

介绍各种日志采集方式的特点及其最佳使用场景
电子说
描述
日志,对于一个程序的重要程度不言而喻。无论是作为排查问题的手段,记录关键节点信息,或者是预警,配置监控大盘等等,都扮演着至关重要的角色。是每一类,甚至每一个应用程序都需要记录和查看的重要内容。而在云原生时代,日志采集无论是在采集方案,还是在采集架构上,都会和传统的日志采集有一些差异。我们汇总了一下在日志的采集过程中,经常会遇到一些实际的通用问题,例如:
部署在 K8s 的应用,磁盘大小会远远低于物理机,无法把所有日志长期存储,又有查询历史数据的诉求
日志数据非常关键,不允许丢失,即使是在应用重启实例重建后
希望对日志做一些关键字等信息的报警,以及监控大盘
权限管控非常严格,不能使用或者查询例如 SLS 等日志系统,需要导入到自己的日志采集系统
JAVA,PHP 等应用的异常堆栈会产生换行,把堆栈异常打印成多行,如何汇总查看呢?
那么在实际生产环境中,用户是如何使用日志功能采集的呢?而面对不同的业务场景,不同的业务诉求时,采用哪种采集方案更佳呢?Serverless 应用引擎 SAE(Serverless App Engine)作为一个全托管、免运维、高弹性的通用 PaaS 平台,提供了 SLS 采集、挂载 NAS 采集、Kafka 采集等多种采集方式,供用户在不同的场景下使用。本文将着重介绍各种日志采集方式的特点,最佳使用场景,帮助大家来设计合适的采集架构,并规避一些常见的问题。
SAE 的日志采集方式
Cloud Native
SLS 采集架构
SLS 采集日志是 SAE 推荐的日志采集方案。一站式提供数据采集、加工、查询与分析、可视化、告警、消费与投递等能力。
SAE 内置集成了 SLS 的采集,可以很方便的将业务日志,容器标准输出采集到 SLS 。SAE 集成 SLS 的架构图如下图所示: 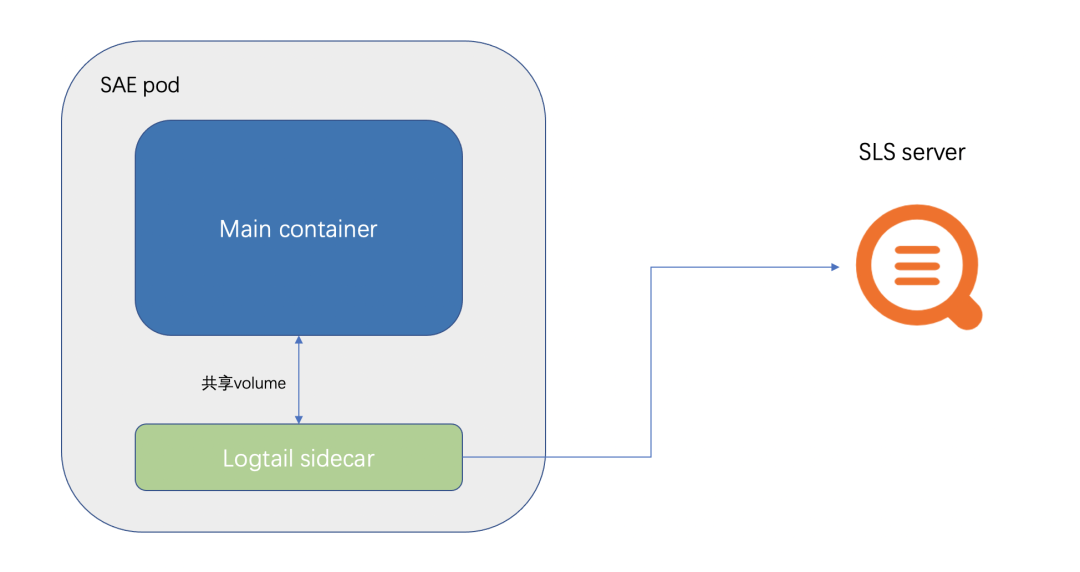
SAE 会在 pod 中,挂载一个 logtail (SLS 的采集器)的 Sidecar。
然后将客户配置的,需要采集的文件或者路径,用 volume 的形式,给业务 Container 和 logtail Sidecar 共享。这也是 SAE 日志采集不能配置/home/admin 的原因。因为服务的启动容器是放在/home/admin 中,挂载 volume 会覆盖掉启动容器。
同时 logtail 的数据上报,是通过 SLS 内网地址去上报,因此无需开通外网。
SLS 的 Sidecar 采集,为了不影响业务 Container 的运行,会设置资源的限制,例如 CPU 限制在 0.25C ,内存限制在 100M。
SLS 适合大部分的业务场景,并且支持配置告警和监控图。绝大多数适合直接选择 SLS 就可以了。
NAS 采集架构
NAS 是一种可共享访问、弹性扩展、高可靠以及高性能的分布式文件系统。本身提供高吞吐和高 IOPS 的同时支持文件的随机读写和在线修改。比较适合日志场景。如果想把比较多或比较大的日志在本地留存,可以通过挂载 NAS,然后将日志文件的保存路径指向 NAS 的挂载目录即可。NAS 挂载到 SAE 不牵扯到太多技术点和架构,这里就略过不做过多的介绍了。
NAS 作为日志采集时,可以看作是一块本地盘,即使实例崩溃重建等等各种以外情况,也都不会出现日志丢失的情况,对于非常重要,不允许丢失数据的场景,可以考虑此方案。
Kafka 采集架构
用户本身也可以将日志文件的内容采集到 Kafka,然后通过消费 Kafka 的数据,来实现日志的采集。后续用户可以结合自身的需求,将 Kafka 中的日志导入到 ElasticSearch ,或者程序去消费 Kafka 数据做处理等。
日志采集到 Kafka本身有多种方式,例如最常见的 logstach,比较轻量级的采集组建 filebeat,vector 等等。SAE 使用的采集组件是 vector,SAE 集成 vector 的架构图如下图所示: 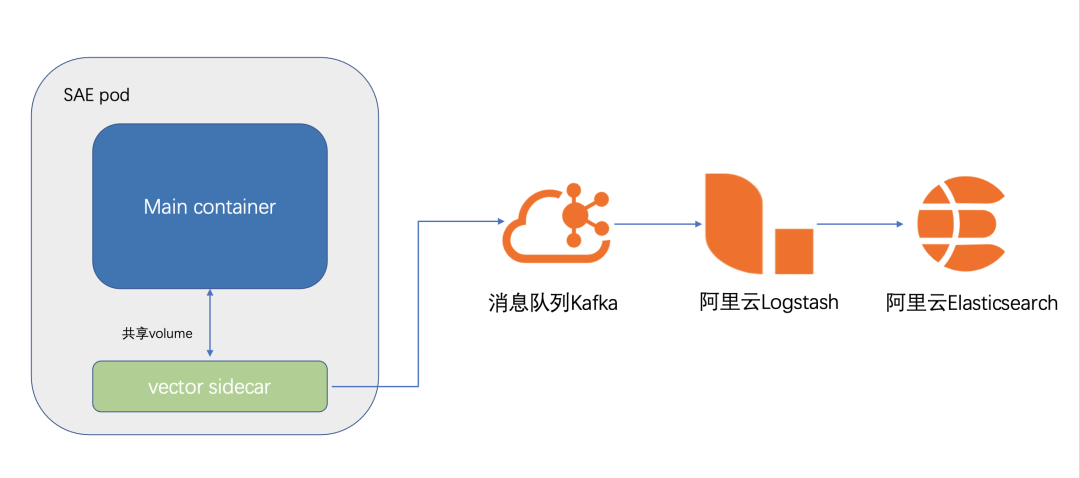
SAE 会在 pod 中,挂载一个 logtail(vector 采集器)的 Sidecar。
然后将客户配置的,需要采集的文件或者路径,用 volume 的形式,给业务 Container 和 vector Sidecar 共享
vector 会将采集到的日志数据定时发送到 Kafka。vector 本身有比较丰富的参数设置,可以设置采集数据压缩,数据发送间隔,采集指标等等。
Kafka 采集算是对 SLS 采集的一种补充完善。实际生产环境下,有些客户对权限的控制非常严格,可能只有 SAE 的权限,却没有 SLS 的权限,因此需要把日志采集到 Kafka 做后续的查看,或者本身有需求对日志做二次处理加工等场景,也可以选择 Kafka 日志采集方案。 下面是一份基础的 vector.toml 配置:
data_dir = "/etc/vector"
[sinks.sae_logs_to_kafka]
type = "kafka"
bootstrap_servers = "kafka_endpoint"
encoding.codec = "json"
encoding.except_fields = ["source_type","timestamp"]
inputs = ["add_tags_0"]
topic = "{{ topic }}"
[sources.sae_logs_0]
type = "file"
read_from = "end"
max_line_bytes = 1048576
max_read_bytes = 1048576
multiline.start_pattern = '^[^\s]'
multiline.mode = "continue_through"
multiline.condition_pattern = '(?m)^[\s|\W].*$|(?m)^(Caused|java|org|com|net).+$|(?m)^\}.*$'
multiline.timeout_ms = 1000
include = ["/sae-stdlog/kafka-select/0.log"]
[transforms.add_tags_0]
type = "remap"
inputs = ["sae_logs_0"]
source = '.topic = "test1"'
[sources.internal_metrics]
scrape_interval_secs = 15
type = "internal_metrics_ext"
[sources.internal_metrics.tags]
host_key = "host"
pid_key = "pid"
[transforms.internal_metrics_filter]
type = "filter"
inputs = [ "internal_metrics"]
condition = '.tags.component_type == "file" || .tags.component_type == "kafka" || starts_with!(.name, "vector")'
[sinks.internal_metrics_to_prom]
type = "prometheus_remote_write"
inputs = [ "internal_metrics_filter"]
endpoint = "prometheus_endpoint"
重要的参数解析:
multiline.start_pattern 是当检测到符合这个正则的行时,会当作一条新的数据处
multiline.condition_pattern 是检测到符合这个正则的行时,会和上一行做行合并,当作一条处理
sinks.internal_metrics_to_prom 配置了之后,会将配置一些 vector 的采集元数据上报到 prometheus
下面是配置了 vector 采集的元数据到 Prometheus,在 Grafana 的监控大盘处配置了 vector 的元数据的一些采集监控图: 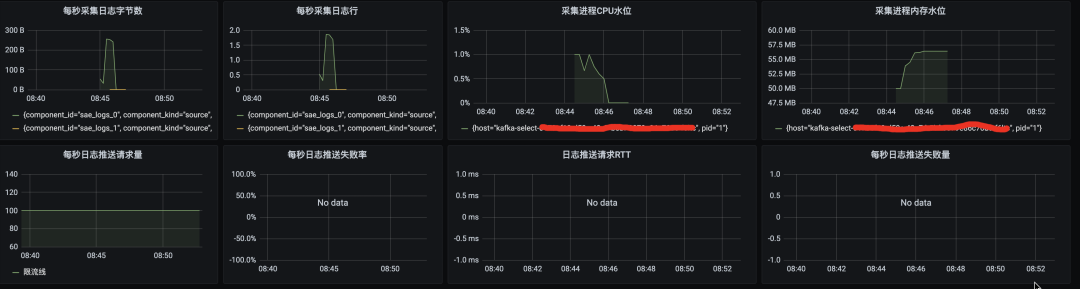
最佳实践
Cloud Native
在实际使用中,可以根据自身的业务诉求选择不同的日志采集方式。本身 logback 的日志采集策略,需要对文件大小和文件数量做一下限制,不然比较容易把 pod 的磁盘打满。以 JAVA 为例,下面这段配置,会保留最大 7 个文件,每个文件大小最大 100M。
这段 log4j 的配置,是一种比较常见的日志轮转配置。 常见的日志轮转方式有两种,一种是 create 模式,一种是 copytruncate 模式。而不同的日志采集组件,对两者的支持程度会存在一些区别。 create 模式是重命名原日志文件,创建新的日志文件替换。log4j 使用的就是这种模式,详细步骤如下图所示: 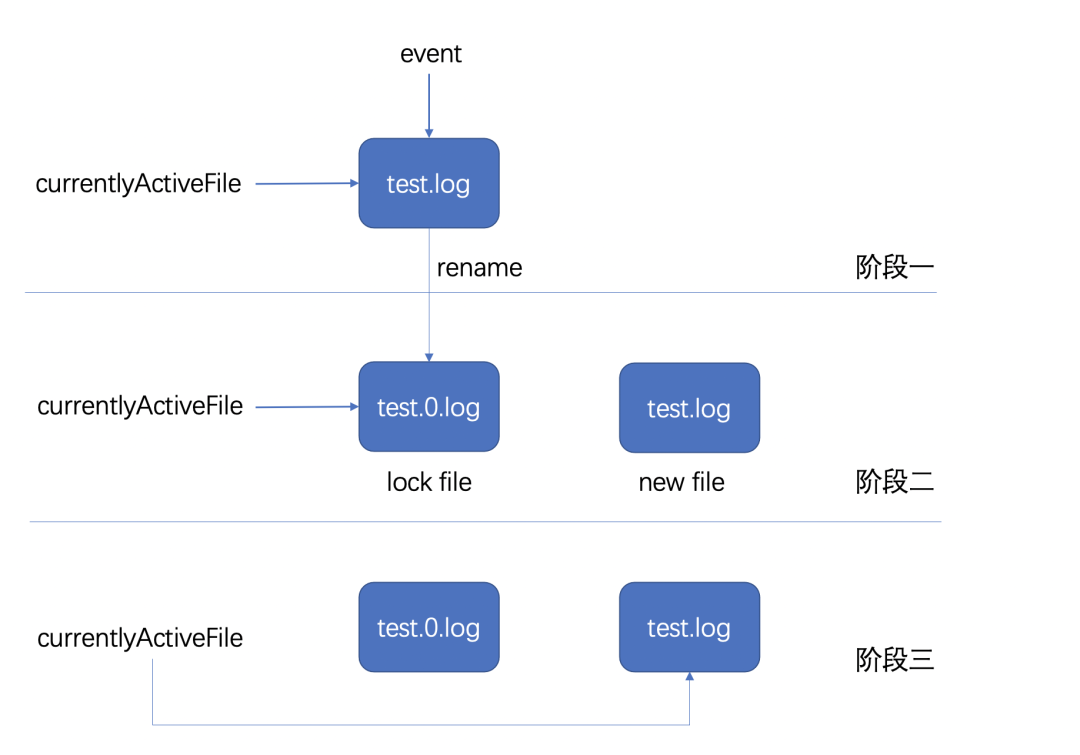
当日志的 event log 写入前会判断是否达到文件设置最大容量,如果没达到,则完成写入,如果达到了,则会进入阶段二
首先关闭当前 currentlyActiveFile 指向的文件,之后对原文件进行重命名,并新建一个文件,这个文件的名字和之前 currentlyActiveFile 指向的名字一致
把 currentlyActiveFile 指向的文件变为阶段二新创建的文件
copytruncate 模式的思路是把正在输出的日志拷(copy)一份出来,再清空(trucate)原来的日志。 目前主流组件的支持程度如下:

实际案例演示
Cloud Native
下面介绍一下客户实际生产环境中的一些真实场景。
某客户 A 通过日志轮转设置程序的日志,并将日志采集到 SLS。并通过关键字配置相关报警,监控大盘等。 首先通过 log4j 的配置,使日志文件最多保持 10 个,每个大小 200M,保持磁盘的监控,日志文件保存在/home/admin/logs 路径下。这里不进行过多介绍了,可以最佳实践场景介绍的配置。 随后通过 SAE 的 SLS 日志采集功能,把日志采集到 SLS 中。 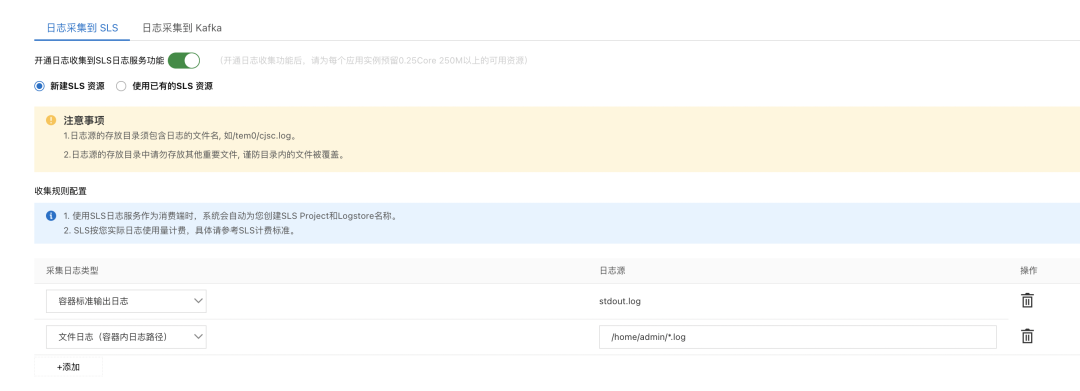
最后,通过程序中日志的一些关键字,或者一些其他规则,例如 200 状态码比例等进行了报警配置。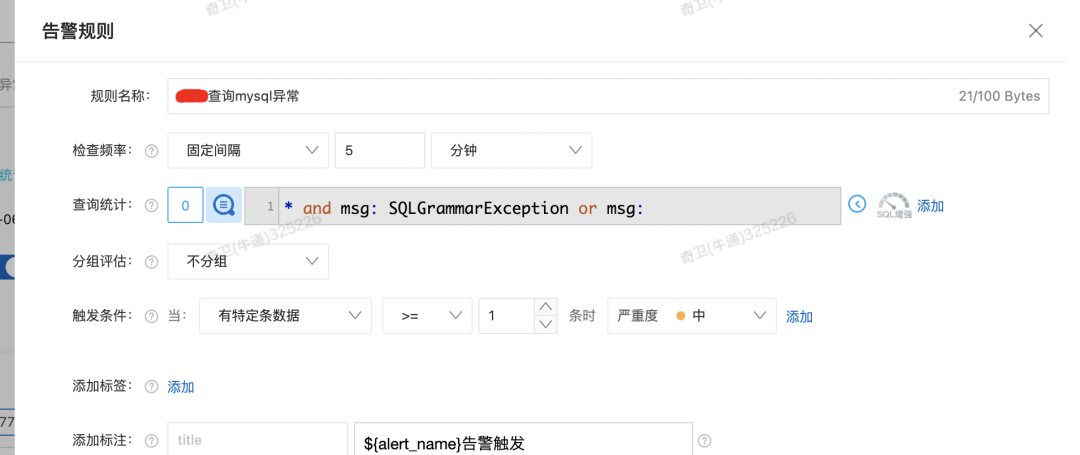
通过 Nginx 的日志完成监控大盘的配置。 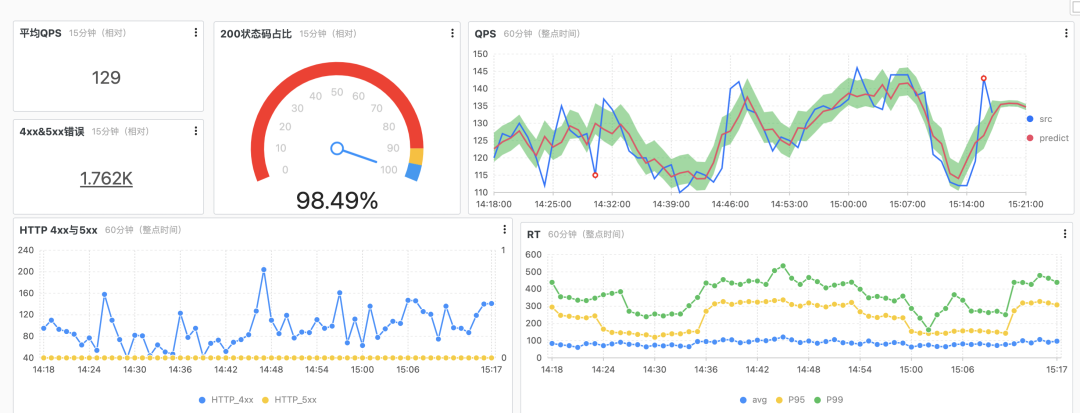
常见问题
Cloud Native
日志合并介绍
很多时候,我们需要采集日志,并不是单纯的一行一行采集,而是需要把多行日志合并成一行进行采集,例如 JAVA 的异常日志等。这个时候就需要用到日志合并功能了。
在 SLS 中,有多行模式的采集模式,这个模式需要用户设置一个正则表达式,用来做多行合并。 vector 采集也有类似的参数,multiline.start_pattern 用于设置新行的正则,符合此正则会被认为是一个新行。可以结合 multiline.mode 参数一起使用。更多参数请参看vector官网。
日志采集丢失分析
无论是 SLS 采集和 vector 采集到 Kafka 为了保证采集日志不丢失。都会将采集的点位(CheckPoint)信息保存到本地,如果遇到服务器意外关闭、进程崩溃等异常情况时,会从上一次记录的位置开始采集数据,尽量保证数据不会丢失。
但是这并不能保证日志一定不会丢失。在一些极端场景下,是有可能造成日志采集丢失的,例如: 1. K8s pod 进程崩溃,liveness 连续失败等异常导致 pod 重建 2. 日志轮转速度极快,例如1秒轮转1次。 3. 日志采集速度长期无法达到日志产生速度。 针对场景 2,3,需要去检查自身的应用程序,是否打印了过多不必要的日志,或者日志轮转设置是否异常。因为正常情况下,这些情况不应该出现。针对场景 1,如果对日志要求非常严格,在 pod 重建后也不能丢失的话,可以将挂载的 NAS 作为日志保存路径,这样即使在 pod 重建后,日志也不会丢失。
总结
Cloud Native
本文着重介绍了 SAE 提供了多种日志采集方案,以及相关的架构,场景使用特点。总结起来三点:
1、SLS 采集适配性强,实用大多数场景
2、NAS 采集任何场景下都不会丢失,适合对日志要求非常严格的场景
3、Kafka 采集是对 SLS 采集的一种补充,有对日志需要二次加工处理,或者因为权限等原因无法使用 SLS 的场景,可以选择将日志采集到 Kafka 自己做搜集处理。
审核编辑:刘清
-
富士PLC数据采集网关的功能特点及应用场景2025-04-24 1188
-
数据记录仪的计数原理和应用场景2025-02-24 582
-
meshtastic的应用场景介绍2025-02-21 1766
-
LoRaWAN的特点和应用场景2025-02-03 2676
-
日志篇:模组日志总体介绍2024-10-24 1281
-
国产光耦继电器的性能特点及应用场景2024-07-26 1737
-
工业数据采集网关的功能、特点、应用场景及其实操性2024-05-15 2325
-
FPGA和ASIC的概念、基本组成及其应用场景 FPGA与ASIC的比较2023-08-14 3546
-
贴片Y电容的各种型号及其特点介绍2023-08-04 2259
-
逐一介绍Linux各个系统的特点以及应用场景2022-08-02 3971
-
RK3308的特点及应用场景是什么?2022-03-09 2152
-
几种LED调光协议分析及具体应用场景介绍2021-12-31 2307
-
Wi-Fi6创新技术特点及应用场景2020-12-04 2643
-
消息队列的应用场景2020-06-23 2330
全部0条评论

快来发表一下你的评论吧 !
