

如何用语言模型(LM)实现建模能力
描述
前言
相信每个 NLPer 心中都有对 Reasoning 的一片期冀。
当初笔者进入 NLP 的大门,就是相信:由于语言强大的表达能力以及语言模型强大的建模能力,Reasoning 一定就在不久的将来!可惜实际情况却是......
直到我看到了 Yoshua Bengio 最近反复强调的 System 2 的概念,又重新燃起了心中的希望!
System 2 主要针对深度学习系统的 Reasoning 能力以及系统泛化(Systematic Generalization)等等。其中一个很重要的点是:sparse factor graph in space of high-level semantic variables. 结合 QA 的例子以及我浅薄的理解,这里做一些简单的解释:
factor graph : 从 Q 到 A 的机理,往往不是 Q -> A 这么简单,实际人类在建模 QA 的时候,会在这条路径上增添很多很多的辅助状态以及相应的运作机理,例如 Causal Inference 中常说的 SCM (Structural Causal Model)
sparse : from attention to conscious processing. 人类不会同时关注所有的状态(变量),而只会关注其中一些比较重要的或者相关的状态。通过这种主动的稀疏选择,在面对 distribution change 的时候,能够迅速更换另外的状态和运作机理进行适应(adaptation).
high-level semantic variables : 这些状态的表达,一般是一个高阶的语义变量。
在今天这篇推文里,我们主要讨论如何用语言模型(LM)实现这件事情。
那现在就以 Google Research 等的新文章 “Language Model Cascades” 开始,聊一聊 A Path Towards Universal Reasoning Systems.
总的来说,这篇文章是个 Proposal 性质的文章,核心论点是:利用概率编程语言,重复地提示(prompt)或调整单个或多个互相关联的语言模型,以进行复杂的多步推理。
这样,基于一个端到端的学习目标,就能够使用一个通用过程进行系列模型的 inference, 参数调整或者 prompt 选择。
还是用 QA 的例子,一般的 QA 是这样的:
我们有两种方式去做这件事情(假设数据集为 ):
few-shot prompting (aka. in-context learning) : ,即将小样本集作为输入的上下文拼接在输入的前面,而不去调整模型参数,常用于 GPT-3 等模型;
fine-tune : tuned on ,即使用训练集调整模型参数。
然后,我们定义语言模型级联(LM Cascades): 以从语言模型采样出的字符串为随机变量取值的一系列相互关联的概率程序。
string-valued : 例如 P(A='老鼠'|Q='猫喜欢吃什么')
相互关联的概率程序:可以简单地理解为图形式的模型链条,详见下文。
成功的例子
Scratchpads & Chain of Thought
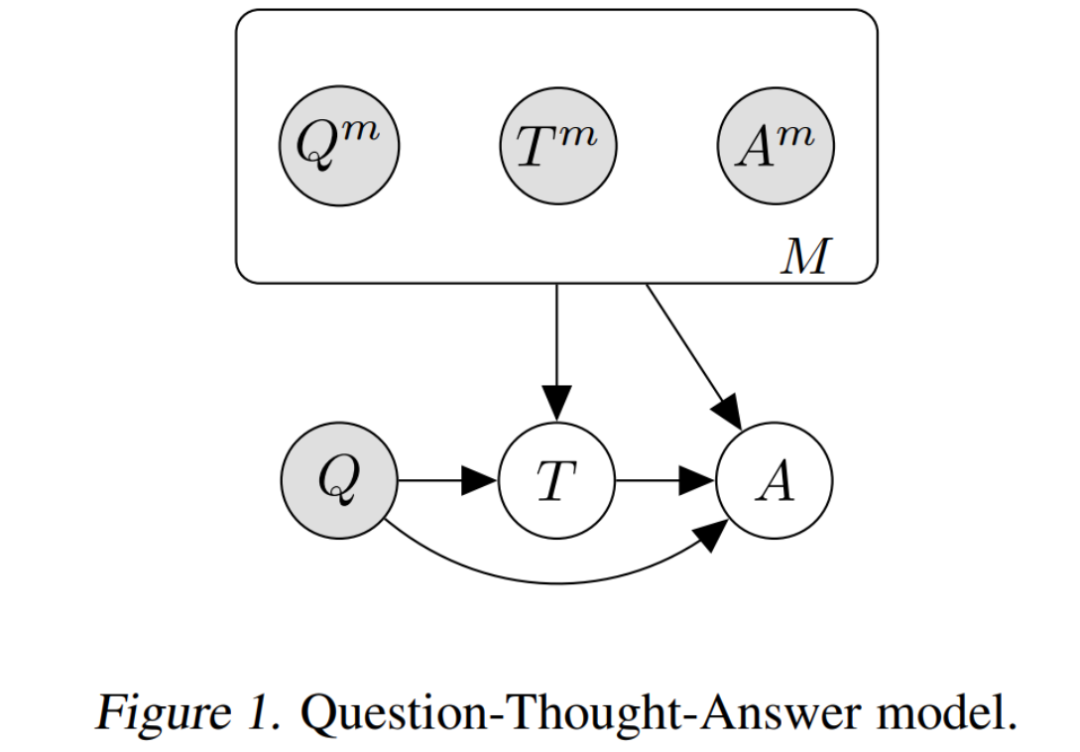
这类模型的 Cascades 如上图所示,总的来说是一种 Question-Thought-Answer 的结构:
理想情况下的概率建模为:
但在实际场景下, 通常我们只有一个 small set 由完整的 三元组组成, 以及一个 large set 由 对组成。因为缺乏完全的监督数据,我们只能通过先验预测分布 去建模:
Scratchpad[1] 和 Chain-of-Thought[2] 两种模型所做的事情,本质上是建模这个先验预测分布(prior predictive distribution):
scratchpad : 通过精调 (finetuning) 去做。
chain of thought : 将 作为 prompt, 即通过 few-shot prompting 去做。
多说一句:在全部的 上面进行求和显然不现实,通常采用的方式是:使用 beam search 估计 ,然后在此之上进行求和。
Semi-Supervised Learning
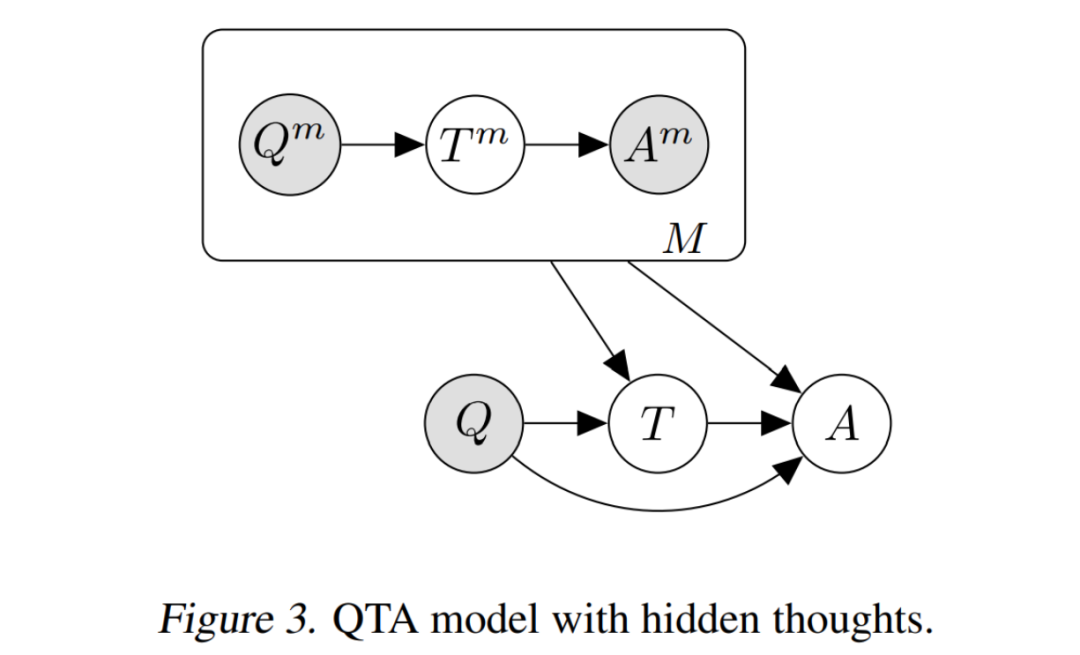
仍然是 Question-Thought-Answer 的结构,但在半监督学习的设定下,我们是为 中的 Q-A 对新增一些未知隐变量 去解决。这样就变成了一个比较典型的变分推断问题。
这类方法比较典型的工作是:Self-Taught Reasoner (STaR) [3],该模型使用 EM 算法进行优化:
-步: 首先在 上精调模型,然后对于 , 通过在 上的拒绝采样估计未知量 . 直到找到能够导致正确回答 的 . (如果找不到, 就从 采样) (这种方式也称为 :“rationale generation with rationalization”).
-步: 基于所估计的 上的 , 再次精调模型更新参数。
Selection-Inference
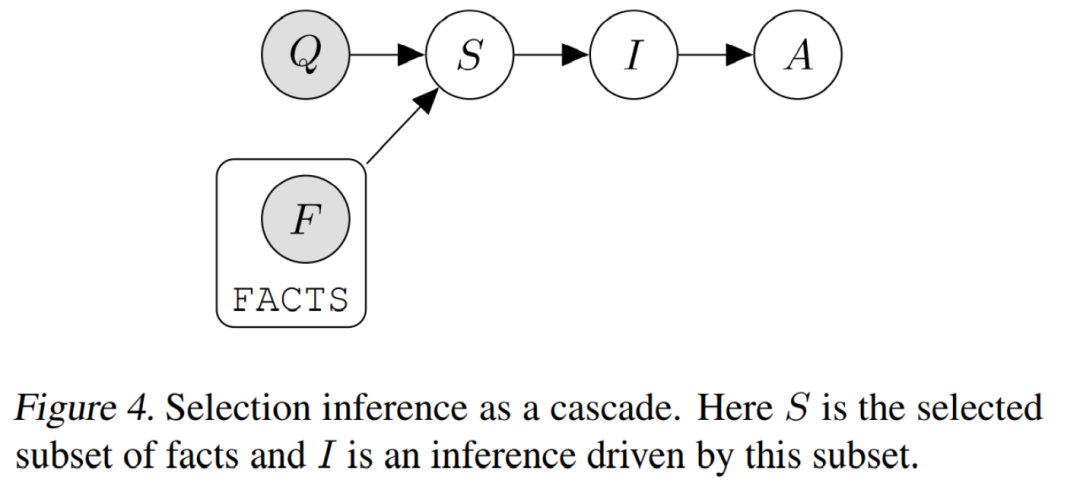
这类方法[4]将推理过程分为两个部分:
选择:给定问题 , 从事件集合 中选择相关子集;
推断:给定事件子集,推测新的事件集合。
Verifiers

这类方法[5]新增了一些验证器 ,来判断 Thought 或者 Answer 是否合理有效(valid):
where
Tool-use
上面这些方法仅仅是 Language Model 的控制流,没有外部的反馈(external feedback).
在 Cascades 的框架下,我们可以非常方便的引入外部工具,以进行额外的知识补充,比如:
calculator : Training verifiers to solve math word problems (https://arxiv.org/abs/2110.14168).
web : WebGPT: Browser-assisted question-answering with human feedback (https://openai.com/blog/webgpt/).
simulation : The frontier of simulation-based inference (https://www.pnas.org/doi/10.1073/pnas.1912789117)
Twenty Questions
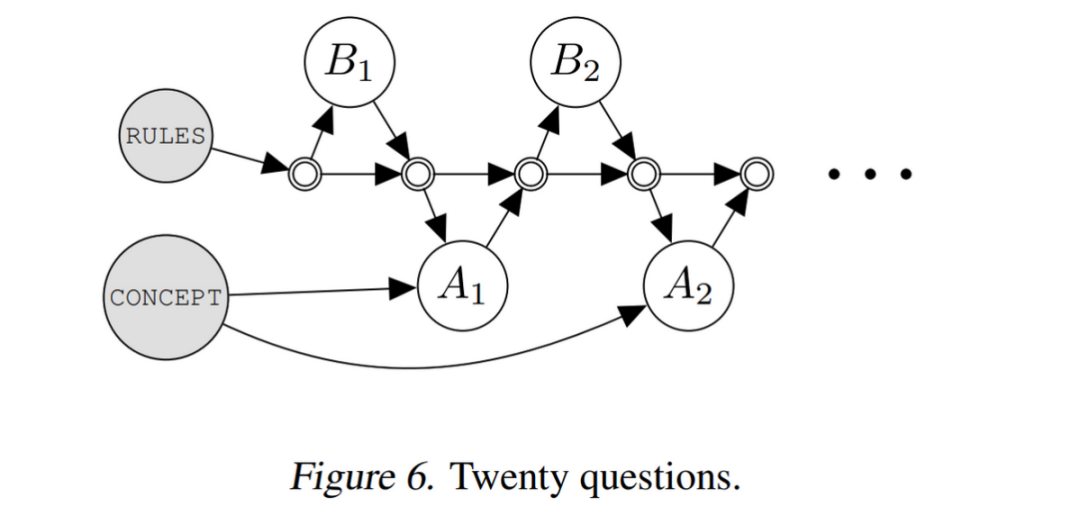
再举一个交互式问答的例子,如上图,是 Big-Bench [6] 中的一个任务:两个 agent, 分别叫做 Alice (A) 和 Bob (B). 在给定的游戏规则下,两个 agent 进行语言交流,A 描述一个概念,B 去猜,然后 A 回答是或不是,直到 B 猜出来。
这样一个过程也能很容易地归结到 Cascades 的框架中去。
未来
回到最初的问题,Sparse Factor Graph 以及 High-Level Semantic Variables. 我们可以先抛弃掉 Causal Mechanism 等复杂的问题,先只去考虑这种简单的 Cascading Mechanism.
笔者一直觉得,只用一个模型 One-For-All 肯定是行不通的:虽然我们有 Gato [7] 等所谓的 Generalist Agent,我们也很难 claim 这些模型有 Human-level 的 Out-of-Distribution 的泛化能力,或者 Systematic Generalization. 这也符合 No-Free-Lunch Theorem 一直以来告诉我们的事情。这是第一点。
第二点是,对于 Universal Reasoning 而言,本质的问题并不是如何 encode 尽可能多的知识到单个模型当中,而是:How to re-use pieces of knowledge.
那么基于这两点,就涉及到一个模块化的问题:我们能不能定义一些模块化的知识以及这些模块之间的交互方式,来实现更加本质的 Reasoning (参考:Is a Modular Architecture Enough? [8])
LM Cascades 就是这个思想的一个很好的尝试:不同的语言模型对应着不同功能的知识模块,然后通过人为定义的交互 Graph 来执行特定的任务。这么做的好处至少是:
端到端的模块化:以一种端到端的方式,做到了不同语言模型,根据其所执行的不同功能,进行专门的精调优化(finetuning)或者提示优化(prompting)。
sparse factor graph : 以一种人为定义的方式,指定了任务内在的知识结构,比如将 Q->A 分解为 Q->T->A 等。这也是近期各种 Chain-of-Thoughts 相关工作令人兴奋的点,例如 AI Chains [9] 等。这种知识结构是稀疏的,因为我们人为定义了某个 LM 是基于哪个特定的 LM,而不是全部 LM.
high-level semantic variables : 语言的表达能力是极大的,因此,以 language 作为 variable value 的一个图结构,具有非常强大的对于实际问题的建模能力。当然,language 只是一个选择,high-layer hidden states 也是一个(可能更好的)选择。
当然,不只有语言模型可以级联,多模态模型也能够级联:比如同样来自 Google 的 Socratic Models [10], 就级联了三个模态(语言-视觉-音频)的语言模型,达到了很好的零样本多模态推理能力。

因此,笔者相信 LM Cascades 体现出了 Reasoning System 的未来:(1)模块化、(2)稀疏化、(3)结构化。
这样一个系统,以语言为媒介,最好可以通过一种端到端的方式去进行优化。从这个角度看,这个 Proposal 还有很多需要探索的点,例如:
既然“端到端+手工Cascading“可以同时做到这三点,那么有没有什么办法,把 Cascading 也纳入到端到端的过程中呢(即以一种自动或者可微的方式进行),以找到一种稀疏的条件结构?
有没有什么更好的模块化机制?
推理速度...
等等。
-
AN-737: 如何用ADIsimADC完成ADC建模2025-01-13 724
-
【《大语言模型应用指南》阅读体验】+ 俯瞰全书2024-07-21 761
-
【大语言模型:原理与工程实践】大语言模型的预训练2024-05-07 1597
-
【大语言模型:原理与工程实践】揭开大语言模型的面纱2024-05-04 907
-
fpga通用语言是什么2024-03-15 1770
-
如何用ADIsimADC完成ADC建模2023-11-28 564
-
如何用python实现RFM建模2023-11-02 2003
-
什么是系统建模语言SysML?2023-09-01 10130
-
语言模型的发展历程 基于神经网络的语言模型解析2023-07-14 1571
-
应用语言模型技术创作人工智能音乐2022-10-11 1832
-
实现通用语言智能我们还需要什么2019-02-14 2791
-
我们如何实现通用语言智能2019-02-13 3062
全部0条评论

快来发表一下你的评论吧 !
