

RAKE算法原理介绍
描述
RAKE简介
RAKE英文全称为Rapid Automatic keyword extraction,中文称为快速自动关键字提取,是一种非常高效的关键字提取算法,可对单个文档进行操作,以实现对动态集合的应用,也可非常轻松地应用于新域,并且在处理多种类型的文档时也非常有效。
2
算法思想
RAKE算法用来做关键词(keyword)的提取,实际上提取的是关键的短语(phrase),并且倾向于较长的短语,在英文中,关键词通常包括多个单词,但很少包含标点符号和停用词,例如and,the,of等,以及其他不包含语义信息的单词。
RAKE算法首先使用标点符号(如半角的句号、问号、感叹号、逗号等)将一篇文档分成若干分句,然后对于每一个分句,使用停用词作为分隔符将分句分为若干短语,这些短语作为最终提取出的关键词的候选词。
最后,每个短语可以再通过空格分为若干个单词,可以通过给每个单词赋予一个得分,通过累加得到每个短语的得分。一个关键点在于将这个短语中每个单词的共现关系考虑进去。最终定义的公式是:
3
算法步骤
(1)算法首先对句子进行分词,分词后去除停用词,根据停 用词划分短语;
(2)之后计算每一个词在短语的共现词数,并构建 词共现矩阵;
(3)共现矩阵的每一列的值即为该词的度deg(是一个网络中的概念,每与一个单词共现在一个短语中,度就加1,考虑该单词本身),每个词在文本中出现的次数即为频率freq;
(4)得分score为度deg与频率 freq的商,score越大则该词更重 ;
(5)最后按照得分的大小值降序 输出该词所在的短语。
下面我们以一个中文例子具体解释RAKE算法原理,例如“系统有声音,但系统托盘的音量小喇叭图标不见了”,经过分词、去除停用词处理 后得到的词集W = {系统,声音,托盘,音量,小喇叭,图标,不见},短语集D={系统,声音,系统托盘,音量小喇叭图标不见},词共现矩阵如表: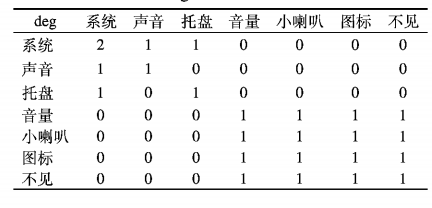
每一个词的度为deg={"系统”:2,“声音”:1,“托盘”:1; “音量” :3; “小喇叭” :3,“图标” :3,“不见” :3},频率freq = { “系统” :2, “声音” :1, “托盘” :1 ;“音量” :1;“小喇叭” :1, “图标”丄“不见” :1}, score ={“系统”:1,“声音”:1,“托 盘” :1 ;“音量” :1小喇叭” :3, “图标” :3, “不见” :3 },输出结果为{音量小喇叭图标不见 ,系统托盘,系统,声音}
4
代码实现
import string
from typing import Dict, List, Set, Tuple
PUNCTUATION = string.punctuation.replace(''', '') # Do not use apostrophe as a delimiter
ENGLISH_WORDS_STOPLIST: List[str] = [
'(', ')', 'and', 'of', 'the', 'amongst', 'with', 'from', 'after', 'its', 'it', 'at', 'is',
'this', ',', '.', 'be', 'in', 'that', 'an', 'other', 'than', 'also', 'are', 'may', 'suggests',
'all', 'where', 'most', 'against', 'more', 'have', 'been', 'several', 'as', 'before',
'although', 'yet', 'likely', 'rather', 'over', 'a', 'for', 'can', 'these', 'considered',
'used', 'types', 'given', 'precedes',
]
def split_to_tokens(text: str) -> List[str]:
'''
Split text string to tokens.
Behavior is similar to str.split(),
but empty lines are omitted and punctuation marks are separated from word.
Example:
split_to_tokens('John said 'Hey!' (and some other words.)') ->
-> ['John', 'said', ''', 'Hey', '!', ''', '(', 'and', 'some', 'other', 'words', '.', ')']
'''
result = []
for item in text.split():
while item[0] in PUNCTUATION:
result.append(item[0])
item = item[1:]
for i in range(len(item)):
if item[-i - 1] not in PUNCTUATION:
break
if i == 0:
result.append(item)
else:
result.append(item[:-i])
result.extend(item[-i:])
return [item for item in result if item]
def split_tokens_to_phrases(tokens: List[str], stoplist: List[str] = None) -> List[str]:
"""
Merge tokens into phrases, delimited by items from stoplist.
Phrase is a sequence of token that has the following properties:
- phrase contains 1 or more tokens
- tokens from phrase go in a row
- phrase does not contain delimiters from stoplist
- either the previous (not in a phrase) token belongs to stop list or it is the beginning of tokens list
- either the next (not in a phrase) token belongs to stop list or it is the end of tokens list
Example:
split_tokens_to_phrases(
tokens=['Mary', 'and', 'John', ',', 'some', 'words', '(', 'and', 'other', 'words', ')'],
stoplist=['and', ',', '.', '(', ')']) ->
-> ['Mary', 'John', 'some words', 'other words']
"""
if stoplist is None:
stoplist = ENGLISH_WORDS_STOPLIST
stoplist += list(PUNCTUATION)
current_phrase: List[str] = []
all_phrases: List[str] = []
stoplist_set: Set[str] = {stopword.lower() for stopword in stoplist}
for token in tokens:
if token.lower() in stoplist_set:
if current_phrase:
all_phrases.append(' '.join(current_phrase))
current_phrase = []
else:
current_phrase.append(token)
if current_phrase:
all_phrases.append(' '.join(current_phrase))
return all_phrases
def get_cooccurrence_graph(phrases: List[str]) -> Dict[str, Dict[str, int]]:
"""
Get graph that stores cooccurence of tokens in phrases.
Matrix is stored as dict,
where key is token, value is dict (key is second token, value is number of cooccurrence).
Example:
get_occurrence_graph(['Mary', 'John', 'some words', 'other words']) -> {
'mary': {'mary': 1},
'john': {'john': 1},
'some': {'some': 1, 'words': 1},
'words': {'some': 1, 'words': 2, 'other': 1},
'other': {'other': 1, 'words': 1}
}
"""
graph: Dict[str, Dict[str, int]] = {}
for phrase in phrases:
for first_token in phrase.lower().split():
for second_token in phrase.lower().split():
if first_token not in graph:
graph[first_token] = {}
graph[first_token][second_token] = graph[first_token].get(second_token, 0) + 1
return graph
def get_degrees(cooccurrence_graph: Dict[str, Dict[str, int]]) -> Dict[str, int]:
"""
Get degrees for all tokens by cooccurrence graph.
Result is stored as dict,
where key is token, value is degree (sum of lengths of phrases that contain the token).
Example:
get_degrees(
{
'mary': {'mary': 1},
'john': {'john': 1},
'some': {'some': 1, 'words': 1},
'words': {'some': 1, 'words': 2, 'other': 1},
'other': {'other': 1, 'words': 1}
}
) -> {'mary': 1, 'john': 1, 'some': 2, 'words': 4, 'other': 2}
"""
return {token: sum(cooccurrence_graph[token].values()) for token in cooccurrence_graph}
def get_frequencies(cooccurrence_graph: Dict[str, Dict[str, int]]) -> Dict[str, int]:
"""
Get frequencies for all tokens by cooccurrence graph.
Result is stored as dict,
where key is token, value is frequency (number of times the token occurs).
Example:
get_frequencies(
{
'mary': {'mary': 1},
'john': {'john': 1},
'some': {'some': 1, 'words': 1},
'words': {'some': 1, 'words': 2, 'other': 1},
'other': {'other': 1, 'words': 1}
}
) -> {'mary': 1, 'john': 1, 'some': 1, 'words': 2, 'other': 1}
"""
return {token: cooccurrence_graph[token][token] for token in cooccurrence_graph}
def get_ranked_phrases(phrases: List[str], *,
degrees: Dict[str, int],
frequencies: Dict[str, int]) -> List[Tuple[str, float]]:
"""
Get RAKE measure for every phrase.
Result is stored as list of tuples, every tuple contains of phrase and its RAKE measure.
Items are sorted non-ascending by RAKE measure, than alphabetically by phrase.
"""
processed_phrases: Set[str] = set()
ranked_phrases: List[Tuple[str, float]] = []
for phrase in phrases:
lowered_phrase = phrase.lower()
if lowered_phrase in processed_phrases:
continue
score: float = sum(degrees[token] / frequencies[token] for token in lowered_phrase.split())
ranked_phrases.append((lowered_phrase, round(score, 2)))
processed_phrases.add(lowered_phrase)
# Sort by score than by phrase alphabetically.
ranked_phrases.sort(key=lambda item: (-item[1], item[0]))
return ranked_phrases
def rake_text(text: str) -> List[Tuple[str, float]]:
"""
Get RAKE measure for every phrase in text string.
Result is stored as list of tuples, every tuple contains of phrase and its RAKE measure.
Items are sorted non-ascending by RAKE measure, than alphabetically by phrase.
"""
tokens: List[str] = split_to_tokens(text)
phrases: List[str] = split_tokens_to_phrases(tokens)
cooccurrence: Dict[str, Dict[str, int]] = get_cooccurrence_graph(phrases)
degrees: Dict[str, int] = get_degrees(cooccurrence)
frequencies: Dict[str, int] = get_frequencies(cooccurrence)
ranked_result: List[Tuple[str, float]] = get_ranked_phrases(phrases, degrees=degrees, frequencies=frequencies)
return ranked_result
执行效果:
if __name__ == '__main__': text = 'Mercy-class includes USNS Mercy and USNS Comfort hospital ships. Credit: US Navy photo Mass Communication Specialist 1st Class Jason Pastrick. The US Naval Air Warfare Center Aircraft Division (NAWCAD) Lakehurst in New Jersey is using an additive manufacturing process to make face shields.........' ranked_result = rake_text(text) print(ranked_result)
关键短语抽取效果如下:
[
('additive manufacturing process to make face shields.the 3d printing face shields', 100.4),
('us navy photo mass communication specialist 1st class jason pastrick', 98.33),
('us navy’s mercy-class hospital ship usns comfort.currently stationed', 53.33),
...
]
-
SVPWM的原理及法则推导和控制算法介绍2023-10-07 995
-
SVPWM算法架构介绍2021-08-27 1535
-
Rake简介和自定义Rake任务2020-04-07 2288
-
RAKE接收机的原理介绍和使用MATLAB以及RAKE接收机的性能说明等介绍2020-01-03 2712
-
RAKE接收机的合并方式2017-11-13 11950
-
rake接收机的工作原理2017-11-11 12819
-
数学建模十大算法介绍2016-11-11 18824
-
扩频通信系统中Rake接收性能仿真研究2013-05-06 1289
-
指纹识别算法流程介绍2011-11-09 7402
-
自适应RAKE接收技术2010-10-16 408
-
用于TD-SCDMA通信终端的RAKE接收机2010-09-15 1190
-
在ADSP2181上实现Rake接收机路径搜索2009-05-09 618
全部0条评论

快来发表一下你的评论吧 !
