

基于中文数据的标签词构造过程
描述
一、简介
在UIE出来以前,小样本NER主要针对的是英文数据集,目前主流的小样本NER方法大多是基于prompt,在英文上效果好的方法,在中文上不一定适用,其主要原因可能是:
中文长实体相对英文较多,英文是按word进行切割,很多实体就是一个词;边界相对来说更清晰;
生成方法对于长实体来说更加困难。但是随着UIE的出现,中文小样本NER 的效果得到了突破。
二、主流小样本NER方法
2.1、EntLM
EntLM该方法核心思想:抛弃模板,把NER作为语言模型任务,实体的位置预测为label word,非实体位置预测为原来的词,该方法速度较快。模型结果图如图2-1所示:
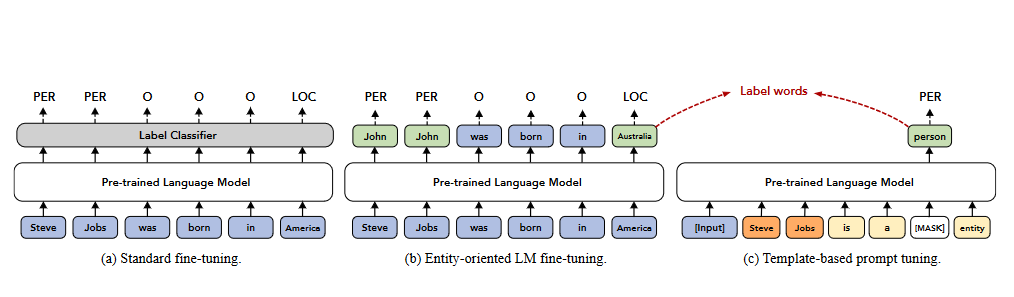 图2-1 EntLM模型
图2-1 EntLM模型
论文重点在于如何构造label word:在中文数据上本实验做法与论文稍有区别,但整体沿用论文思想:下面介绍了基于中文数据的标签词构造过程;
采用领域数据构造实体词典;
基于实体词典和已有的实体识别模型对中文数据(100 000)进行远程监督,构造伪标签数据;
采用预训练的语言模型对计算LM的输出,取实体部分概率较高的top3个词;
根据伪标签数据和LM的输出结果,计算词频;由于可能出现在很多类中都出现的高频标签词,因此需要去除冲突,该做法沿用论文思想;
使用均值向量作为类别的原型,选择top6高频词的进行求平均得到均值向量;
2.2、TemplateNER
TemplateNER的核心思想就是采用生成模型的方法来解决NER问题,训练阶段通过构造模板,让模型学习哪些span是实体,哪些span不是实体,模板集合为:$T=[T+,T+ ...T+,T-]$,T+为xx is aentity,T-为 xx is not aentity,训练时采用目标实体作为正样本,负样本采用随机非实体进行构造,负样本的个数是正样本的1.5倍。推理阶段,原始论文中是 n-gram 的数量限制在 1 到 8 之间,作为实体候选,但是中文的实体往往过长,所以实验的时候是将,n-gram的长度限制在15以内,推理阶段就是对每个模板进行打分,选择得分最大的作为最终实体。
这篇论文在应用中的需要注意的主要有二个方面:
模板有差异,对结果影响很大,模板语言越复杂,准确率越低;
随着实体类型的增加,会导致候选实体量特别多,训练,推理时间更,尤其在句子较长的时候,可能存在效率问题,在中文数据中,某些实体可能涉及到15个字符(公司名),导致每个句子的候选span增加,线上使用困难,一条样本推理时间大概42s
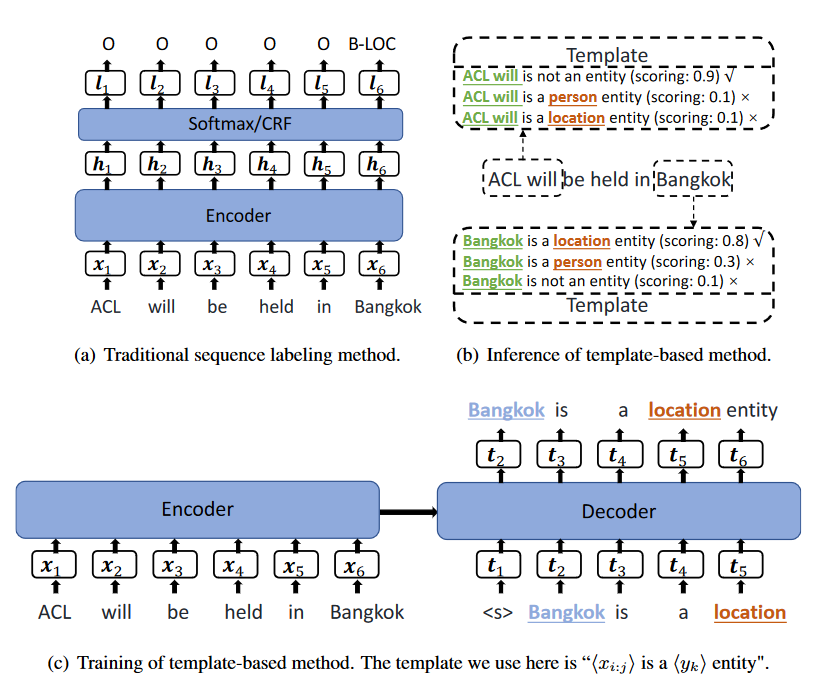 图2-2 TemplateNER抽取模型
图2-2 TemplateNER抽取模型
2.3、LightNER
LightNER的核心思想采用生成模型进行实体识别,预训练模型采用 BART通过 prompt 指导注意力层来重新调整注意力并适应预先训练的权重, 输入一个句子,输出是:实体的序列,每个实体包括:实体 span 在输入句子中的 start index,end index ,以及实体类型 ,该方法的思想具有一定的通用性,可以用于其他信息抽取任务。
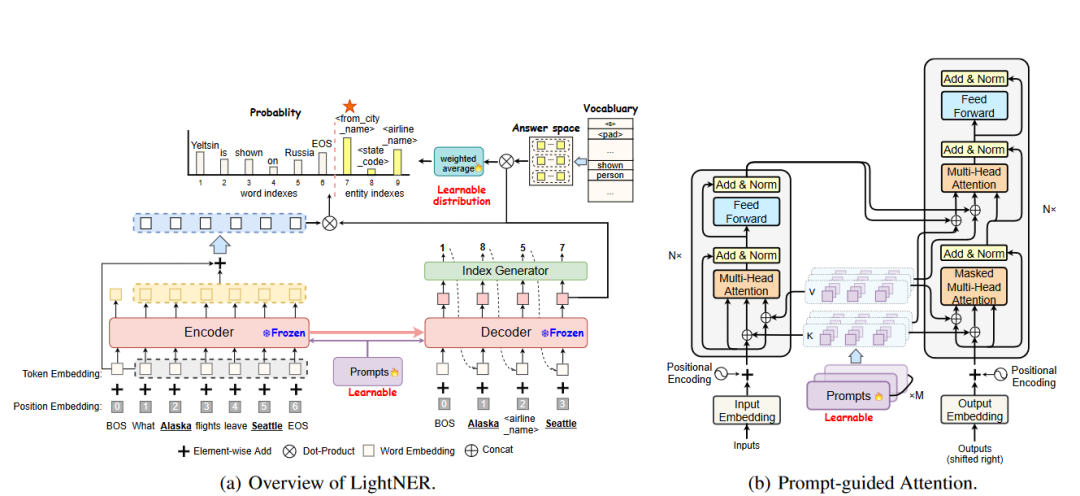 图2-3 LightNER抽取模型
图2-3 LightNER抽取模型
2.4、UIE
UIE(通用信息抽取框架)真正的实现其实是存在两个版本,最初是中科院联合百度发的ACL2022的一篇论文,Unified Structure Generation for Universal Information Extraction,这个版本采用的是T5模型来进行抽取,采用的是生成模型,后来百度推出的UIE信息抽取框架,采用的是span抽取方式,直接抽取实体的开始位置和结束位置,其方法和原始论文并不相同,但是大方向相同。
输入形同:UIE采用的是前缀prompt的形式,采用的是Schema+Text的形式作为输入,文本是NER任务,所以Schema为实体类别,比如:人名、地名等。
采用的训练形式相同,都是采用预训练加微调的形式
不同点:
百度UIE是把NER作为抽取任务,分别预测实体开始和结束的位置,要针对schema进行多次解码,比如人名进行一次抽取,地名要进行一次抽取,以次类推,也就是一条文本要进行n次,n为schema的个数,原始UIE是生成任务,一次可以生成多个schema对应的结果
百度UIE是在ernie基础上进行预训练的,原始的UIE是基于T5模型。
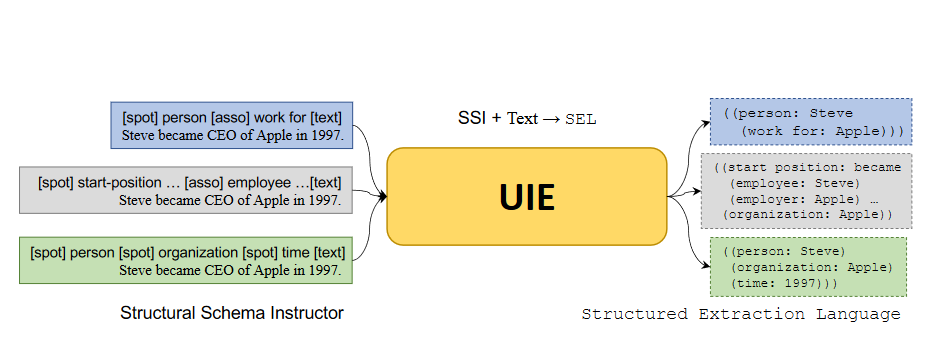 图2-4 UIE抽取模型
图2-4 UIE抽取模型
三、实验结果
该部分主要采用主流小样本NER模型在中文数据上的实验效果。
通用数据1测试效果:
| Method | 5-shot | 10-shot | 20-shot | 50-shot |
|---|---|---|---|---|
| BERT-CRF | - | 0.56 | 0.66 | 0.74 |
| LightNER | 0.21 | 0.42 | 0.57 | 0.73 |
| TemplateNER | 0.24 | 0.44 | 0.51 | 0.61 |
| EntLM | 0.46 | 0.54 | 0.56 | - |
从实验结果来看,其小样本NER模型在中文上的效果都不是特别理想,没有达到Bert-CRF的效果,一开始怀疑结果过拟了,重新换了测试集,发现BERT-CRF效果依旧变化不大,就是比其他的小样本学习方法好。
3.1、UIE实验结果
UIE部分做的实验相对较多,首先是消融实验,明确UIE通用信息抽取的能力是因为预训练模型的原因,还是因为模型本身的建模方式让其效果好,其中,BERTUIE,采用BERT作为预训练语言模型,pytorch实现,抽取方式采用UIE的方式,抽取实体的开始和结束位置。
领域数据1测试结果(实体类型7类):
| 预训练模型 | 框架 | F1 | Epoch |
|---|---|---|---|
| Ernie3.0 | Paddle | 0.71 | 200 |
| Uie-base | paddle | 0.72 | 100 |
| BERT | pytorch | 0.705 | 30 |
从本部分实验可以确定的是,预训练模型其实就是一个锦上添花的作用, UIE的本身建模方式更重要也更有效。
领域数据1测试结果(实体类型7类):
| 5-shot | 10-shot | 20-shot | 50-shot | |
|---|---|---|---|---|
| BERT-CRF | 0.697 | 0.75 | 0.82 | 0.85 |
| 百度UIE | 0.76 | 0.81 | 0.84 | 0.87 |
| BERTUIE | 0.73 | 0.79 | 0.82 | 0.87 |
| T5(放宽后评价) | 0.71 | 0.75 | 0.79 | 0.81 |
领域数据3测试效果(实体类型6类),20-shot实验结果:
| BERT-CRF | LightNER | EntLM | 百度UIE | BERTUIE | |
|---|---|---|---|---|---|
| F1 | 0.69 | 0.57 | 0.58 | 0.72 | 0.69 |
UIE在小样本下的效果相较于BERT-CRF之类的抽取模型要好,但是UIE的速度较于BERT-CRF慢很多,大家可以根据需求决定用哪个模型。如果想进一步提高效果,可以针对领域数据做预训练,本人也做了预训练,效果确实有提高。
-
面向短文本的中文真词错误检测与修复2021-06-08 933
-
Chrome新增一项功能 部分标签页可显示该页面关键词2020-04-15 4004
-
中文分词研究难点-词语切分和语言规范2019-09-04 2671
-
Python数据挖掘:WordCloud词云配置过程及词频分析2018-09-14 4675
-
基于标签优先的抽取排序方法2017-12-25 942
-
基于强度熵解决中文关键词识别2017-11-24 1074
-
计算机程序的构造和解释中文版2015-01-04 589
-
标签不能输入中文,应该怎么解决?2014-12-26 13497
-
为什么要添加标签呢?添加标签对你有什么好处2014-09-29 4833
-
量子Fourier变换构造FQT电路2010-05-31 429
-
铝电解的构造和生产过程2009-10-07 2023
全部0条评论

快来发表一下你的评论吧 !
