

半监督算法DocRE的新组件
描述
今天给大家分享的是是ACL 2022上与实体关系抽取相关的部门论文范读笔记。其中有一些小喵自己也在学习,后续会推出精读笔记。
1. DocRE
论文概括:具有自适应焦点损失和知识蒸馏的文档级关系抽取
文档级关系抽取要同时从多个句子中提取关系。针对这个任务,本文提出了一个半监督算法 DocRE。DocRE 共有三个新组件:
第一,用轴向注意力模块学习实体对之间的依赖关系。
第二,提出了一个自适应的焦点损失来解决DocRE中类的不平衡问题。
最后,利用知识蒸馏来克服人工标注数据与远程监督数据之间的差异。
现有问题:现存的方法关注实体对的句法特征,而忽略了实体对之间的交互作用;目前还没有工作可以直接地解决类的不平衡问题。现存的工作仅仅关注阈值学习来平衡正例和负例,但正例内部的类不平衡问题并没有得到解决;关于将远程监督数据应用于DocRE任务的研究很少。
贡献点:
轴向注意力:提升two-hop关系的推理能力;
自适应焦点损失:解决标签分配不平衡的问题,长尾类在总的损失中占比较多;
知识蒸馏:克服标注数据和远程监督数据之间的差异。
 DocRE
DocRE
2. PL-Marker
论文名称:《Packed Levitated Marker for Entity and Relation Extraction》
论文链接:https://aclanthology.org/2022.acl-long.337.pdf
代码地址:https://github.com/thunlp/PL-Marker
论文概括:打包悬浮标记用于实体和关系抽取
最近的命名实体识别和关系抽取工作专注于研究如何从预训练模型中获得更好的span表示。然而,许多工作忽略了span之间的相互关系。本文提出了一种基于悬浮标记的span表示方法,在编码过程中通过特定策略打包标记来考虑span之间的相互关系。对于命名实体识别任务,提出了一种面向邻居span的打包策略,以更好地建模实体边界信息。对于关系抽取任务,设计了一种面向头实体的打包策略,将每个头实体以及可能的尾实体打包,以共同建模同头实体的span对。
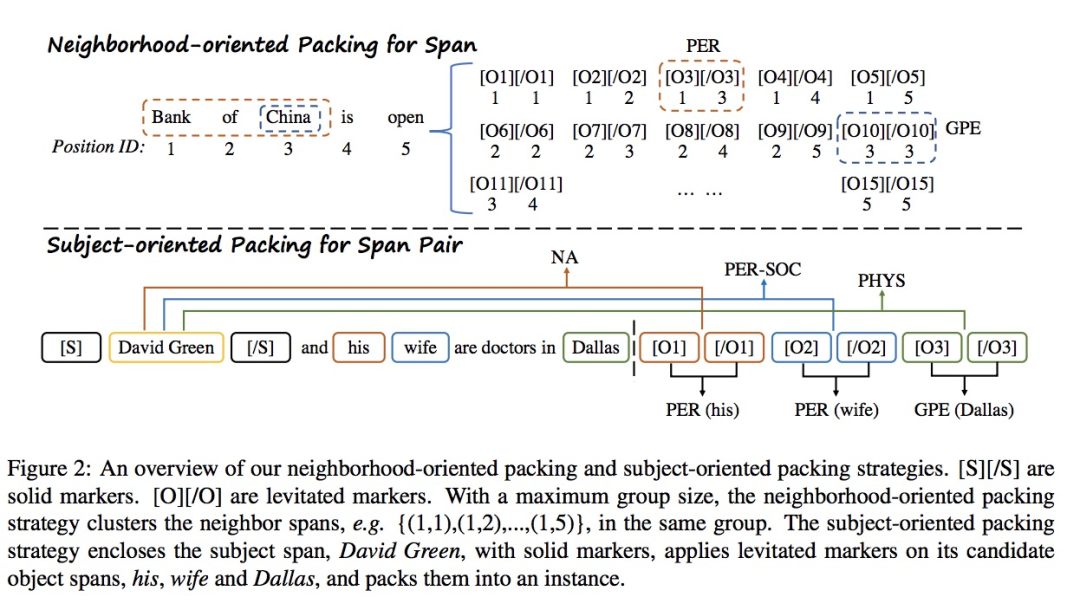 PL-Marker
PL-Marker
3. CRL
论文名称:《Consistent Representation Learning for Continual Relation Extraction》
论文链接:https://aclanthology.org/2022.findings-acl.268.pdf
代码地址:https://github.com/thuiar/CRL
论文概括:一致表示学习用于连续关系抽取
通过对比学习和回放记忆时的知识蒸馏,提出一种新颖的一致性表示学习方法。使用基于记忆库的监督对比学习来训练每一个新的任务,以使模型高效学习特征表示。为了防止对老任务的遗忘,构造了记忆样本的连续回放,同时让模型保留在知识蒸馏中历史任务之间的关系。
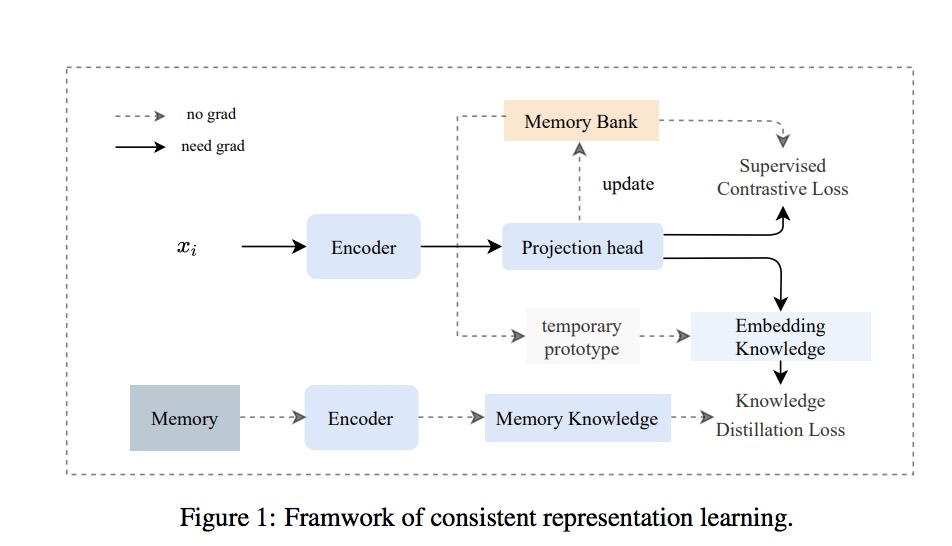 CRL
CRL
4. MCMN
论文名称:《Pre-training to Match for Unified Low-shot Relation Extraction》
论文链接:https://aclanthology.org/2022.acl-long.397.pdf
代码地址:https://github.com/fc-liu/MCMN
论文概括:预训练用于匹配统一少样本关系抽取
低样本关系抽取旨在少样本甚至零样本场景下的关系抽取。由于低样本关系抽取所包含任务形式多样,传统方法难以统一处理。本文针对这一问题,提出了一种统一的低样本匹配网络:
基于语义提示(prompt)范式,构造了从关系描述到句子实例的匹配网络模型;
针对匹配网络模型学习,设计了三元组-复述的预训练方法,以增强模型对关系描述与实例之间语义匹配的泛化性。
在零样本、小样本以及带负例的小样本关系抽取评测基准上的实验结果表明,该方法能有效提升低样本场景下关系抽取的性能,并且具备了较好的任务自适应能力。
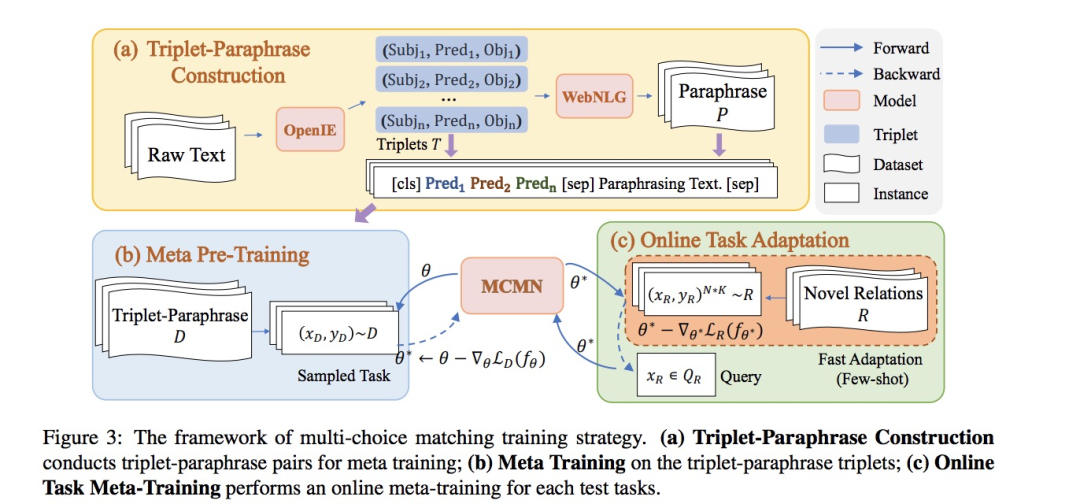
-
一种基于伪标签半监督学习的小样本调制识别算法2022-02-10 1549
-
一种基于DE和ELM的半监督分类方法2021-04-09 1211
-
一种基于光滑表示的半监督分类算法2021-04-08 953
-
一种带有局部坐标约束的半监督概念分解算法2021-03-31 1231
-
为什么半监督学习是机器学习的未来?2020-11-27 4801
-
最基础的半监督学习2020-11-02 3531
-
机器学习算法中有监督和无监督学习的区别2020-07-07 6830
-
如何约束半监督分类方法的详细资料概述2018-11-15 1267
-
基于半监督学习框架的识别算法2018-01-21 1085
-
基于最优投影的半监督聚类算法2018-01-14 886
-
基于C均值聚类和图转导的半监督分类算法2017-11-28 771
-
半监督的谱聚类图像分割2017-11-13 1073
-
基于半监督学习的跌倒检测系统设计_李仲年2017-03-19 1056
-
半监督典型相关分析算法2009-10-31 611
全部0条评论

快来发表一下你的评论吧 !
