

在Raspberry Pi上使用Tesseract进行光学字符识别的方法
描述
机器使用相机观察现实世界并解释其中数据的能力将对其应用产生更大的影响。无论是像 Starship 机器人这样的简单送餐机器人,还是像特斯拉这样的先进自动驾驶汽车,它们都依赖从高度复杂的摄像头获取的信息来做出决定。在本教程中,我们将学习如何通过阅读图像上的字符来识别图像中的细节。这称为光学字符识别(OCR)。
这为许多应用程序打开了大门,例如自动读取名片中的信息、从名称板上识别商店或识别道路上的标志板等等。我们中的一些人可能已经通过 Google Lens 体验过这些功能,所以今天我们将使用来自Google Tesseract-OCR 引擎的光学字符识别 (OCR)工具以及 python 和 OpenCV 构建类似的东西,以使用Raspberry Pi识别图片中的字符。
Raspberry pi 是一种便携式且功耗更低的设备,用于许多实时图像处理应用,如人脸检测、 对象跟踪、 家庭安全系统、监控摄像头等。
先决条件
如前所述,我们将使用 OpenCV 库来检测和识别人脸。因此,在继续本教程之前,请确保在 Raspberry Pi 上安装 OpenCV 库。还可以使用 2A 适配器为您的 Pi 供电,并将其连接到显示监视器以便于调试。
本教程不会解释OpenCV的工作原理,如果您有兴趣学习图像处理,请查看此OpenCV 基础知识和高级图像处理教程。您还可以在此使用 OpenCV 的图像分割教程中了解轮廓、斑点检测等。
在树莓派上安装 Tesseract
要在 Raspberry Pi 上执行光学字符识别,我们必须在 Pi 上安装 Tesseract OCR 引擎。为此,我们必须首先配置 Debian 软件包 (dpkg),这将帮助我们安装 Tesseract OCR。在终端窗口中使用以下命令来配置 Debian Package。
sudo dpkg - -configure -a
然后我们可以继续使用 apt-get 选项安装 Tesseract OCR (光学字符识别)。下面给出了相同的命令。
sudo apt-get install tesseract-ocr
您的终端窗口将如下所示,安装完成大约需要 5-10 分钟。
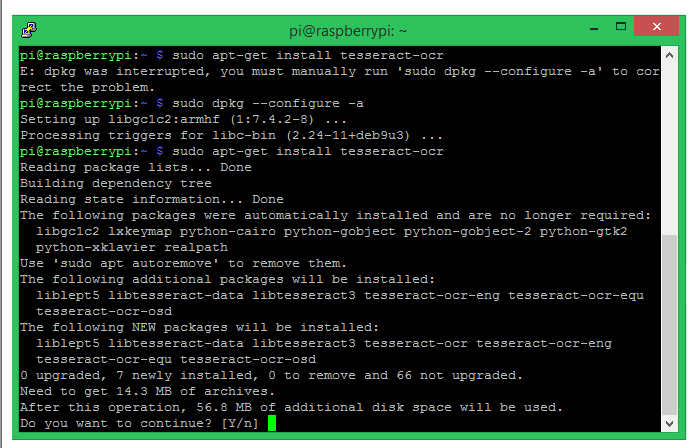
现在我们已经安装了 Tesseract OCR,我们必须使用 pip install package 安装 PyTesseract 包。Pytesseract 是围绕 tesseract OCR 引擎的 python 包装器,它帮助我们将 tesseract 与 python 一起使用。按照以下命令在 python 上安装 pytesseract。
点安装 pytesseract
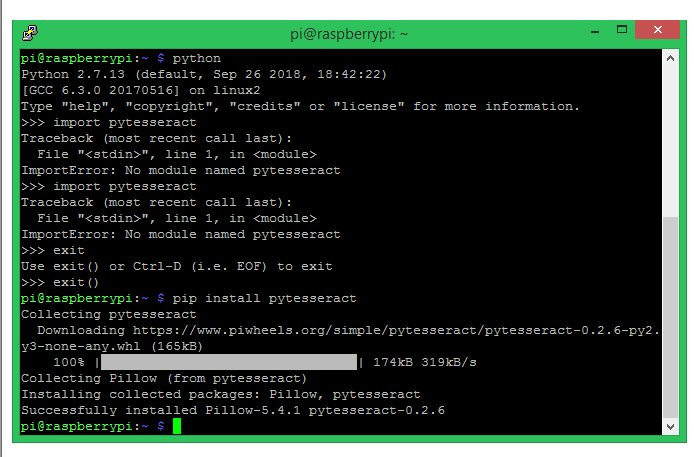
在进行此步骤之前,请确保已经安装了枕头。学过树莓派人脸识别教程的人应该已经安装好了。其他人可以使用该教程并立即安装。pytesseract 安装完成后,您的窗口将如下所示
Windows/Ubuntu 上的 Tesseract 4.0
Tesseract 光学字符识别项目最初由 Hewlett Packard 于 1980 年启动,然后被 Google 采用,该项目一直保持至今。多年来,Tesseract 不断发展,但它仍然只在受控环境中运行良好。如果图像有太多的背景噪音或失焦,则 tesseract 似乎无法正常工作。
为了克服这个问题,最新版本的 tesseract Tesseract 4.0 使用深度学习模型来识别字符甚至笔迹。Tesseract 4.0 使用长短期记忆 (LSTM) 和循环神经网络 (RNN) 来提高其 OCR 引擎的准确性。不幸的是,在本教程的这个时候,Tesseract 4.0 仅适用于 Windows 和 Ubuntu,但仍处于 Raspberry Pi 的 beta 阶段。所以我们决定在 Windows 上试用 Tesseract 4.0,在 Raspberry Pi 上试用 Tesseract 3.04。
Pi上的简单字符识别程序
因为我们已经在 PI 中安装了Tesseract OCR和 Pytesseract 包。我们可以快速编写一个小程序来检查字符识别是如何处理测试图像的。我使用的测试图像、程序和结果可以在下图中找到。

如您所见,该程序非常简单,我们甚至没有使用任何 OpenCV 包。上面的程序在下面给出
from PIL import Image
img =Image.open (‘1.png’)
text = pytesseract.image_to_string(img, config=‘’)
print (text)
在上面的程序中,我们试图从位于程序同一目录内的名为“1.png”的图像中读取文本。Pillow 包用于打开此图像并将其保存在变量名img下。然后我们使用pytesseract 包中的image_to_sting方法检测图像中的任何文本,并将其保存为变量 text 中的字符串。最后我们打印文本的值来检查结果。
如您所见,原始图像实际上包含文本“解释那些东西!01234567890 ”这是一个完美的测试图像,因为我们在图像中有字母、符号和数字。但是我们从 pi 得到的输出是“解释那些东西!Sdfosiefoewufv”这意味着 out 程序无法识别图像中的任何数字。为了克服这个问题,人们通常使用 OpenCV 从程序中去除噪声,然后根据图像配置 Tesseract OCR 引擎以获得更好的结果。但请记住,您不能期望 Tesseract OCR Python 提供 100% 可靠的输出。
配置 Tesseract OCR 以改进结果
Pytesseract 允许我们通过设置更改图像搜索字符方式的标志来配置 Tesseract OCR 引擎。配置 Tesseract OCR 时使用的三个主要标志是语言 (-l)、OCR 引擎模式 (--oem) 和页面分段模式 (- -psm )。
除了默认的英语,Tesseract 还支持许多其他语言,包括印地语、土耳其语、法语等。我们在这里只使用英语,但您可以从官方github 页面下载训练数据并将其添加到您的包中以识别其他语言。 还可以从同一图像中识别两种或多种不同的语言。语言由标志 -l设置,要将其设置为一种语言,请使用代码和标志,例如对于英语,它将是-l eng,其中 eng 是英语的代码。
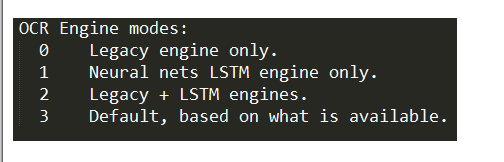
下一个标志是 OCR Engine Mode,它有四种不同的模式。每种模式都使用不同的算法来识别图像中的字符。默认情况下,它使用随包安装的算法。但我们可以将其更改为使用 LSTM 或神经网络。四种不同的引擎模式如下所示。该标志由--oem 指示,因此要将其设置为模式 1,只需使用--oem 1。
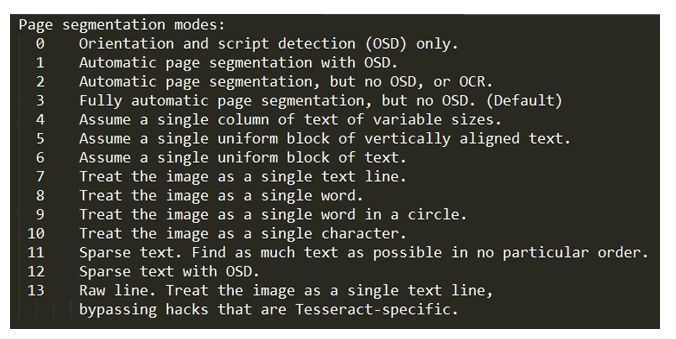
最后也是最重要的标志是页面分割模式标志。当您的图像具有如此多的背景细节以及字符或字符以不同的方向或大小书写时,这些非常有用。共有 14 种不同的页面分割模式,所有这些都在下面列出。该标志由–psm指示,因此设置模式为 11。它将是–psm 11。
在 Tesseract Raspberry Pi 中使用 oem 和 psm 以获得更好的结果
让我们检查一下这些配置模式的有效性。在下图中,我尝试识别限速板上的字符,上面写着“ SPEED LIMIT 35 ”。如您所见,与其他字母相比,数字 35 的尺寸更大,这使 Tesseract 感到困惑,因此我们仅得到“SPEED LIMIT”的输出,并且缺少数字。
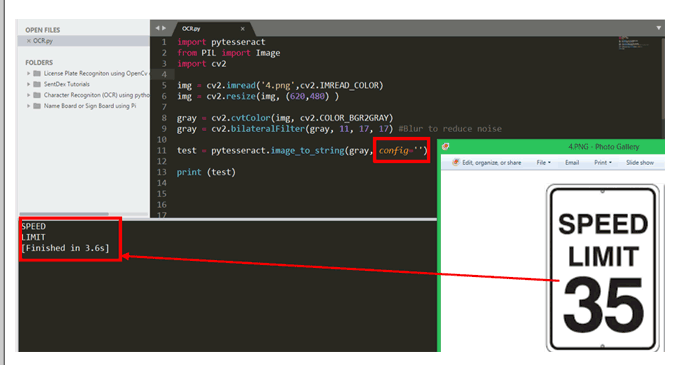
为了克服这个问题,我们可以设置配置标志。在上面的程序中,配置标志是空的 config=‘’,现在让我们使用上面提供的详细信息来设置它。图像中的所有文本都是英文,所以语言标志是 -l eng,OCR 引擎可以保留为默认模式 3 所以 -oem 3。现在终于在 psm 模式下,我们需要从图像中找到更多的字符,所以我们在这里使用模式 11,它变成了 –psm 11。最后的配置行看起来像
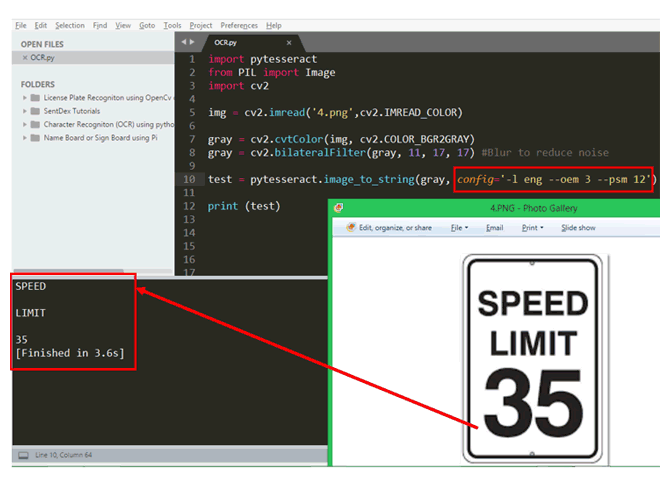
测试= pytesseract.image_to_string(灰色,配置=‘-l eng --oem 3 --psm 12’)
相同的结果可以在下面找到。正如您现在所看到的,Tesseract 能够从图像中找到所有字符,包括数字。
通过置信水平提高准确性
Tesseract 中另一个有趣的特性是image_to_data方法。该方法可以为我们提供详细信息,例如图像中字符的位置、检测的置信度、行和页码。让我们尝试在示例图像上使用它
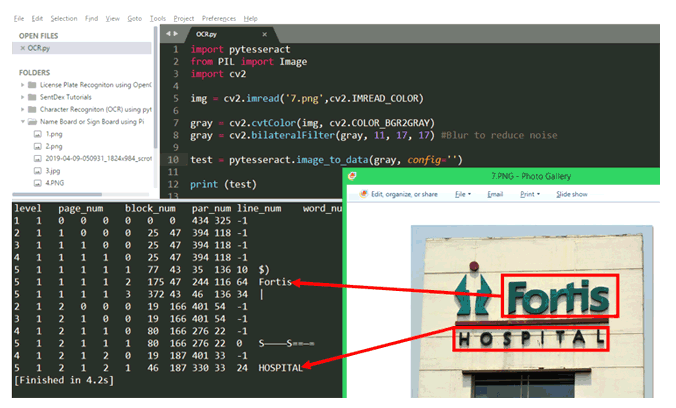
在这个特定的例子中,我们得到了很多噪声信息以及原始信息。图片是一家名为“富通医院”的医院的名字牌。但是除了名称之外,图像还具有其他背景细节,例如徽标构建等。因此,Tesseract 尝试将所有内容都转换为文本,并给我们带来了很多噪音,例如“$C”“|” “S_______S==+”等。
现在在这些情况下image_to_data方法就派上用场了。如您所见,上述光学字符识别算法返回其已识别的每个字符的置信度,Fortis 的置信度为 64,HOSPITAL 的置信度为 24。对于其他噪声信息,置信度值为 10 或以下大于 10。这样我们就可以过滤掉有用的信息,利用置信度的值来提高准确率。
树莓派上的 OCR
虽然使用 Tesseract 时在 Pi 上的结果不是很令人满意,但它可以与 OpenCV 结合以滤除图像中的噪声,如果图像良好,可以使用其他配置技术获得不错的结果。我们已经在 Pi 上使用 tesseract 尝试了大约 7 种不同的图像,并且通过相应地调整每张图片的模式来获得接近的结果。完整的项目文件可以下载为该位置的 Zip,其中包含所有测试图像和基本代码。
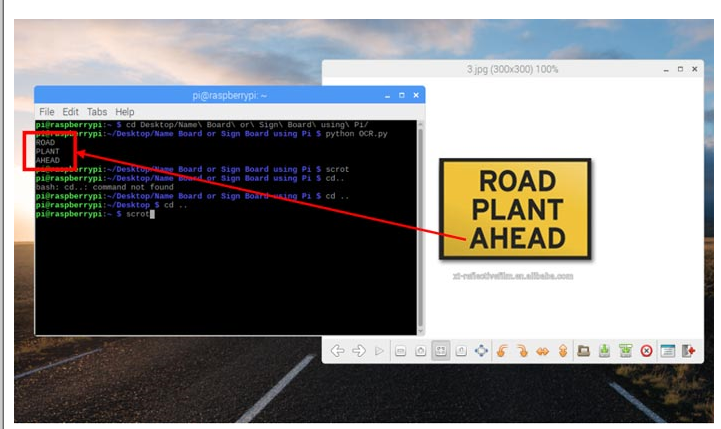
让我们在 Raspberry Pi 上再尝试一个示例板标志,这一次非常简单明了。下面给出了相同的代码
从 PIL 导入 pytesseract 导入图像
导入cv2
img = cv2.imread(‘4.png’,cv2.IMREAD_COLOR) #打开要识别字符的图像
#img = cv2.resize(img, (620,480) ) #如果需要,调整图像大小
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) #转换为灰色以减少
细节 gray = cv2.bilateralFilter(gray, 11, 17, 17) #模糊以减少噪点
original = pytesseract.image_to_string(gray, config=‘’)
#test = (pytesseract.image_to_data(gray, lang=None, config=‘’, nice=0) ) #get confidence level if required
#print(pytesseract.image_to_boxes(灰色的))
打印(原件)
该程序打开我们需要从中识别字符的文件,然后将其转换为灰度。这将减少图像中的细节,使 Tesseract 更容易识别字符。为了进一步减少背景噪声,我们使用 OpenCV 中的一种双边滤波器对图像进行模糊处理。最后,我们开始从图像中识别字符并将其打印在屏幕上。最终的结果将是这样的。
希望您理解本教程并喜欢学习新知识。OCR 用于许多地方,如自动驾驶汽车、车牌识别、路牌识别导航等,在 Raspberry Pi 上使用它为更多可能性打开了大门,因为它可以便携且紧凑。
导入 pytesseract
从 PIL 导入图像
导入简历2
img = cv2.imread('4.png',cv2.IMREAD_COLOR) #打开要识别字符的图像
#img = cv2.resize(img, (620,480) ) #如果需要调整图像大小
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) #转换为灰色以减少细节
gray = cv2.bilateralFilter(gray, 11, 17, 17) #Blur 去噪
原始= pytesseract.image_to_string(灰色,配置='')
#test = (pytesseract.image_to_data(gray, lang=None, config='', nice=0) ) #get confidence level if required
#print(pytesseract.image_to_boxes(灰色))
打印(原件)
'''必需 = 'abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ'
最终 = ''
对于原始的 c:
对于需要的ch:
如果 c==ch:
最终 = 最终 + c
休息
打印(测试)
在测试中:
如果 a == "\n":
打印(“找到”)'''
-
有没有专门针对光学字符识别的功能包?2022-12-07 478
-
Raspberry Pi和Arduino上的手写数字识别2022-10-19 1120
-
在Raspberry Pi上安装Android的方法2022-09-05 22596
-
机器视觉运动控制一体机应用例程|OCR字符识别应用2022-02-24 2309
-
了解光学字符识别技术识别票据原理2020-11-27 3269
-
使用低成本实现光学字符识别读表系统的研究说明2019-10-28 1021
-
OCR光学字符识别技术与市场完美的融合到了一起2019-06-04 3051
-
OCR光学字符识别技术原理讲解2019-03-02 22445
-
采用机器视觉软件的高速光学字符识别系统2018-11-23 3240
-
光学字符识别读表系统设计2018-02-28 1183
-
两级分类实现车牌字符识别2017-11-30 912
-
运用Labview如何进行图像采集与字符识别?2017-04-27 7627
-
求DSP字符识别源程序2013-05-15 2222
-
模式识别中三种字符识别的方法2010-10-09 1303
全部0条评论

快来发表一下你的评论吧 !
