterator 迭代的效率比较
好了,上面 stream 的优点吹了那么多,stream 函数式的写法是很舒服,那么 steam 的效率到底怎样呢?
先说结论:
-
传统
iterator (for-loop)比stream(JDK8)迭代性能要高,尤其在小数据量的情况下; -
在多核情景下,对于大数据量的处理,
parallel stream可以有比iterator更高的迭代处理效率;
我分别对一个随机数列 List (数量从 10 到 10000000)进行映射、过滤、排序、规约统计、字符串转化场景下,对使用 stream 和 iterator 实现的运行效率进行了统计。
测试环境如下:
System:Ubuntu 16.04 xenial
CPU:Intel Core i7-8550U
RAM:16GB
JDK version:1.8.0_151
JVM:HotSpot(TM) 64-Bit Server VM (build 25.151-b12, mixed mode)
JVM Settings:
-Xms1024m
-Xmx6144m
-XX:MaxMetaspaceSize=512m
-XX:ReservedCodeCacheSize=1024m
-XX:+UseConcMarkSweepGC
-XX:SoftRefLRUPolicyMSPerMB=100
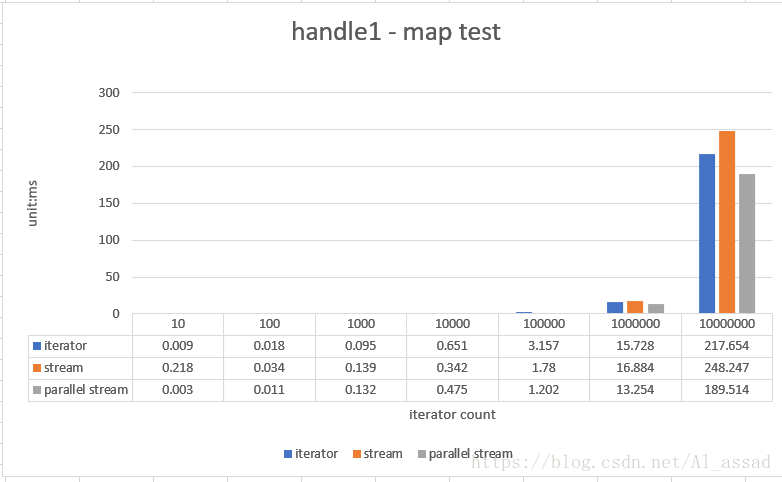
1. 映射处理测试
把一个随机数列(List)中的每一个元素自增1后,重新组装为一个新的 List,测试的随机数列容量从 10 - 10000000,跑10次取平均时间;
//stream
List result = list.stream()
.mapToInt(x -> x)
.map(x -> ++x)
.boxed()
.collect(Collectors.toCollection(ArrayList::new));
//iterator
List result = new ArrayList<>();
for(Integer e : list){
result.add(++e);
}
//parallel stream
List result = list.parallelStream()
.mapToInt(x -> x)
.map(x -> ++x)
.boxed()
.collect(Collectors.toCollection(ArrayList::new));
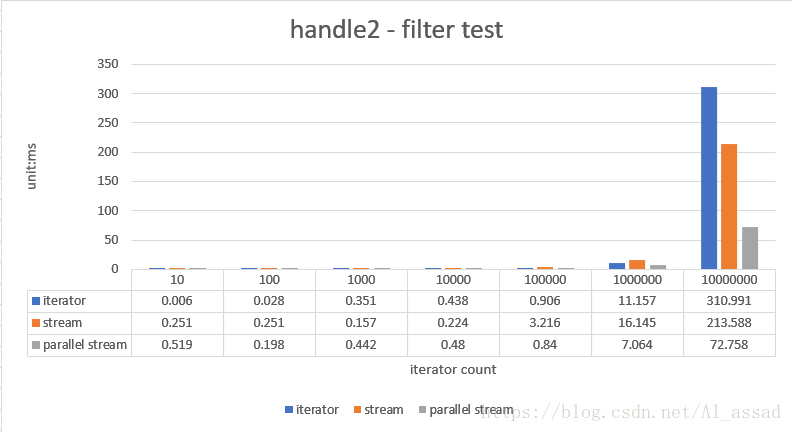
2. 过滤处理测试
取出一个随机数列(List)中的大于 200 的元素,并组装为一个新的 List,测试的随机数列容量从 10 - 10000000,跑10次取平均时间;
//stream
List result = list.stream()
.mapToInt(x -> x)
.filter(x -> x > 200)
.boxed()
.collect(Collectors.toCollection(ArrayList::new));
//iterator
List result = new ArrayList<>(list.size());
for(Integer e : list){
if(e > 200){
result.add(e);
}
}
//parallel stream
List result = list.parallelStream()
.mapToInt(x -> x)
.filter(x -> x > 200)
.boxed()
.collect(Collectors.toCollection(ArrayList::new));
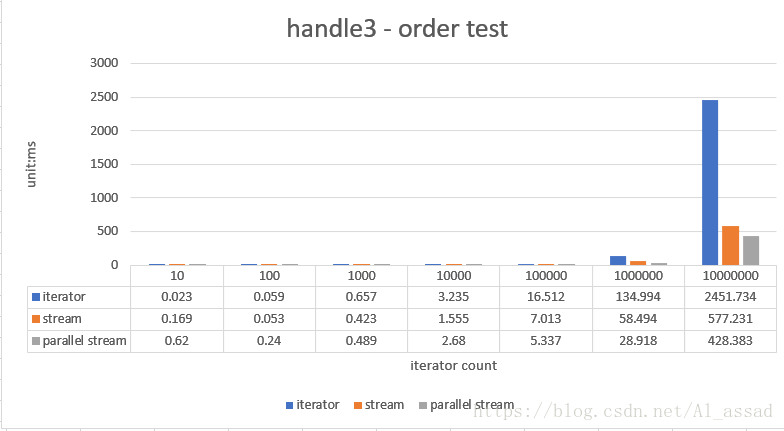
3. 自然排序测试
对一个随机数列(List)进行自然排序,并组装为一个新的 List,iterator 使用的是 Collections # sort API(使用归并排序算法实现),测试的随机数列容量从 10 - 10000000,跑10次取平均时间;
//stream
List result = list.stream()
.mapToInt(x->x)
.sorted()
.boxed()
.collect(Collectors.toCollection(ArrayList::new));
//iterator
List result = new ArrayList<>(list);
Collections.sort(result);
//parallel stream
List result = list.parallelStream()
.mapToInt(x->x)
.sorted()
.boxed()
.collect(Collectors.toCollection(ArrayList::new));
4. 归约统计测试
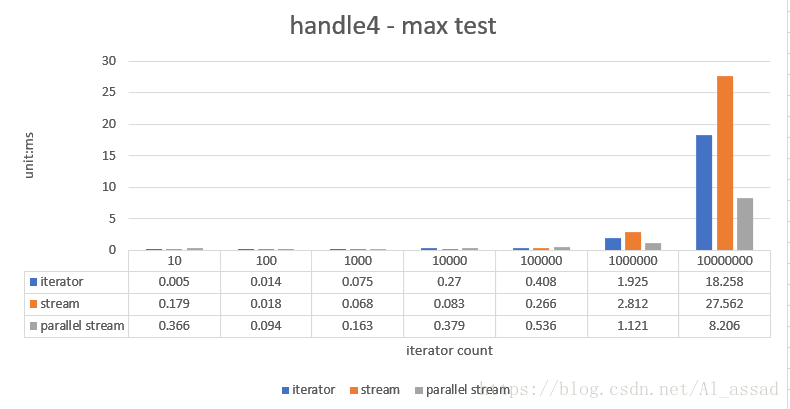
获取一个随机数列(List)的最大值,测试的随机数列容量从 10 - 10000000,跑10次取平均时间;
//stream
int max = list.stream()
.mapToInt(x -> x)
.max()
.getAsInt();
//iterator
int max = -1;
for(Integer e : list){
if(e > max){
max = e;
}
}
//parallel stream
int max = list.parallelStream()
.mapToInt(x -> x)
.max()
.getAsInt();
5. 字符串拼接测试
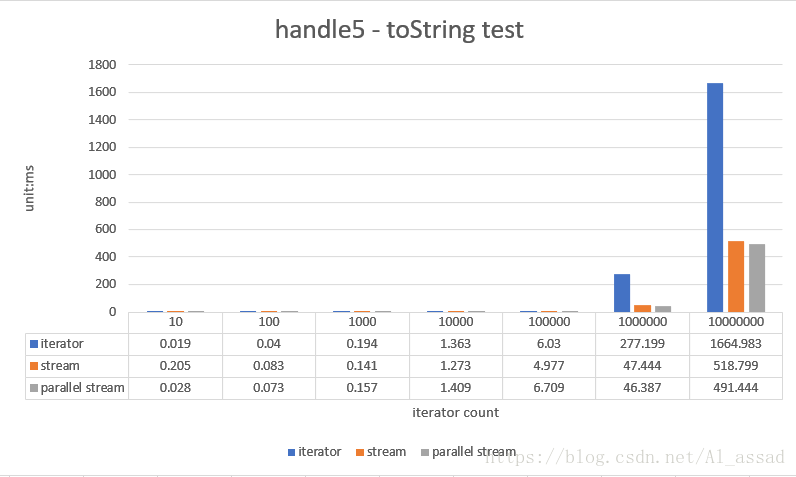
获取一个随机数列(List)各个元素使用“,”分隔的字符串,测试的随机数列容量从 10 - 10000000,跑10次取平均时间;
//stream
String result = list.stream().map(String::valueOf).collect(Collectors.joining(","));
//iterator
StringBuilder builder = new StringBuilder();
for(Integer e : list){
builder.append(e).append(",");
}
String result = builder.length() == 0 ? "" : builder.substring(0,builder.length() - 1);
//parallel stream
String result = list.stream().map(String::valueOf).collect(Collectors.joining(","));
6. 混合操作测试
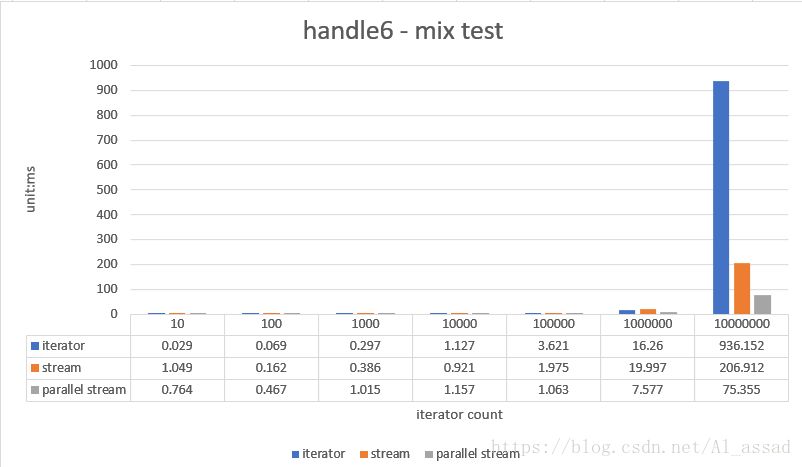
对一个随机数列(List)进行去空值,除重,映射,过滤,并组装为一个新的 List,测试的随机数列容量从 10 - 10000000,跑10次取平均时间;
//stream
List result = list.stream()
.filter(Objects::nonNull)
.mapToInt(x -> x + 1)
.filter(x -> x > 200)
.distinct()
.boxed()
.collect(Collectors.toCollection(ArrayList::new));
//iterator
HashSet set = new HashSet<>(list.size());
for(Integer e : list){
if(e != null && e > 200){
set.add(e + 1);
}
}
List result = new ArrayList<>(set);
//parallel stream
List result = list.parallelStream()
.filter(Objects::nonNull)
.mapToInt(x -> x + 1)
.filter(x -> x > 200)
.distinct()
.boxed()
.collect(Collectors.toCollection(ArrayList::new));
实验结果总结
从以上的实验来看,可以总结处以下几点:
-
在少低数据量的处理场景中(
size<=1000),stream的处理效率是不如传统的iterator外部迭代器处理速度快的,但是实际上这些处理任务本身运行时间都低于毫秒,这点效率的差距对普通业务几乎没有影响,反而stream可以使得代码更加简洁; -
在大数据量(
szie>10000)时,stream的处理效率会高于iterator,特别是使用了并行流,在cpu恰好将线程分配到多个核心的条件下(当然parallel stream底层使用的是 JVM 的ForkJoinPool,这东西分配线程本身就很玄学),可以达到一个很高的运行效率,然而实际普通业务一般不会有需要迭代高于10000次的计算; -
Parallel Stream受引 CPU 环境影响很大,当没分配到多个cpu核心时,加上引用forkJoinPool的开销,运行效率可能还不如普通的Stream;
使用 Stream 的建议
-
简单的迭代逻辑,可以直接使用
iterator,对于有多步处理的迭代逻辑,可以使用stream,损失一点几乎没有的效率,换来代码的高可读性是值得的; -
单核 cpu 环境,不推荐使用
parallel stream,在多核 cpu 且有大数据量的条件下,推荐使用paralle stream; -
stream中含有装箱类型,在进行中间操作之前,最好转成对应的数值流,减少由于频繁的拆箱、装箱造成的性能损失;
审核编辑:汤梓红
-
理解ECU数据流的分析方法2024-11-05 2392
-
JDK8升级JDK11最全实践干货来了2024-06-25 1660
-
Java8的Stream流 map() 方法2023-09-25 3196
-
如何解决JDK8小版本升级后性能下降的问题2021-07-26 5485
-
数据流是什么2019-02-27 8275
-
基于FPGA芯片的数据流结构分析2017-11-18 3105
-
网络数据流存储算法分析与实现2011-05-26 652
-
基于数据流的Java字节码分析2009-12-25 1164
-
基于数据流分析与识别的Web资源访问控制2009-04-09 549
-
本田数据流分析手册pdf2008-06-15 12365
全部0条评论

快来发表一下你的评论吧 !
