

对比学习在开放域段落检索和主题挖掘中的应用
描述
引言
对比学习是一种无监督学习方法。它的改进方向主要包括两个部分:1.改进正负样本的抽样策略 2.改进对比学习框架 本篇主要介绍了3篇源自ACL2022的有关对比学习的文章,前2篇文章涉及开放域段落检索,最后一篇文章涉及主题挖掘。
文章概览
1. Multi-View Document Representation Learning for Open-domain Dense Retrieval
开放域密集检索的多视图文档表示学习 论文地址:https://arxiv.org/pdf/2203.08372.pdf 密集检索通常使用bi-encoder生成查询和文档的单一向量表示。然而,一个文档通常可以从不同的角度回答多个查询。因此,文档的单个向量表示很难与多个查询相匹配,并面临着语义不匹配的问题。文章提出了一种多视图文档表示学习框架,通过viewer生成多个嵌入。
2. Sentence-aware Contrastive Learning for Open-Domain Passage Retrieval
开放域段落检索中的句子感知对比学习 论文地址:https://arxiv.org/pdf/2110.07524v3.pdf 一篇文章可能能够回答多个问题,这在对比学习中会导致严重的问题,文中将其称之为Contrastive Conflicts。基于此,文章提出了将段落表示分解为句子级的段落表示的方法,将其称之为Dense Contextual Sentence Representation (DCSR)。
3. UCTopic: Unsupervised Contrastive Learning for Phrase Representations and Topic Mining
基于短语表示和主题挖掘的无监督对比学习 论文地址:https://arxiv.org/pdf/2202.13469v1.pdf 高质量的短语表示对于在文档中寻找主题和相关术语至关重要。现有的短语表示学习方法要么简单地以无上下文的方式组合单词,要么依赖于广泛的注释来感知上下文。文中提出了UCTopic(an Unsupervised Contrastive learning framework for phrase representations and TOPIC mining),用于上下文感知的短语表示和主题挖掘。
论文细节
1

1-1
动机
密集检索在大规模文档集合的第一阶段检索方面取得了很大的进展,这建立在bi-encoder生成查询和文档的单一向量表示的基础上。然而,一个文档通常可以从不同的角度回答多个查询。因此,文档的单个向量表示很难与多个查询相匹配,并面临着语义不匹配的问题。文章提出了一种多视图文档表示学习框架,旨在生成多视图嵌入来表示文档,并强制它们与不同的查询对齐。为了防止多视图嵌入变成同一个嵌入,文章进一步提出了一个具有退火温度的全局-局部损失,以鼓励多个viewer更好地与不同潜在查询对齐。

1-2
模型
开放域段落检索是给定一个由数百万个段落组成的超大文本语料库,其目的是检索一个最相关的段落集合,作为一个给定问题的证据。密集检索已成为开放域段落检索的重要有效方法。典型的密集检索器通常采用双编码器结构,双编码器受制于单向量表示,面临表示能力的上界。在上图中,我们还发现单个向量表示不能很好地匹配多视图查询。该文档对应于反映不同观点的四个不同的问题,每个问题都匹配不同的句子和答案。为了解决这个问题,文章提出了Multi-View document Representations learning framework, MVR。
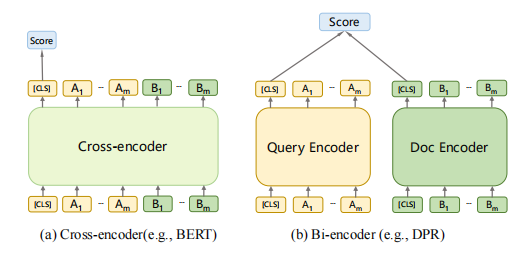
1-3 基于cross-encoder的模型需要计算昂贵的cross-attention,所以cross-encoder不用于第一阶段的大规模检索,而通常被用于第二阶段的排序中。在第一阶段检索中,bi-encoder是最常被采用的架构,因为它可以使用ANN加速。
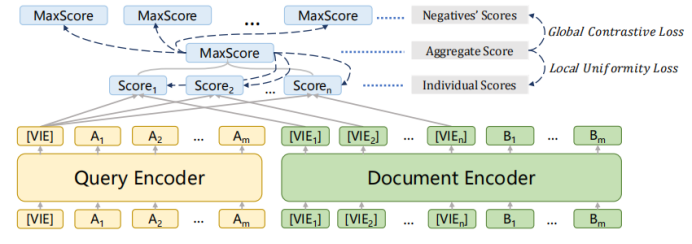
1-4 模型采用上述的bi-encoder结构,这种结构能够预先计算好query和document的向量,提升检索速度。Encoder采用bert。一些工作发现[CLS]能够汇集整个句子/文档的含义。为了获得更加精细的语义表示,使用多个[VIE]来替代[CLS],将[VIE]添加在文档的开头,为了避免多个[VIE]对原始输入句子位置编码的影响,将的位置id设置为0。由于查询比文档短得多,并且通常表示一个具体的含义,因此只为查询生成一个嵌入。查询和文档之间的相似度分数如下式计算,其中sim代表两个向量的内积。 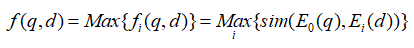 为了鼓励多个viewer更好地适应不同的潜在查询,文章提出了一个配备退火温度的全局-局部损失。损失函数:
为了鼓励多个viewer更好地适应不同的潜在查询,文章提出了一个配备退火温度的全局-局部损失。损失函数: 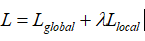 其中:
其中:
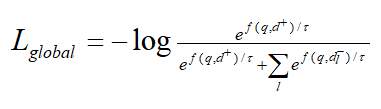
记文档正样本为d+,负样本为。全局对比损失继承自传统的bi-encoder结构。
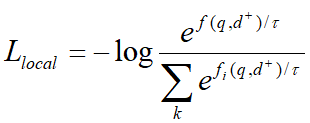
强制与query更加紧密的对齐,并与其他viewer区别开来。为了进一步鼓励更多不同的viewer被激活,文章采用了下式中的退火温度。 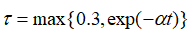 刚开始时,较大的能使得每个viewer被公平的选择,并从训练中返回梯度,随着训练的进行, 将降低,训练更加稳定。在推理中,构建所有文档嵌入的索引,然后利用近似最近邻ANN检索。
刚开始时,较大的能使得每个viewer被公平的选择,并从训练中返回梯度,随着训练的进行, 将降低,训练更加稳定。在推理中,构建所有文档嵌入的索引,然后利用近似最近邻ANN检索。
实验
数据集
实验采用的数据集包括Natural Questions ,TriviaQA,SQuAD Open。数据集 Natural Questions:是一个流行的开放域检索数据集,其中的问题是真实的谷歌搜索查询,答案是从维基百科中手动标注的。TriviaQA:包含了一系列琐碎的问题,其答案最初是从网上提取出来的。SQuADOpen:包含了来自阅读理解数据集的问题和答案,它已被广泛应用于开放域检索研究。
实验结果
计算不同文档对应的查阅数,在3个数据集上得到的平均值为2.7,1.5,1.2,这表明多视图问题是常见的。
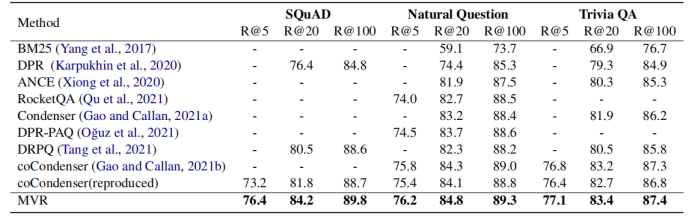
1-5 根据上表所示,MVR得到了最好的结果。MVR在SQuAD数据集上取得了最大的提升,这是因为该数据集单个文档对应更多的查询。这说明MVR比其他模型更能解决多视图问题。
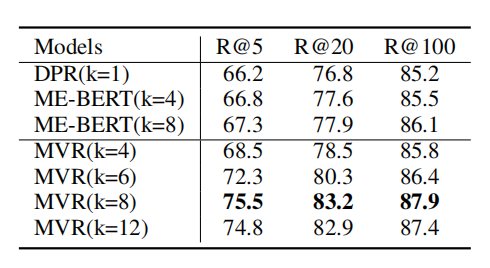
1-6
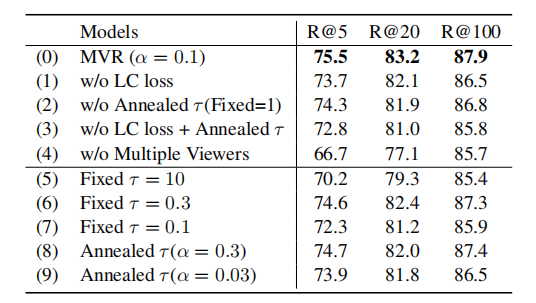
1-7
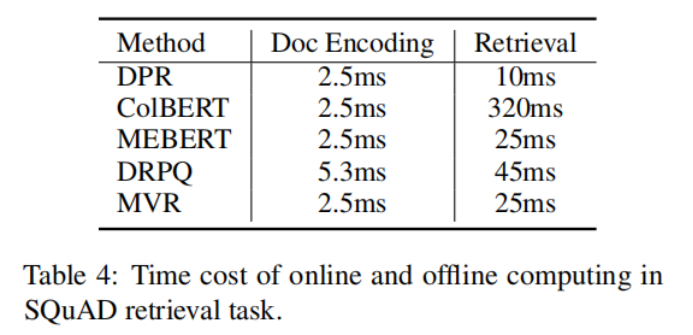
1-8 上表说明了,MVR与其他方法相比,需要的编码时间和检索时间较小。
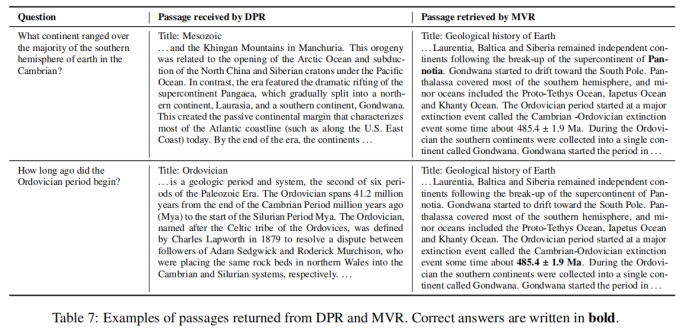
1-9 上表对DPR和MVR的检索结果进行了比较,结果表明MVR能够捕获更加细粒度的语义信息,返回正确的答案。
2

2-1
动机
本文的动机与上文基本相同。一个段落可能能够回答多个问题,这在对比学习框架中会导致严重的问题,文中将其称之为Contrastive Conflicts。这主要包括两个方面(1)相似性的转移,由于一个段落可能是多个问题的答案,当最大化对应段落和问题的相似性时,会同时让问题之间更为相似,但是这些问题在语义上不同。(2)在大批量上的多重标签。在大批量处理时,可能出现使得同一个段落为正的多个问题,在当前采用的技术中,该段落将被同时作为这些问题的正样本和负样本,这在逻辑上是不合理的。由于一对多问题是Contrastive Conflicts的直接原因,文章提出了将密集的段落表示分解为句子级的段落表示的方法,将其称之为Dense Contextual Sentence Representation (DCSR)。
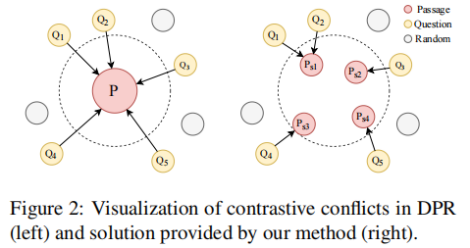
2-2
模型
Encoder采用bert结构。
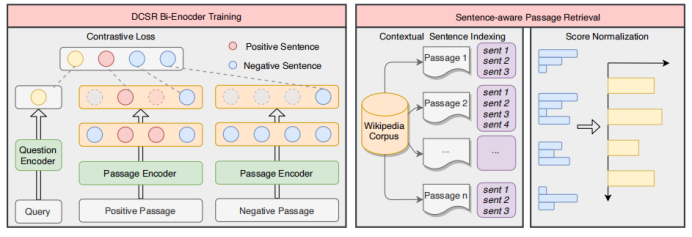
由于上下文信息在段落检索中也很重要,因此简单地将段落分解成句子并独立编码是不可行的。在输入文章的句子之间插入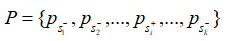 不包含答案的段落,将其表示为:
不包含答案的段落,将其表示为: 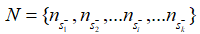 其中的+-代表句子中是否含有答案。文章使用BM25来检索每个问题的负段落。文章将包含答案的句子视为正样本(),并从BM25得到的负段落中随机抽取1个句子作为负样本。此外在包含答案的段落中随机抽取1个句子作为另一个负样本。 检索: 对于检索,使用FAISS来计算问题和所有段落句子之间的分数。由于一个段落在索引中含有多个键,则检索返回100*k(k是每篇文章的平均句子数量)个句子。之后,针对这些句子的分数,对它们执行softmax,从而将分数转化为概率。如果一篇passage中含有多个句子,,这些句子对应的概率为,则该篇passage为query答案的概率为:
其中的+-代表句子中是否含有答案。文章使用BM25来检索每个问题的负段落。文章将包含答案的句子视为正样本(),并从BM25得到的负段落中随机抽取1个句子作为负样本。此外在包含答案的段落中随机抽取1个句子作为另一个负样本。 检索: 对于检索,使用FAISS来计算问题和所有段落句子之间的分数。由于一个段落在索引中含有多个键,则检索返回100*k(k是每篇文章的平均句子数量)个句子。之后,针对这些句子的分数,对它们执行softmax,从而将分数转化为概率。如果一篇passage中含有多个句子,,这些句子对应的概率为,则该篇passage为query答案的概率为:
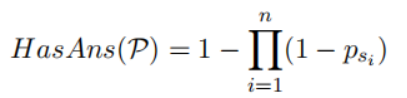
根据计算得到文章的概率,返回概率最高的top100 passage。
实验
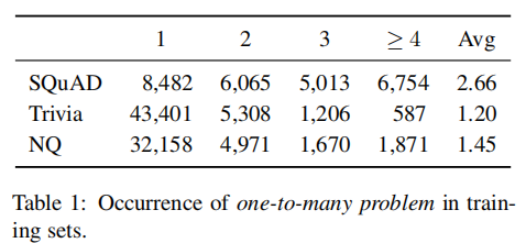
实验在SQuAD, TriviaQA,Natural Questions数据集上进行。下表统计了数据集中段落对应的问题数量。在SQuAD上的平均值最大,该数据集上Contrastive Conflicts的情况最严重,这与DPR在SQuAD上表现最差的事实相符。
2-4 对于模型而言,DCSR采用了和DPR相同的模型结构,没有引入额外的参数。在训练时,采用的负样本由随机抽样产生。因此DCSR带来的额外时间负担仅由抽样引起,这可以忽略不计。
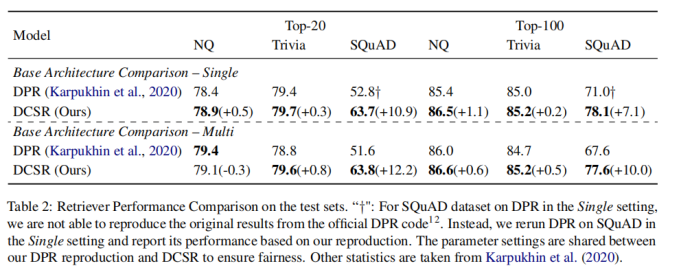
2-5 对在单数据集上的训练结果而言,上表显示DCSR取得了明显优于DPR的结果,特别是在SQuAD这样的受Contrastive Conflicts影响最严重的数据集上,对于受Contrastive Conflicts影响较小的数据集,也有较小的性能提升。对于在多数据集上的训练结果而言,DPR较DCSR指标下降的幅度更大,这表明DCSR还捕获了不同领域之间数据集的普遍性。
2-6
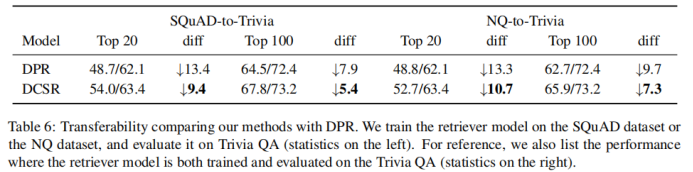
2-7 比较模型的可转移性。将DPR和DCSR在一个数据集上训练好后,迁移到另外一个数据集上做评估。可以发现,DCSR比DPR指标下降的幅度更小,模型的可转移性更好。
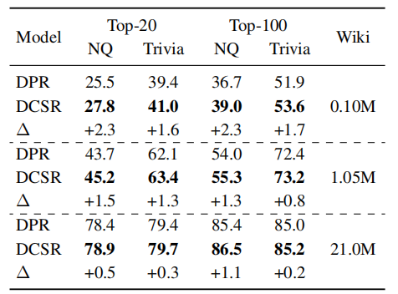
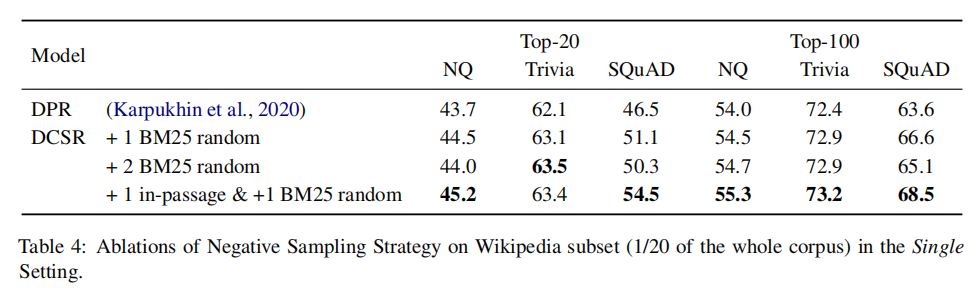
2-8 在不同大小的数据集上训练模型,发现DCSR与DPR相比,在任何大小的数据集上都表现得更好。与更大的数据集相比,在小的数据集上DCSR改进更显著。
3

3-1
动机
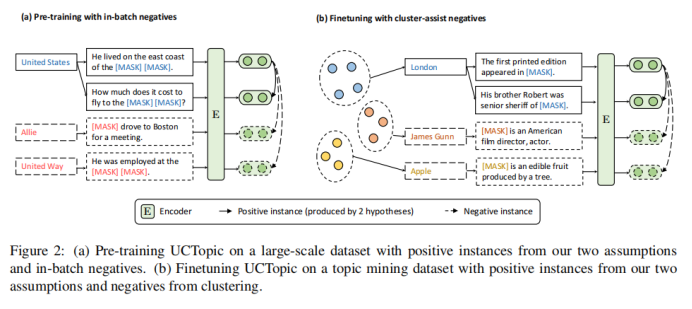
高质量的短语表示对于在文档中寻找主题和相关术语至关重要。现有的短语表示学习方法要么简单地以无上下文的方式组合单词,要么依赖于广泛的注释来感知上下文。文中提出了UCTopic(an Unsupervised Contrastive learning framework for phrase representations and TOPIC mining),用于感知上下文的短语表示和主题挖掘。UCTopic训练的关键是正负样本对的构建。文章提出了聚类辅助对比学习(CCL),它通过从聚类中选择负样本来减少噪声,并进一步改进了关于主题的短语表示。
模型
编码器结构
UCTopic的编码器采用LUKE (Language Understanding with Knowledge-based Embeddings)。
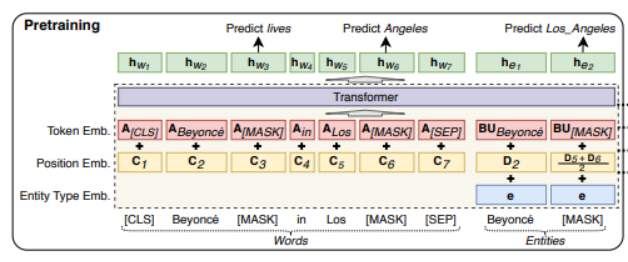
3-2 Luke采用transformer结构。它将文档中的单词和实体都作为输入token,并为每个token计算presentation。形式上,给定一个由m个词和n个实体组成的序列,为其计算,其中, 其中 。Luke的输入由三部分组成。Input embedding=position embedding+token embedding+entity type embedding (1)token embedding (2) position embedding 出现在序列中第i位的单词和实体分别用和表示。如果一个实体包含多个单词,则将相应位置的embedding进行平均来计算position embedding。(3)Entity type embedding 表示token是否一个实体。
Entity-aware Self-attention
因为luke处理两种类型的标记,所以在计算注意力分数的时候考虑token的类型。
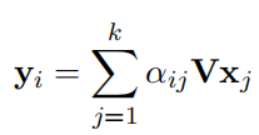
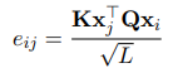
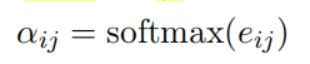
UCTopic
与预测实体的LUKE不同,UCTopic是通过短语上下文的对比学习训练的。因此,来自UCTopic的短语表示具有上下文感知能力,并且对不同的领域非常健壮。
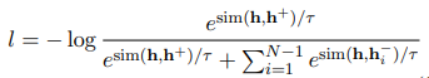
UCTopic采用对比学习的框架进行无监督学习。文中提出了关于短语语义的两个假设来获得正负样本对:1.短语语义由它的上下文决定。mask所提到的短语会迫使模型从上下文中学习表示,从而防止过拟合和表示崩溃 2.相同的短语有相同的语义
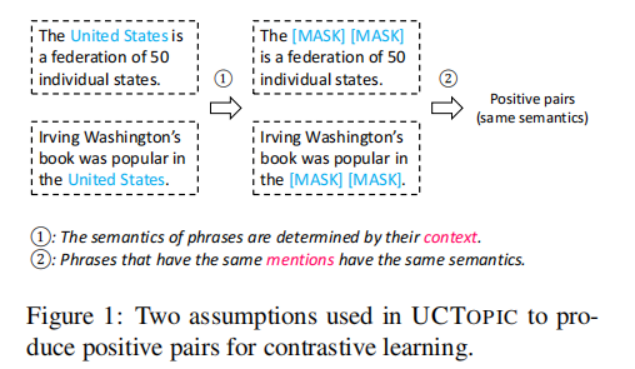
3-4
假设一个文档内有3个主题,假设批量大小是32,因此一个批量内会有一些样本来自同一个主题,但是在之前的处理方法中这些样本都被处理成负样本,这会导致性能下降。为了根据主题优化短语表示,减小噪声。文章提出了聚类辅助对比学习(CCL),其基本思想是利用pre-trained representation和聚类的先验知识来减少负样本中存在的噪声。具体来说,对预训练的短语表示使用聚类算法。每一类的质心被认为是短语的主题表示。在计算了短语和质心之间的余弦距离后,选择接近质心的t%实例,并为它们分配伪标签。短语自身的伪标签由包含该短语的实例的投票决定。假设一个主题集C,其中包含伪标签和短语。对于主题,构造正样本。随机选择来自其他主题的短语作为训练的负样本。微调时训练的损失函数如下:
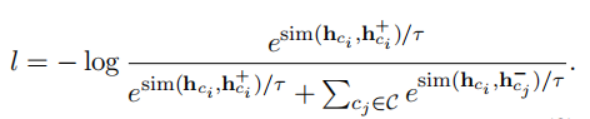
为了推断短语实例x的主题y,计算短语表示h和主题表示之间的距离,与短语x最近的主题被认为是短语属于的主题。
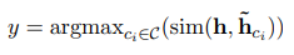
UCTopic的Pre-training与Finetuning示意图如下:
3-5
实验
训练语料库使用Wikipedia,并将其中带有超链接的文本作为短语。经过处理后,预训练数据集有1160万个句子和1.088亿个训练实例。预训练采用两个损失函数:一个是masked language model loss,另一个是前面的对比学习损失。
实体聚类
3-6
与其他的微调方法相比,CCL微调可以通过捕获特定于数据的特征来进一步改进预先训练好的短语表示。
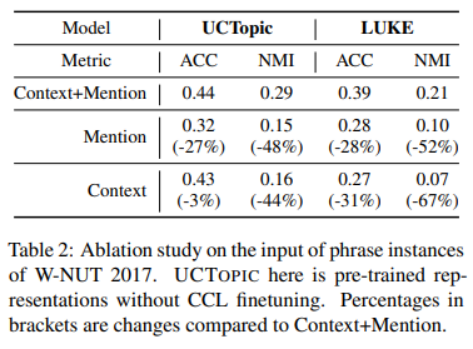
3-7
主题词挖掘
通过计算轮廓系数来获得每个数据集的主题数量。
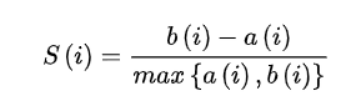
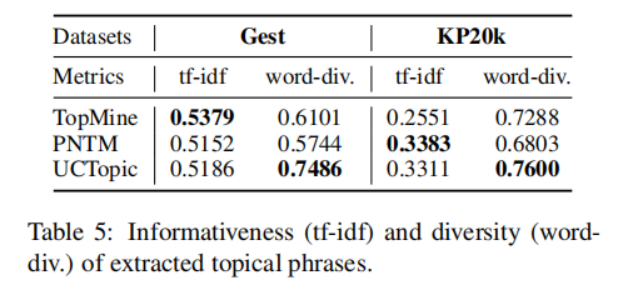
3-8 是第i个点到与i相同聚类中其他点的平均距离,是第i个点到下一个最近簇中的点的平均距离。具体来说,从数据集中随机抽取10K个短语,并对预训练过的短语应用K-means聚类。计算不同主题数量的轮廓系数得分;得分最大的数字将被用作数据集中的主题数量。之后利用CCL对数据集进行微调。主题短语评估:(1)主题分离:通过短语入侵任务来评估,具体来说,是从一系列短语中发掘与其他短语所属主题不同的短语。(2)短语连贯性:要求注释者评估一个主题中的前50个短语是否有连贯性。(3)短语信息量和多样性。高信息量的短语不是语料库中常见的短语。使用tf-idf来评估一个短语的信息量。短语的多样性通过计算出现的词的种类与出现词的数量的比值来评估。UCtopic的多样性最强,说明了UCtopic的短语表示具有上下文感知能力。
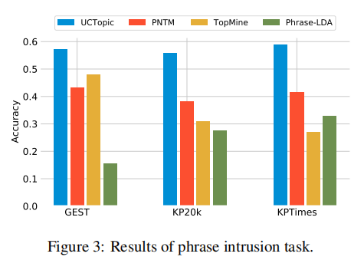
3-9
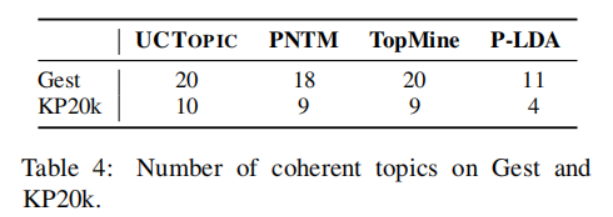
3-10
3-11
审核编辑 :李倩
-
无监督域自适应场景:基于检索增强的情境学习实现知识迁移2023-12-05 1703
-
机器学习与数据挖掘的对比与区别2023-08-17 2676
-
深度学习在轨迹数据挖掘中的应用研究综述2022-03-08 2802
-
基于注意力机制的跨域服装检索方法综述2021-06-27 914
-
文本挖掘之概率主题模型综述2021-06-24 1034
-
私有二进制协议中变长域的格式挖掘综述2021-06-15 878
-
《机器学习与数据挖掘:方法和应用》2018-06-27 998
-
TF-IDF算法的改进及在语义检索中应用2018-01-02 1317
-
基于主题词的文本案例检索算法研究2017-12-13 893
-
海量信息检索挖掘及视觉三维展现方法仿真2017-01-07 620
全部0条评论

快来发表一下你的评论吧 !
