

Few-shot NER的三阶段
描述
01
—
方法介绍
Few-shot NER的三阶段:Train、Adapt、Recognize,即在source域训练,在target域的support上微调,在target域的query上测试。
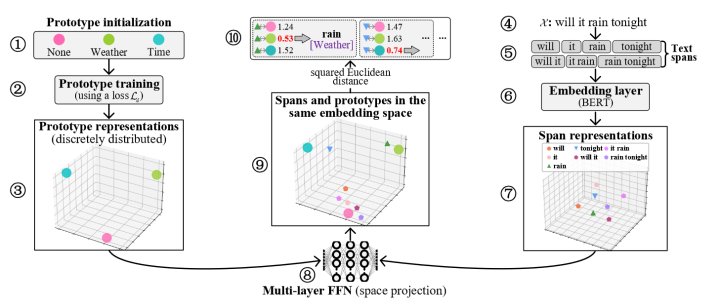
如上图,左边(1-3)表示的是原型的loss1(训练目标为各个原型分散分布),右边(4-7)表示的是span的representation获取,中间(8)是一个多层FFN(为了使得原型表示和span表示最终映射到同一个向量空间),中间(9-10)则是计算原型和span在同一个空间的loss2(为了使得实体span更靠近原型表示)
02
—
和过往工作相比
1、使得Adapt阶段不只是通过对support集中的实体词表示平均得到实体原型表示,而是能够进行finetune(文中提到Ma et al. (2022) claim that the finetuning method is far more effective in using the limited information in support sets.)
2、过往的原型网络的训练方法使得最终的原型表示较接近,本文通过构造loss1(上一段提到的)使得原型表示分散开
03
—
实验结果
这里仅挑选附录部分的FEW-NERD实验结果
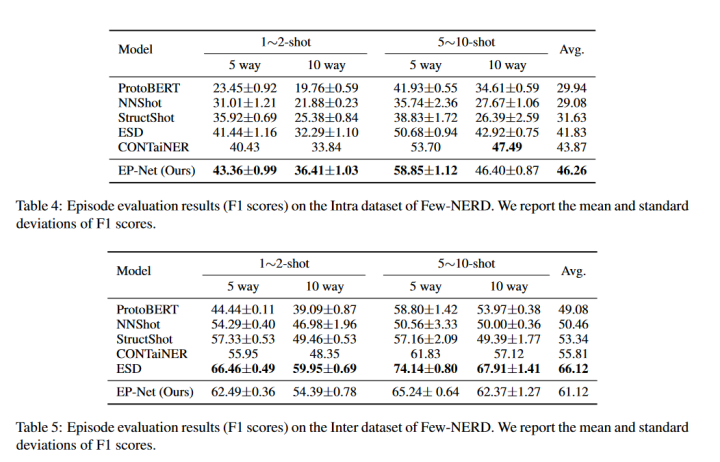
从实验结果来看,在INTRA上效果较好,在INTER上不如ESD。其中INTRA是指source和target之间的实体的粗粒度类型无交集,INTER则在粗粒度上有交集(细粒度上无交集)。(另外,2022年还有一篇SOTA文章Decomposed metalearning for few-shot named entity recognition,这里没有进行对比)
04
—
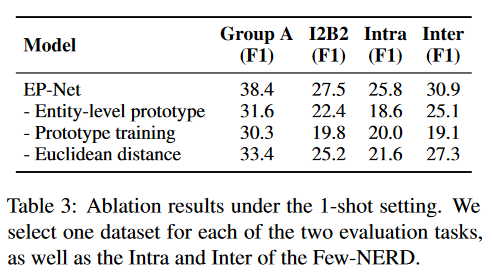
消融实验
1、使用token-level
2、缺少loss1(把原型打散的loss,方法介绍中有说)
3、使用cosine similarity而不是Euclidean distance来衡量span-prototype相似度
-
基于将 CLIP 用于下游few-shot图像分类的方案2022-09-27 6982
-
CDMA_协议测试规范_第三阶段(CDG3)2012-11-03 1993
-
关于蓄电池的三阶段充电疑点2013-07-07 4543
-
三阶段充电器的关键参数疑点2014-01-14 7006
-
中国联通召开学习实践活动第三阶段工作会议2009-06-15 662
-
中芯国际将在2019年量产14纳米FinFET,并勾勒28纳米三阶段蓝图2017-11-17 2228
-
5G第三阶段测试规划详解2018-09-25 3595
-
五大设备商的5G三阶段测试进展对比2018-10-28 5906
-
我国5G完成第三阶段测试 离5G商用又近了一步2018-10-08 1626
-
华为完成中国5G技术研发试验第三阶段测试 刷新业界纪录2019-05-04 1307
-
介绍两个few-shot NER中的challenge2022-08-24 1617
-
UBBF 2023 | 迈向F5.5G,华为发布三阶段全光目标网架构2023-10-13 1072
-
迈向F5.5G,华为发布三阶段全光目标网架构2023-10-17 1666
-
基于显式证据推理的few-shot关系抽取CoT2023-11-20 2111
-
关于AI工厂三阶段模型2025-05-20 1600
全部0条评论

快来发表一下你的评论吧 !
