

什么是机器学习?机器学习基础介绍
描述
本文旨在为硬件和嵌入式工程师介绍机器学习 (ML) 的背景,了解它是什么、它是如何工作的、它为何重要以及 TinyML 如何融入其中。
机器学习是一个永远存在且经常被误解的技术概念。这种实践是使用复杂的处理和数学技术使计算机能够找到大量输入和输出数据之间的相关性的科学,几十年来一直存在于我们对技术的集体意识中。近年来,科学爆炸式增长,得益于以下方面的改进:
计算能力
图形处理单元 (GPU) 架构支持的并行处理
用于大规模工作负载的云计算
事实上,该领域一直专注于桌面和基于云的使用,以至于许多嵌入式工程师没有过多考虑 ML 如何影响他们。在大多数情况下,它没有。
然而,随着TinyML 或微型机器学习(在微控制器和单板计算机等受限设备上的机器学习)的出现,ML 已经与所有类型的工程师相关,包括从事嵌入式应用程序的工程师。除此之外,即使您熟悉 TinyML,对一般机器学习有一个具体的了解也很重要。
在本文中,我将概述机器学习、它的工作原理以及它对嵌入式工程师的重要性。
什么是机器学习?
作为人工智能 (AI) 领域的一个子集,机器学习是一门专注于使用数学技术和大规模数据处理来构建可以找到输入和输出数据之间关系的程序的学科。作为一个总称,人工智能涵盖了计算机科学中的一个广泛领域,专注于使机器能够在没有人工干预的情况下“思考”和行动。它涵盖了从“通用智能”或机器以与人类相同的方式思考和行动的能力,到专门的、面向任务的智能,这是 ML 的范畴。
我听说过去定义 ML 的最强大的方法之一是与经典计算机编程中使用的传统算法方法进行比较。在经典计算中,工程师向计算机提供输入数据——例如数字 2 和 4——以及将它们转换为所需输出的算法——例如,将 x 和 y 相乘得到 z。当程序运行时,会提供输入,然后应用算法来产生输出。这可以在图 1 中看到。

图 1.在经典方法中,我们向计算机提供输入数据和算法并要求答案。
另一方面,ML 是向计算机呈现一组输入和输出并要求计算机识别“算法”(或模型,使用 ML 术语)每次将这些输入转换为输出的过程。通常,这需要大量输入以确保模型每次都能正确识别正确的输出。
例如,在图 2 中,如果我向 ML 系统提供数字 2 和 2 以及预期输出 4,它可能会决定算法总是将这两个数字相加。但是,如果我随后提供数字 2 和 4 以及预期输出 8,模型将从两个示例中了解到正确的方法是将两个提供的数字相乘。
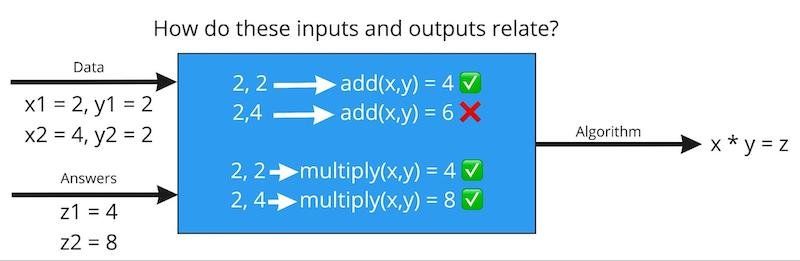
图 2.使用 ML,我们拥有数据(输入)和答案(输出),并且需要计算机通过确定输入和输出如何以适用于整个数据集的方式关联来推导各种算法。
鉴于我正在使用一个简单的示例来定义一个复杂的字段,此时您可能会问:为什么要费心将简单的字段复杂化?为什么不坚持我们经典的算法计算方法?
答案是倾向于机器学习的这类问题通常不能通过纯粹的算法方法来表达。没有简单的算法可以给计算机一张图片并要求它确定其中是否包含猫或人脸。相反,我们利用 ML 并为其提供数千张包含猫和人脸的图片(作为像素集合),两者都没有,并且通过学习如何将这些像素和像素组与预期输出相关联来开发模型。当机器看到新数据时,它会根据之前看到的所有示例推断输出。这部分过程,通常称为预测或推理,是机器学习的魔力。
这听起来很复杂,因为它是。在嵌入式和物联网 (IoT) 系统的世界中,机器学习越来越多地被用于帮助机器视觉、异常检测和预测性维护等领域。在每个领域,我们收集大量数据——图像和视频、加速度计读数、声音、热量和温度——用于监控设施、环境或机器。然而,我们经常难以将这些数据转化为我们可以采取行动的洞察力。条形图很好,但是当我们真正想要的是能够在机器中断和离线之前预测机器需要服务的能力时,简单的算法方法是行不通的。
机器学习开发循环
进入机器学习。在有能力的数据科学家和机器学习工程师的指导下,这个过程从数据开始。也就是说,我们的嵌入式系统创建的海量数据。ML 开发过程的第一步是收集数据并在将其输入模型之前对其进行标记。标签是一个关键的分类步骤,也是我们将一组输入与预期输出相关联的方式。
ML 中的标签和数据收集
例如,一组加速度计 x、y 和 z 值可能对应于机器处于空闲状态,另一组可能表示机器运行良好,第三组可能对应于问题。在图 3 中可以看到高级描述。
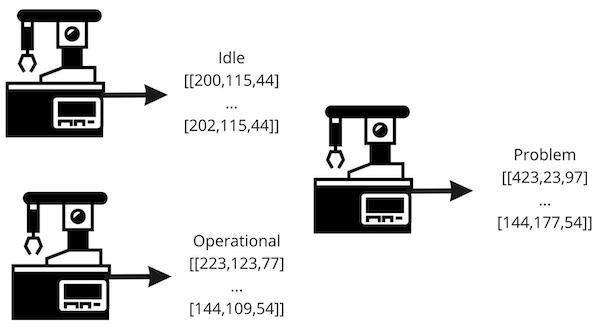
图 3.ML 工程师在数据收集过程中使用标签对数据集进行分类。
数据收集和标记是一个耗时的过程,但对于正确处理至关重要。虽然 ML 领域有几项创新利用预训练模型来抵消一些工作和新兴工具来简化从真实系统中收集数据,但这是一个不能跳过的步骤。世界上没有任何机器学习模型能够可靠地告诉您您的机器或设备是否运行良好或即将发生故障,而无需查看来自该机器或其他类似机器的实际数据。
机器学习模型开发、训练、测试、提炼
数据收集后,接下来的步骤是模型开发、训练、测试和细化。这个阶段是数据科学家或工程师创建一个程序,该程序摄取大量收集的输入数据,并使用一种或多种方法将其转换为预期的输出。解释这些方法可以填满卷,但足以说明大多数模型对其输入执行一组转换(例如,向量和矩阵乘法)。此外,他们将相互调整每个输入的权重,以找到一组与预期输出可靠相关的权重和函数。
该过程的这个阶段通常是迭代的。工程师将调整模型、使用的工具和方法,以及在模型训练期间运行的迭代次数和其他参数,以构建能够可靠地将输入数据与正确输出(也称为标签)相关联的东西。一旦工程师对这种相关性感到满意,他们就会使用训练中未使用的输入来测试模型,以了解模型在未知数据上的表现。如果模型在这个新数据上表现不佳,工程师会重复循环,如图 4 所示,并进一步细化模型。
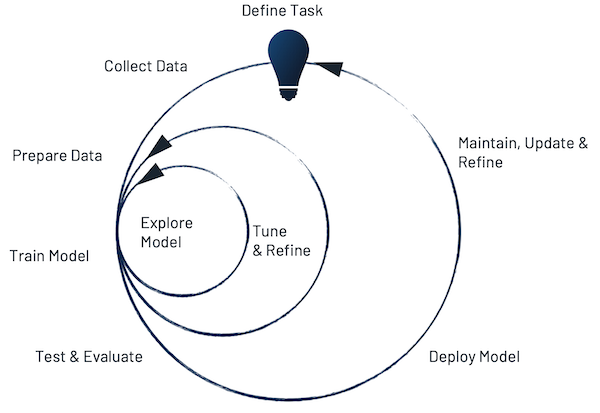
图 4.模型开发是一个包含许多步骤的迭代过程,但它从数据收集开始。
一旦模型准备就绪,它就会被部署并可用于针对新数据进行实时预测。在传统 ML 中,模型被部署到云服务中,以便它可以被正在运行的应用程序调用,该应用程序提供所需的输入并从模型接收输出。应用程序可能会提供一张图片并询问是否有人在场或一组加速度计读数,并询问模型这组读数是否对应于空闲、运行或损坏的机器。
正是在这个过程中,TinyML 如此重要且如此具有开创性。
那么 TinyML 适合在哪里呢?
如果还不清楚,机器学习是一个数据密集型过程。当您尝试通过相关性导出模型时,您需要大量数据来提供该模型。数百个图像或数千个传感器读数。事实上,模型训练的过程是如此密集、如此专业,以至于几乎任何中央处理单元 (CPU)都会占用大量资源,无论它的性能如何。相反,在 ML 中如此常见的向量和矩阵数学运算与图形处理应用程序没有什么不同,这就是为什么 GPU 已成为模型开发如此受欢迎的选择。
鉴于对强大计算的需求,云已成为卸载训练模型工作并托管它们以进行实时预测的事实上的场所。虽然模型训练是并且仍然是云的领域,特别是对于嵌入式和物联网应用程序,但我们越能将实时预测的能力转移到捕获数据的地方,我们的系统就会越好。在微控制器上运行模型时,我们获得了内置安全性和低延迟的好处,以及在本地环境中做出决策和采取行动的能力,而无需依赖互联网连接。
这是 TinyML 的领域,Edge Impulse等平台公司正在构建基于云的传感器数据收集工具和 ML 架构,以输出专为微控制器单元 (MCU)构建的紧凑、高效模型。从STMicroelectronics到Alif Semiconductor,越来越多的芯片供应商正在构建具有类似 GPU 计算能力的芯片,这使得它们非常适合在收集数据的地方与传感器一起运行 ML 工作负载。
对于嵌入式和物联网工程师来说,现在正是探索机器学习世界的最佳时机,从云到最小的设备。我们的系统只会变得越来越复杂,处理的数据比以往任何时候都多。将 ML 带到边缘意味着我们可以处理这些数据并更快地做出决策。
审核编辑 黄昊宇
-
机器学习和深度学习的区别2023-08-17 5892
-
机器学习算法的基础介绍2022-10-24 2947
-
什么是机器学习? 机器学习基础入门2022-06-21 3072
-
机器学习的基础内容2022-02-09 1245
-
机器学习的基础内容介绍2022-01-12 1504
-
介绍机器学习的基础内容2021-08-13 2210
-
最值得学习的机器学习编程语言2021-03-02 2887
-
机器学习KNN介绍2020-04-07 2925
-
【下载】《机器学习》+《机器学习实战》2017-06-01 199128
全部0条评论

快来发表一下你的评论吧 !
