

FLAT的一种改进方案
描述
许久没有更新,今天来水一篇之前在arXiv上看到的论文,这篇NFLAT是对FLAT的改进(其实也是对TENER的改进),FLAT在文本后面挂单词的方式可能会导致文本长度过长,论文中讲长度平均会增加40%,从而导致:
self-attention的时候计算量和显存占用量增大,限制了FLAT对更大更复杂的词表的使用;
有一些冗余计算,比如“word-word”和“word-character”级别的self attention是没有必要做的,因为在FLAT中word部分在解码的时候会被mask掉(如下图),不参与后续计算,所以只需要"character-character"和“character-word”级别的self-attention。
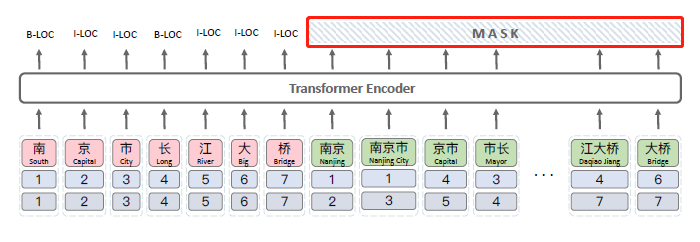 FLAT中word部分在解码的时候会被MASK掉
FLAT中word部分在解码的时候会被MASK掉
其实讲到这里,相信读者们也看出来了,改进思路已经比较明显了:既然只要"character-character"和“character-word”级别的self-attention,那么就拆开搞,「不要把word往句子后面拼了,而是character有一个序列(原始文本序列),word有一个序列(原始文本序列在外部词表中匹配出来的单词序列)」:
先进行“character-word”的attention,获得融合了word边界和语义信息的character表征——论文中称这部分叫「InterFormer」;
再做"character-character"级别的self-attention,获取最终character表征——「Transformer Encoder」,论文这部分用的TENER对Transformer Encoder的改动,所以其实这篇论文也是对TENER的改进方案,「是TENER+外部词典的解决方案」。
Linear Project + CRF
模型分为上面所说的三个模块,接下来我们一个一个介绍。
模型
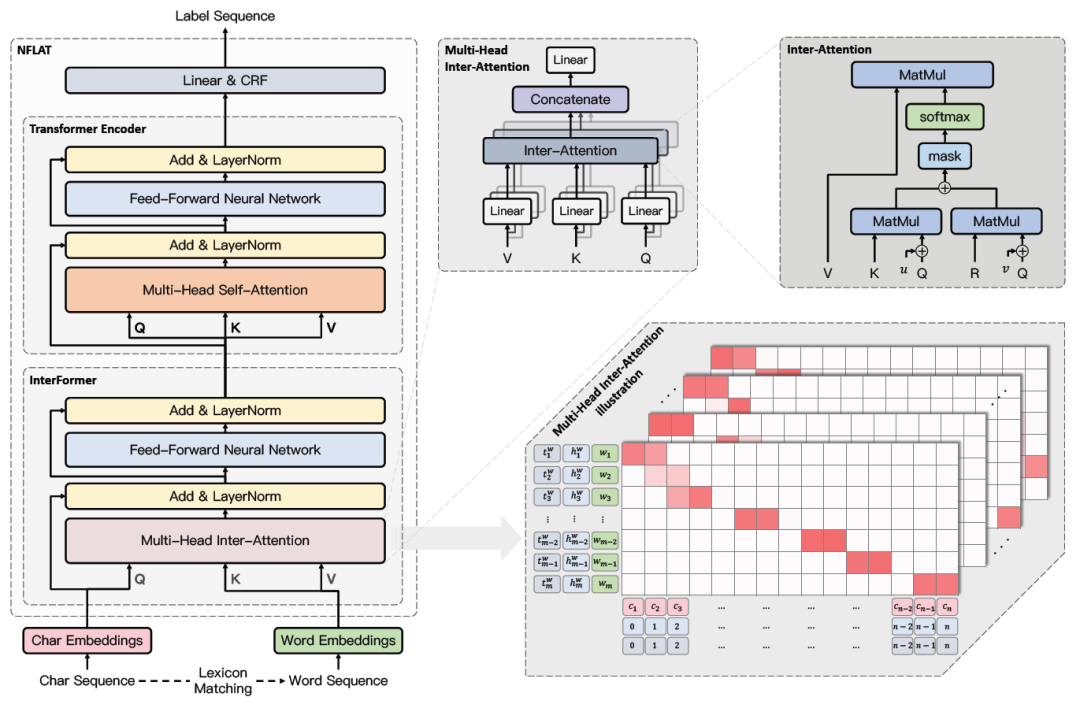 NFLAT模型结构
NFLAT模型结构
1. InterFormer
其实就是Transformer Encoder的改进版,InterFormer包含多头inter-attention和一个FFN,目的是构建non-flat-lattice,可以同时对character和word两个不同长度的序列进行建模,让他们交互,从而获得融合了word边界和语义信息的character表征。
对Transformer Encoder的改进主要是:
「attention中query/key/value不再同源」,也就不再是self-attention,「character序列作为query的输入,word序列作为key和value的输入」。这样的话attention在character序列中每个字上的输出就是word序列中与这个字相关的word表征(value)的加权求和的结果。
他们在word序列中加入了一个标记
「参考了TransformerXL和FLAT中的相对位置编码部分,同时做了一些改动」。
下面直接列公式了:
输入:character序列embedding ,word序列embedding。
获取QKV表征:
计算Inter-Attention
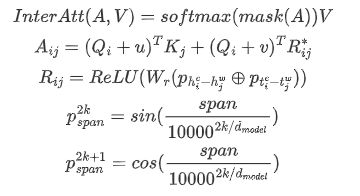
是attention中常规操作,就是对序列中padding部分的score赋一个很小的值,让softmax后结果为0的;
的计算方法参考了TransformerXL,只是相对距离的表征的计算方式不太一样,是参考FLAT,但也做了一些改动,FLAT中计算了四种位置距离表征:head-head, head-tail, tail-head, tail-tail,但这里只有两种位置距离:character head - word head ()和 character tail - word tail ()。
同样这个Inter-attention也可以做成multi-head attention的方式:
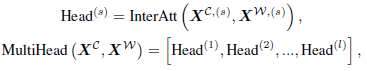
然后是FFN、残差连接、PostNorm
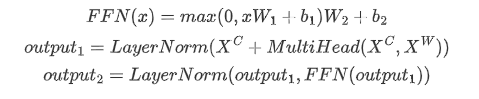
通过上面的这一系列操作,我们就获得了“「融合了word边界和语义信息的character表征」”。
2. Transformer Encoder
然后进行"character-character"级别的上下文编码,用TENER中改造的Transformer Encoder,也就是两部分改动:
Un-scaled Dot-Product Attention,TENER中发现不进行scale的attention比进行了scale的在NER上的效果要好;
使用了对方向和距离敏感的相对位置编码,其实和上面Inter-attention中相对位置编码差不多,就是就只有query位置-value位置。
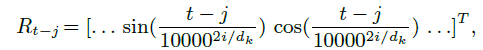
所以NFLAT其实就是在TENER前面加了一个模块。
3. 最后就是CRF层
实验结果
数据:
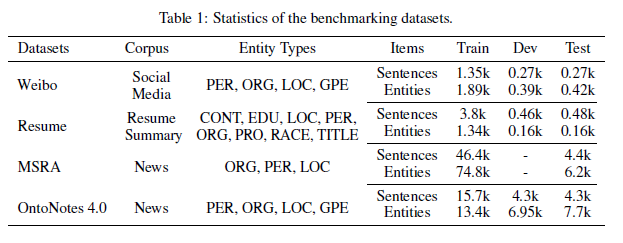 数据集
数据集
外部词表:
外部词表他们主要采用了:https://github.com/jiesutd/RichWordSegmentor
结果:
如下图,可以看到,NFLAT在4个数据集上效果都还挺好的,达到了SOTA。
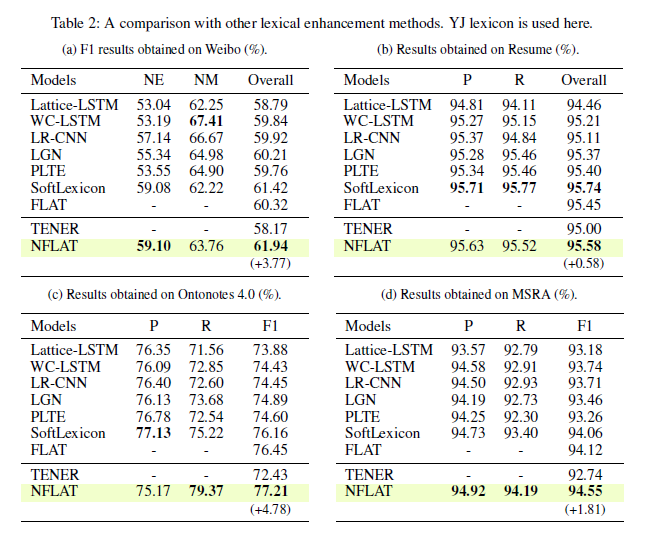 实验结果
实验结果
效率分析
时间复杂度:
n是character序列长度,m是word序列的长度,一般n越长,m越长,所以看复杂度的话NFLAT还是降低了许多了,作者们还做了相关的实验,每种长度挑选1000个句子,用batch_size=1计算跑完1k条句子的时间(3090的卡),发现句子长度大于400的时候,NFLAT与FLAT的速度才会有差距。
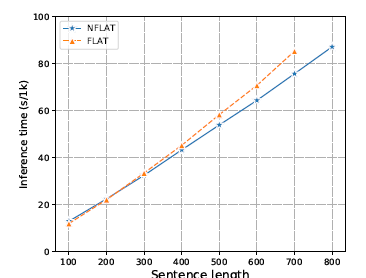 运行时间对比
运行时间对比
FLAT:
NFLAT:
空间复杂度:
显存占用还是有明显差别的:
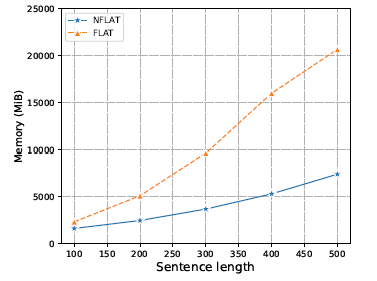 显存占用对比
显存占用对比
FLAT:O((n+m)^{2})
NFLAT:
差不多,这篇论文就到这里吧。
-
一种基于自适应邻域策略的改进算法2021-06-27 1153
-
一种改进的web威胁态势力分析方法2021-06-08 862
-
分享一种DTMF信号检测器工程的应用方案2021-06-03 1728
-
一种改进的MIMOOFDM帧同步算法.pdf2018-04-19 1083
-
一种改进的自由搜索算法_任诚2017-03-14 1250
-
基于一种改进PSO辨识算法的DOB设计_陈鹏亮2017-01-21 924
-
一种改进的邻近粒子搜索算法2017-01-07 731
-
Whirlpool的一种改进算法2011-11-30 624
-
一种改进的AODV路由算法设计2011-05-26 1003
-
一种改进的各向异性高斯滤波算法2010-04-23 539
-
一种改进的TPM检测方案2010-03-01 757
-
一种改进的强代理签名方案2009-08-13 659
-
恒流源的一种改进电路电路图2009-07-01 976
-
一种消息恢复型数字签名方案的改进2009-04-23 812
全部0条评论

快来发表一下你的评论吧 !
