

队列Queue的常用方法有哪些
描述
队列-Queue
FIFO(先入先出)队列Queue,LIFO(后入先出)队列LifoQueue,和优先级队列PriorityQueue。
常用方法:
Queue.qsize() 返回队列的大小
Queue.empty() 如果队列为空,返回True,反之False
Queue.full() 如果队列满了,返回True,反之False,Queue.full 与 maxsize 大小对应
Queue.get(item) 获取队列
Queue.get_nowait() 相当于Queue.get(False),非阻塞方法
Queue.put(item) 写入队列
Queue.task_done() 在完成一项工作之后,Queue.task_done()函数向任务已经完成的队列发送一个信号。每个get()调用得到一个任务,接下来task_done()调用告诉队列该任务已经处理完毕。
Queue.join() 实际上意味着等到队列为空,再执行别的操作
Queue队列方法主要用于我们的进程间的通信。
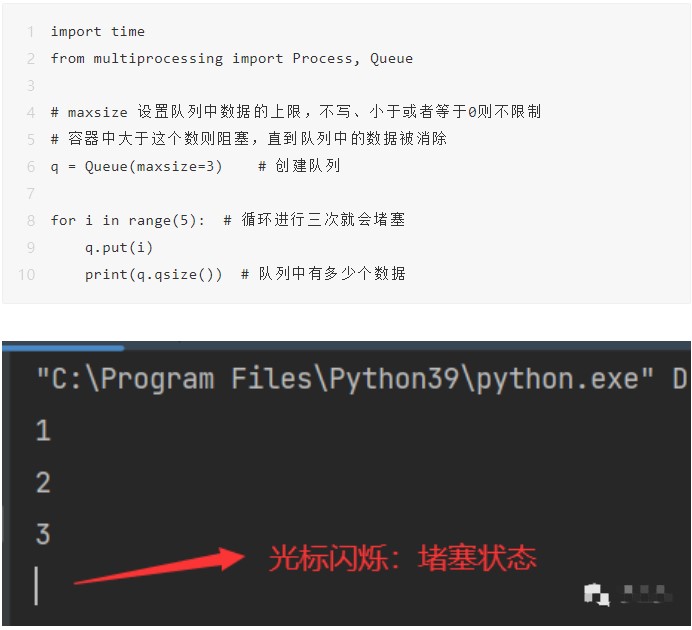

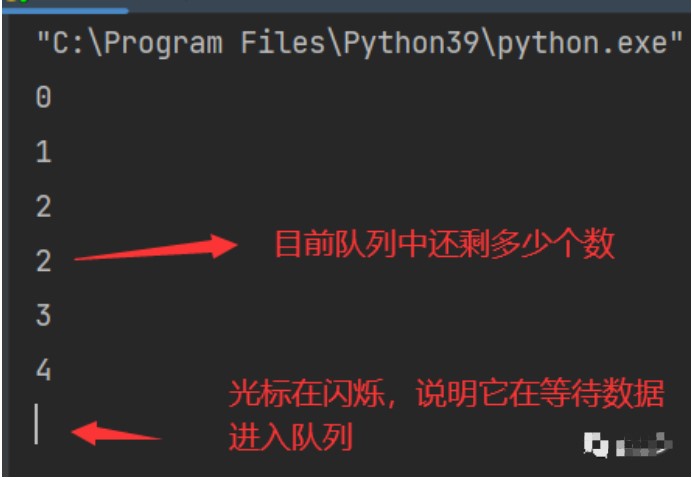
进程中的通信一个最主要的用途就是用于日后的爬虫,当我们需要爬取5000个网页的时候,我们需要从浏览器首页获取所有的静态资源(检查网页代码),然后再通过内容提取来提取出其中的URL(全局资源定位符),比如:www.baidu.com,这就和生产者消费者模型很相似。
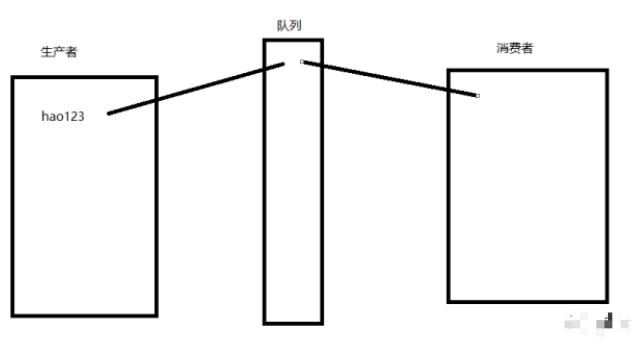
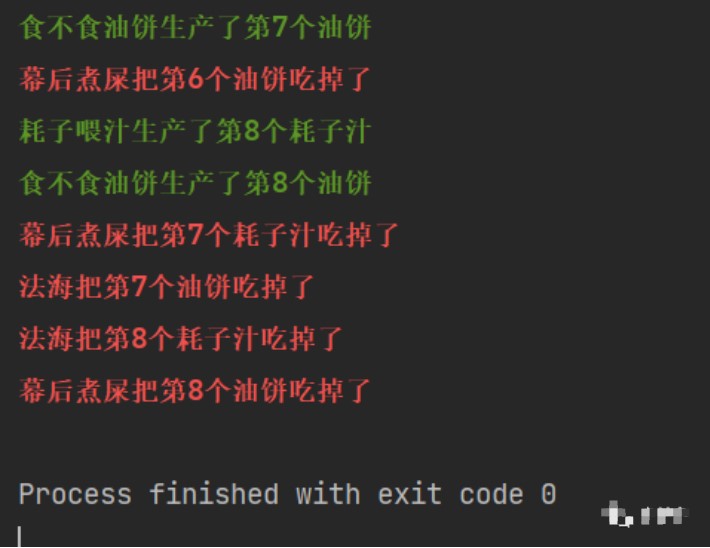
我们来简单实现"生产者消费者模型":


进程池-Pool
一、什么是进程池?
在程序实际处理问题过程中,忙时会有成千上万的任务需要被执行,闲时可能只有零星任务。那么在成千上万个任务需要被执行的时候,我们就需要去创建成千上万个进程么?首先,创建进程需要消耗时间,销毁进程也需要消耗时间。第二即便开启了成千上万的进程,操作系统也不能让他们同时执行,这样反而会影响程序的效率。因此我们不能无限制的根据任务开启或者结束进程。那么我们要怎么做呢?
进程池就是先定义一个池子,在里面放上固定数量的进程,有需求来了,就拿一个池中的进程来处理任务,等到处理完毕,进程并不关闭,而是将进程再放回进程池中继续等待任务。如果有很多任务需要执行,池中的进程数量不够,任务就要等待之前的进程执行任务完毕归来,拿到空闲进程才能继续执行。也就是说,池中进程的数量是固定的,那么同一时间最多有固定数量的进程在运行。这样不会增加操作系统的调度难度,还节省了开闭进程的时间,也一定程度上能够实现并发效果。
二、程序类型
我们的程序有两种:计算密集型、IO密集型
计算密集型:充分利用CPU,多线程可以充分利用多核(适合开启多进程,但不适合开启很多)
IO密集型:大部分的时间都在阻塞队列,而不是在运行状态(根本不适合开启多进程)

信号量和多进程的处理方式的差异在于,每n个信号量是同步的,也就是说,如果只设置了4个信号量,4个用户先抢占了CPU,那剩余的496个任务量需要等待前面4个用户完成了(100%)之后才能够继续进行。而多进程是异步的,但是由于计算机的CPU有限,采用时间片轮转法进行分配工作,所有的进程都有机会同时开始任务,但一段(细微)时间后,时间片就会分配给其他进程,这样宏观上看起来它是同时进行的,但其中涉及到了非常多的计算机的进程调度,但是信号量和多进程的处理时间需要视情况而定。
进程池在面对这种(做500件衣服)计算密集型的程序时具有非常高的效率,使用进程池不涉及进程调度,也就不浪费时间,属于流水线式24h昼夜不息工作模式,做完一件衣服立马就会接手第二件、第三件......这种方式充分地利用了CPU,不会在创建进程、进程调度、销毁进程中浪费时间。



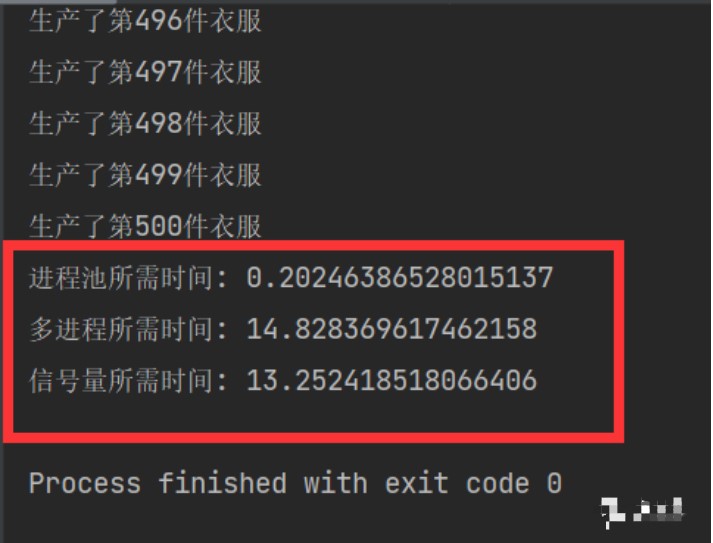
从结果来看,我们可以发现,进程池的速度与多进程和信号量比起来那是相当的哇塞。所以该用哪种方法不用多说了吧。
审核编辑:刘清
-
韦东山freeRTOS系列教程之队列(queue)(5)2021-12-13 7186
-
Linux下进程通讯消息队列2022-08-19 3445
-
RAW queue 篇2013-02-27 4935
-
Queue队列的作用是什么2022-02-14 650
-
消息队列Queue相关资料推荐2022-02-22 927
-
请问为什么给queue数据队列画成了环形呢?2023-03-09 1601
-
网络中常用的队列管理方法比较2009-05-25 634
-
Java多线程总结之Queue2017-11-28 4011
-
ThreadX(九)------消息队列Queue2021-12-28 1323
-
STM32G0开发笔记:使用FreeRTOS系统的队列Queue2023-01-16 2609
-
什么是queue?2023-02-27 3610
-
FreeRTOS消息队列结构体2023-07-06 2328
-
RTOS中Queue的工作原理2023-07-25 5750
-
用队列实现栈的两种方法2023-10-08 1422
-
OpenHarmony语言基础类库【@ohos.util.Queue (线性容器Queue)】2024-04-27 1040
全部0条评论

快来发表一下你的评论吧 !
