

介绍两个few-shot NER中的challenge
描述
01
Introduction-现有什么问题、怎么解决
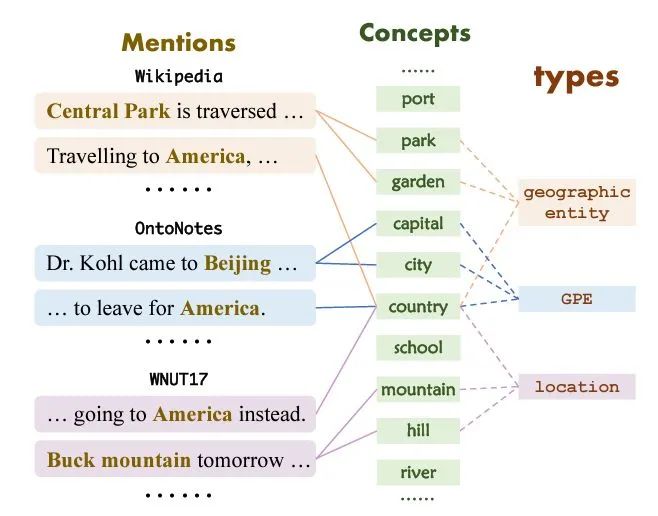
此部分着重介绍了两个few-shot NER中的challenge:limited information challenge和knowledge mismatch challenge。前者主要是指样本数少,后者是指不同的数据集中同一个实体可能被分成了不同的类别标签。(比如“America”在Wikipedia被分为geographic , 在 OntoNotes中被分为GPE, 在WNUT17被分为location )
本文最重要的思想基于这样一个假设:不论是否是未知的实体类别,都可以用一个概念集中的若干概念来描述(all entity types can be described using the same set of concepts)。这样可以解决knowledge mismatch challenge,而且在给了几个少样本后,可以根据这几个少样本构建新实体类别到概念集的映射,这样可以直接用映射后的若干概念识别实体,进而解决limited information challenge。下图是实体类别到概念集的映射举例。
02
SDNet: Self-describing Networks for FS-NER
2.1 SDNet核心部分: Mention describing、Entity generation
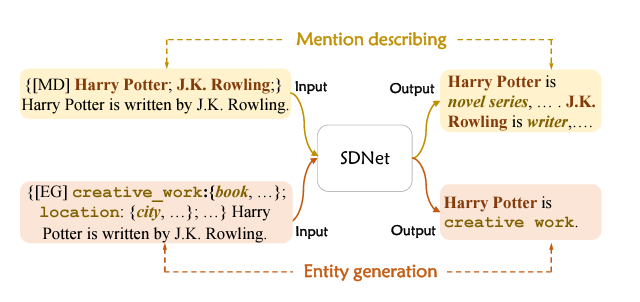
这部分将主要介绍SDNet怎么进行命名实体识别的,主要包括:Mention describing(从给的sentence构建该实体的concept description)和Entity generation(根据给的实体类型逐个生成句子中的实体词)。
以下图为例,输入一个sentence(以[MD]作为起始符),SDNet将输出novel series这样的concept description。输入一个以[EG]作为起始符、实体类别名+相关的concept description以及待识别的sentence作为内容的文本,SDNet将输出Harry Potter is creative work.这样的回答。这两个过程分别对应Mention describing和Entity generation。
2.2 模型工作流程
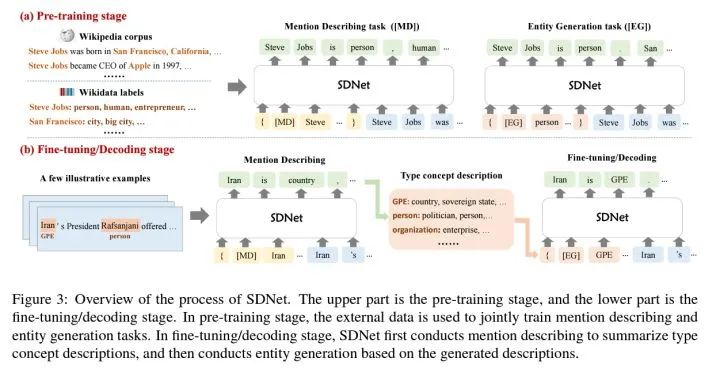
a、预训练阶段
左上角的维基百科上有大量的句子,句子中的人物、地点、公司等都有相应的维基百科给的标签和描述。预训练阶段根据2.1部分介绍的模板,进行[MD]和[EG]两个任务的Seq2Seq任务的训练。
b、微调与解码阶段
这部分对应于Few-shot NER的少样本阶段。给了一些带标注的少量样本句子,我们知道了这些句子中那些单词是实体部分,把这些实体部分添加到以[MD]开头的模板并输入到SDNet中,模型会生成这些实体部分描述,并将生成的描述加入到新类别的概念描述集中,并在预测阶段输入添加了新类别的[EG]开头的模板,根据生成的结果判断待预测的句子中哪些单词部分是该类别的实体。
以上图中为例,给的少样本中Iran是GPE类别的实体,SDNet先用[MD]开头的模板生成了Iran是country的描述,将country加入到属于GPE这个新类别的概念描述集合中,在预测阶段用[EG]开头的模板输入GPE这个类别名、其包含的概念描述以及待识别的句子,生成属于GPE的实体词,完成实体识别。
c、Filtering Strategy
在众多下游任务中,SDNet可能会遇到难以生成新实体类别描述的情况(或者或生成不准确的描述),因此SDNet在训练阶段可以对于那些不去确定的instance生成other的描述词。如果给少量样本生成的描述词中有0.5以上的other,将在最后的decode阶段直接使用新实体类别名(如GPE)。(实验部分可以看到这个策略带来了一定的提升)
具体实现过程将不再赘述,可以看原文的第4部分,有对预训练和fintune阶段的详细介绍。
03
实验部分
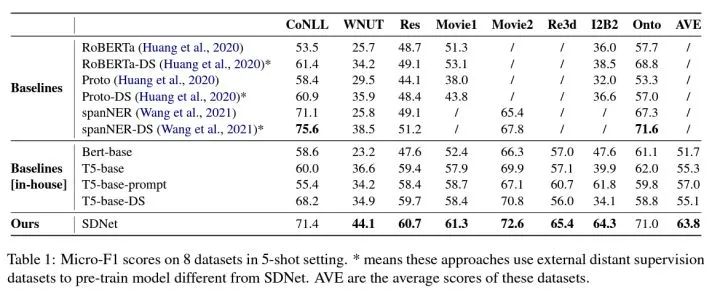
这种借助先验知识的方式,在6个数据集上都取得了很好的效果,尤其是对一些之前的识别效果一直很差的(比如I2B2),这说明这种通用的实体概念集合在各种类别间是通用的。
04
评价
优点:
为少样本NER引用外部知识提供了新思路,且提供了可直接使用的,通用的预训练模型,可以为后来的研究工作提供参考。
可能的缺陷:
在很多新领域下(尤其涉及到domain transfer)的,可能会出现很多无法描述成概念集合的实体类别,出现大量的other,这时只能用实体类别名了,在完全不重叠的领域之间可能效果会不佳。
另外,预训练阶段使用的维基百科,大量的是事件人物地点等这些广泛且常用的,面对实际应用中的非常见实体类别时,可能做不到很好的描述。
在大量的语料中进行训练,可能出现了“泄露”,当然这只是一个猜测。
审核编辑:刘清
- 相关推荐
- 热点推荐
- SDNet
-
清华联合阿里达摩院开发行业首个人工标注的少样本NER数据集2021-05-28 2001
-
Few-shot NER的三阶段2022-08-24 2401
-
基于将 CLIP 用于下游few-shot图像分类的方案2022-09-27 7088
-
分享两个STM32应用中的实战案例2023-01-11 5739
-
冷链运输中的两个重要环节2023-01-28 2127
-
两个LED和两个按钮的使用2023-01-30 827
-
基于显式证据推理的few-shot关系抽取CoT2023-11-20 2214
-
电子设计中的两个不同概念:pcb与pcb封装2023-12-11 2425
-
arcgis中如何关联两个属性表2024-02-25 7691
全部0条评论

快来发表一下你的评论吧 !
