

AI模型的演变与可解释性
人工智能
描述
人工智能正在改变几乎所有行业和应用领域的工程。随之而来的是对高 AI 模型准确性的需求。事实上,AI 模型在取代传统方法时往往更准确,但这有时也会付出代价:复杂的 AI 模型是如何做出决策的;作为工程师,我们如何验证结果是否如预期那样有效?
进入可解释 AI —— 它是一套工具和技术,可帮助我们理解模型决策,并发现黑盒模型的问题,如偏差或对抗攻击易感性。可解释性可以帮助AI模型的使用者理解机器学习模型是如何得出预测,这就像理解哪些特征驱动模型决策那样简单,但在试图解释复杂模型时会变得困难。
AI 模型的演变
为什么要大力推动可解释 AI 技术?模型并不总是那么复杂。其实,我们不妨先看一个冬季恒温器的简单示例。基于规则的模型如下所示:
低于 65 华氏度开启加热器
高于 68 华氏度关闭加热器
恒温器是否正常工作?变量包括当前室温和加热器是否工作,所以根据室内温度很容易进行验证。
由于问题的简单性或对物理关系的固有“常识性”理解,某些模型(如温度控制)本质上是可以解释的。一般来说,对于不能接受黑盒模型的应用,使用本身具有可解释性的简单模型是可行的,只要模型足够准确,就可接受并视为有效。
但是,转向更高级的模型可以带来以下优势:
准确度:
在许多情况下,复杂的模型会带来更准确的结果。有时结果可能不会立即显现出来,但可以更快地找到答案。
处理更复杂的数据:
工程师可能需要处理复杂的数据,如流信号和图像,这些数据可以直接用于 AI 模型,从而节省大量的建模时间。
复杂应用领域:
应用的复杂性不断增加,新的研究正在探索深度学习技术可以替代像特征提取等传统技术的更多领域。
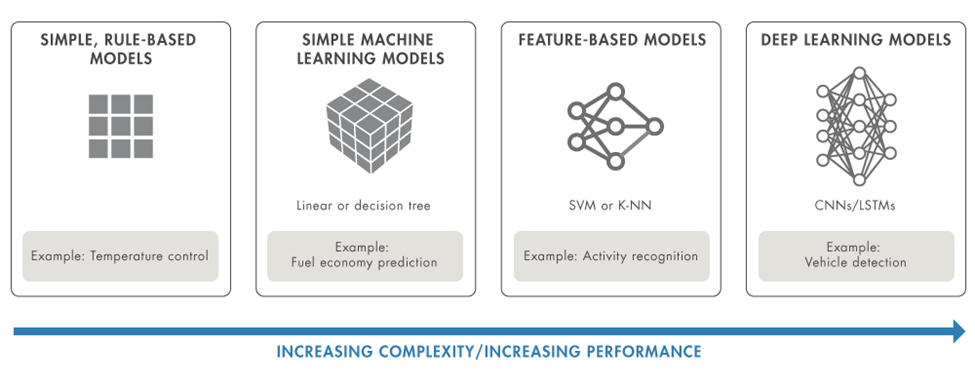
图 1:AI 模型的演变。简单模型可能具有更高的透明度,复杂的模型则可以提高性能。
为什么寻求可解释性?
AI 模型通常被称为“黑盒”,你无法看到模型在训练过程中学习了什么,也无法确定模型在未知条件下是否能按预期工作。对可解释模型的关注旨在提出有关模型的问题,以发现任何未知数并解释它们的预测、决策和行动。
复杂性与可解释性
在转向更复杂模型的过程中,理解模型内部运行情况的能力变得越来越具有挑战性。因此,随着预测能力的提升,工程师们需要找到新的方法来确保他们能够保持对模型的信心。
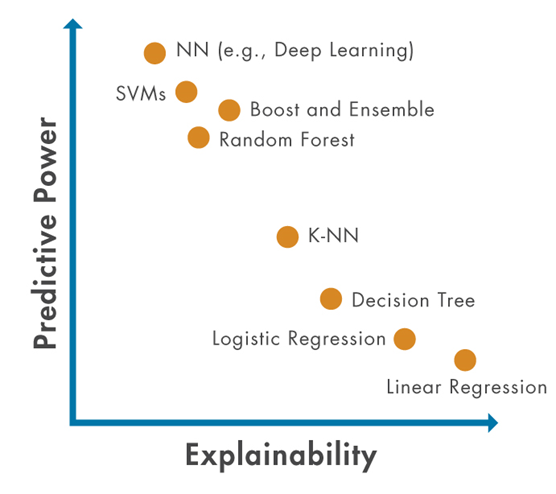
图 2:可解释性和预测能力之间的权衡。一般来说,更强大的模型往往不太容易解释,工程师将需要新的方法来实现可解释性,以确保随着预测能力的提升,他们能够保持对模型的信心。
使用可解释的模型可以提供最深入的见解,而无需为流程添加额外步骤。例如,使用决策树或线性权重可以为模型选择特定结果的原因提供确切的证据。
工程师需要更深入地了解他们的数据和模型,并出于以下原因推动可解释性研究: 1. 对模型的信心:
基于其角色以及与应用的交互,许多相关人员都很关注解释模型的能力。例如:
决策者希望信任并理解 AI 模型的工作方式。
客户希望确信应用在所有场景中都能按预期工作,并且系统的行为是合理和可理解的。
模型开发人员希望深入了解模型行为,并且可以通过了解模型做出特定决策的原因来提高准确性。
2. 监管要求:
人们越来越希望在具有内部和外部监管要求的安全关键领域和治理及合规应用中使用 AI 模型。尽管每个行业都有特定的要求,但提供训练稳健性、公平性和可信度的证据会很重要。
3. 识别偏差:
当模型在有偏差或采样不均匀的数据上进行训练时,就会引入偏差。对于应用于人的模型,偏差尤其令人担忧。模型开发人员务必要了解偏差会如何隐式地影响结果,并将这种影响纳入考虑,以便 AI 模型进行“泛化”,即提供准确的预测,而不会隐式地偏向于组和子集。
4. 调试模型:
对于处理模型的工程师来说,可解释性可以帮助分析不正确的模型预测。这可能包括调查模型或数据中的问题。下面一节将介绍一些有助于调试的具体可解释性技术。
当前的可解释性方法
可解释性方法分为两类:
全局方法:
根据输入数据和预测输出,提供模型中最具影响力的变量的概览。
局部方法:
提供对单个预测结果的解释。
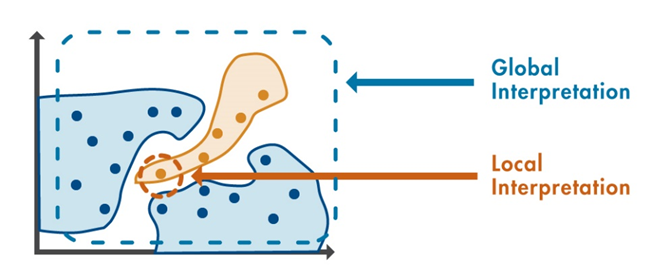
图 3:全局方法和局部方法的区别。局部方法侧重于单项预测,而全局方法侧重于多项预测。
了解特征影响
全局方法包括特征排序,它根据特征对模型预测的影响程度对特征进行排序;还包括部分依赖图,它聚焦于一个特定特征,并指出其在整个值范围内对模型预测的影响。
最常用的局部方法包括:
1. 用于机器和深度学习的 LIME:
与模型无关的局部可解释性方法 (LIME) 可用于传统机器学习和深度神经网络的解释。其主要机理是在关注点附近用一个简单、可解释的模型来逼近一个复杂模型,从而确定哪个预测变量对决策影响最大。
2. Shapely 值:
某个数据点 (也叫查询点)的特征的 Shapley 值解释了该特征导致的预测与平均预测的偏差。使用 Shapley 值解释各个特征对指定查询点处预测的影响。
可视化
在为图像处理或计算机视觉应用构建模型时,可视化是评估模型可解释性的最佳方法之一。
模型可视化:Grad-CAM 和遮挡敏感度等局部方法可以识别图像和文本中对模型预测影响最大的位置。

图 4:可视化提供对网络错误预测的深入见解。
特征比较和分组:全局方法 T-SNE 是使用特征分组来理解类别之间关系的一个示例。T-SNE 在用简单的二维图显示高维数据方面表现出色。
这些只是目前可用于帮助模型开发人员实现可解释性的众多技术中的一小部分。无论算法的细节如何,目标都是相同的:帮助工程师更深入地了解数据和模型。在 AI 建模和测试期间使用时,这些技术可以为 AI 预测提供更多洞察力和信心。
可解释性之外
可解释性有助于克服许多高级 AI 模型的黑盒性质。但消除相关人员或监管机构对黑盒模型的抵制,只是在工程系统中自信地使用 AI 的一步。在实践中应用 AI 需要使用能够被理解的模型,这些模型应遵循严格的构建流程,并且能够在符合安全关键性和敏感型应用要求的水平上运行。
持续关注和改进的领域包括:
验证和确认:
验证和确认是正在进行的一个研究领域。它对可解释性进行了拓展,从确信和证明模型在特定条件下有效,扩展到重点关注在安全关键型应用中使用的必须满足最低标准的模型。
安全认证:
汽车和航空航天等行业正在定义针对其应用的 AI 安全认证。用 AI 取代或增强的传统方法必须符合相同的标准,并且只有证明结果并显示可解释的结果,才能取得成功。
更透明的模型:
系统的输出必须符合角色的期望。这是工程师从一开始就必须考虑的问题:将如何与最终用户分享结果?
可解释性是否适合您的应用?
未来的 AI 将非常强调可解释性。随着 AI 被应用于安全至关重要的日常应用中,来自内部相关人员和外部用户的审查可能会增加。将可解释性视为每个人可以获得的基本益处。工程师可以使用更准确的信息来调试他们的模型,以确保输出与他们的直觉相匹配。他们将获得更多洞察信息来满足各种要求和标准,并且能够专注于提高日趋复杂的系统的透明度。
| 关于作者
Johanna Pingel
Johanna Pingel,MathWorks 产品经理,主要负责机器学习和深度学习应用,致力于让 AI 更实用、更有趣、更可行。她于 2013 年加入公司,擅长 MATLAB 图像处理和计算机视觉应用。
审核编辑:汤梓红
-
机器学习模型可解释性的结果分析2023-09-28 1865
-
什么是“可解释的”? 可解释性AI不能解释什么2020-05-31 9409
-
机器学习模型的“可解释性”的概念及其重要意义2018-07-24 20925
-
神经网络可解释性研究的重要性日益凸显2019-06-27 6228
-
深度理解神经网络黑盒子:可验证性和可解释性2019-08-15 14459
-
Explainable AI旨在提高机器学习模型的可解释性2020-03-24 3795
-
机器学习模型可解释性的介绍2020-12-10 1605
-
图神经网络的解释性综述2021-04-09 3601
-
《计算机研究与发展》—机器学习的可解释性2022-01-25 1857
-
关于机器学习模型的六大可解释性技术2022-02-26 3196
-
机器学习模型的可解释性算法详解2022-02-16 6484
-
使用RAPIDS加速实现SHAP的模型可解释性2022-04-21 3894
-
可以提高机器学习模型的可解释性技术2023-02-08 2465
-
文献综述:确保人工智能可解释性和可信度的来源记录2023-04-28 2926
-
小白学解释性AI:从机器学习到大模型2025-02-10 1620
全部0条评论

快来发表一下你的评论吧 !
