

基于图文多模态领域典型任务
描述
图文多模态领域典型任务如img-text retrieval、VQA、captioning、grounding等,目前的学术设定难度尚可。但是, 一旦知识范围扩展,到了open-ended scenario,任务难度立刻剧增 。但是DeepMind的Flamingo模型在这些挑战场景中使用同一个模型便做到了。当时看到论文中的这些例子,十分惊讶!

可以看到,Flamingo模型不仅可以做到open-ended captioning、VQA等,甚至可以计数、算数。其中很多额外的知识,比如火烈鸟的发源地等知识,对于单模态的语言模型如GPT-3、T5、Chinchilla等可以说是难度不大。
但是对于传统的多模态模型而言,很难通过传统的img-text pair学到如此广阔的外部知识,因为很多知识是蕴含在基于文本的单模态中的(如维基百科) 。所以,DeepMind在多模态领域的发力点就在 站人语言模型的巨人肩膀上,冻住超大规模训练的语言模型,将多模态模型设计向NLP大模型靠拢。
Frozen
要介绍Flamingo模型,不得不先介绍DeepMind在NeurIPS 2021发表的前作Frozen。Frozen模型十分简单,作者使用一个预训练好的语言模型,并且完全冻结参数,只训练visual encoder。
模型结构:其中LM模型是在C4数据上训练的包含7B参数的transformer结构,visual encoder是NF-ResNet50。训练数据:训练时只采用了CC3M数据集,包含300万img-text pair,预训练数据量不大。Frozen框架如下。其中视觉特征可以看作是LM模型的prompt,冻结的语言模型就在视觉特征的“提示”下,做出应答。
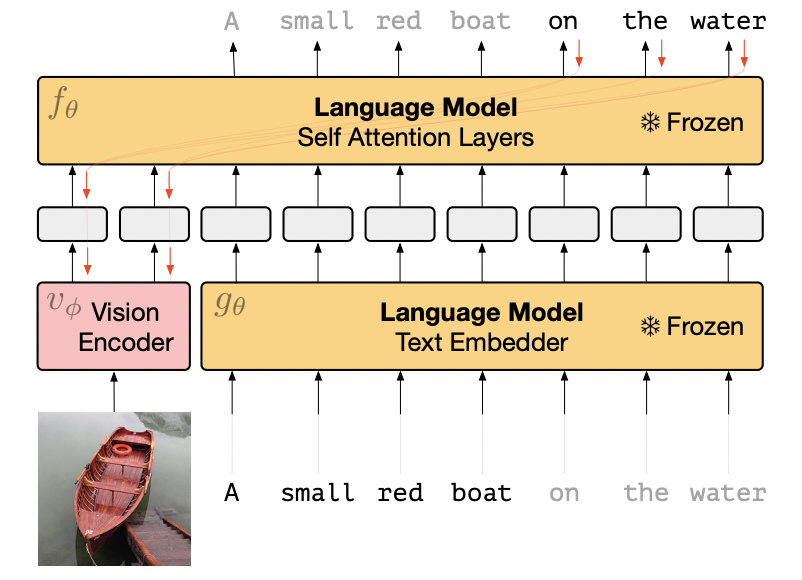
Frozen模型结构
可以看到,通过一些img-text pair的约束,unfrozen的visual encoder是朝着frozen LM靠拢和对齐的。该算法在预训练时只使用了captioning语料CC3M,并且知识的丰富度也有限。那么,Frozen模型能做什么呢?
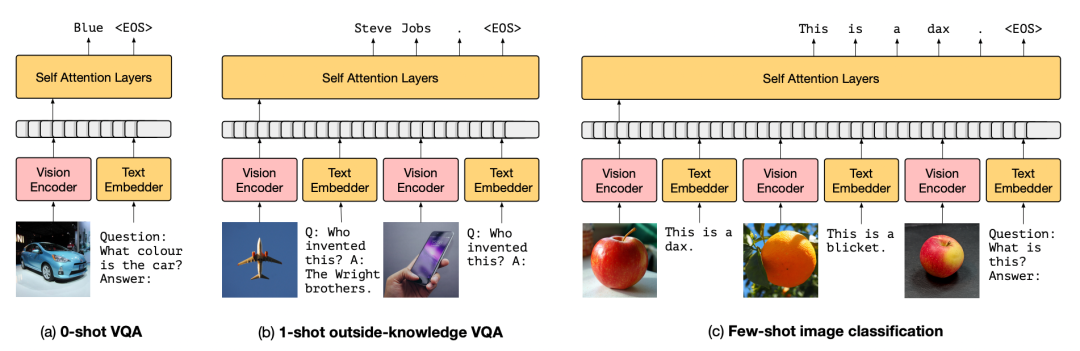
Frozen模型在下游场景的应用
虽然由caption数据(CC3M)训练,它竟然可以做VQA甚至基于知识的VQA,比如上图,你告诉它飞机是莱特兄弟发明的,它就能类比出苹果手机是乔布斯创造的。很显然, 这种外部知识肯定不是CC3M中有限的img-text pair能够给予的,无非是来源于从始至终未参与训练、冻结的LM模型 。接下来作者做了一系列实验,可以看到,其实Frozen距离SOTA模型仍十分遥远。
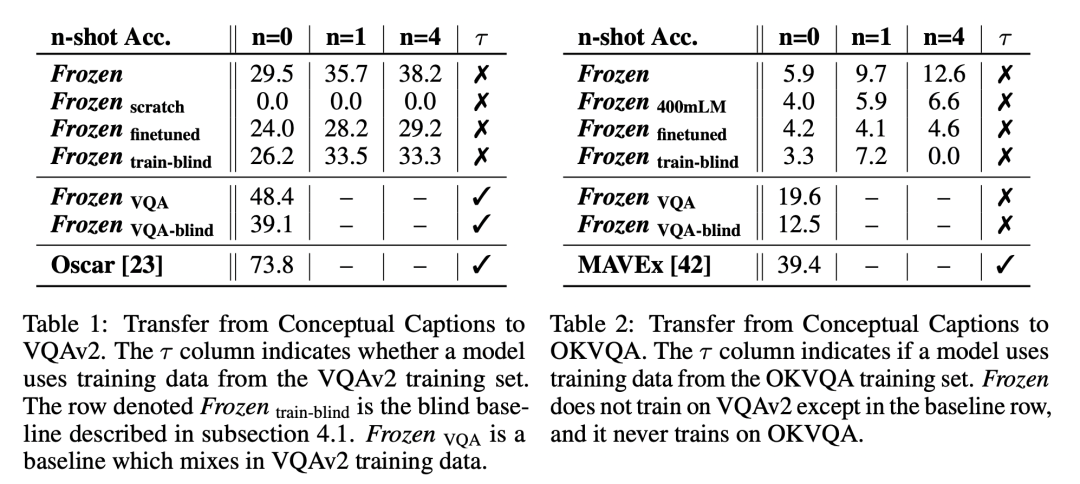
Frozen实验结果
可以看到,Frozen模型距离VQA和OKVQA数据集上的SOTA算法仍有十分巨大的gap。
几个有意思的现象:
如果模型看不到图片(blind模型),只依赖于LM模型,效果尚可,但是明显低于看得见图片的模型。 说明Frozen确实对img-text模态进行了对齐,学习到了如何参考图片信息再做出应答 ;
few-shot甚至zero-shot就可以达到还不错的性能;
end-to-end finetune LM模型效果会下降,说明由大量单模态训练出的LM模型参数很容易被少量的img-text数据破坏掉。证明了本文观点,LM模型需要Frozen才能保留文本信息学到的知识!
Flamingo
介绍完了Frozen,那么DeepMind团队再接再厉,创造效果惊艳的Flamingo模型就顺理成章了。相比于Frozen,Flamingo模型的几点改进:
更强的LM模型: 70B参数的语言模型Chinchilla;
更多的可训练参数: visual encoder这次也冻结了,但是图片特征采样模型可以训练,更重要的是LM模型的各层中也嵌入了可学习的参数,可训练参数总量高达10B;
更恐怖的训练数据:不仅加入了ALIGN算法的18亿img-text pair,数百万的video-text pair。此外,还有大量的不匹配的图文信息,来源于MultiModal MassiveWeb (M3W) dataset,其中图片数量上亿,文本大概有182 GB。可以使用unpaired img-text数据进行训练也是Flamingo模型的一大亮点。总而言之,它的数据量十分恐怖,已经远远超过目前业界的多模态算法比如CLIP、ALIGN、SimVLM、BLIP等。
下面看看Flamingo的模型结构:
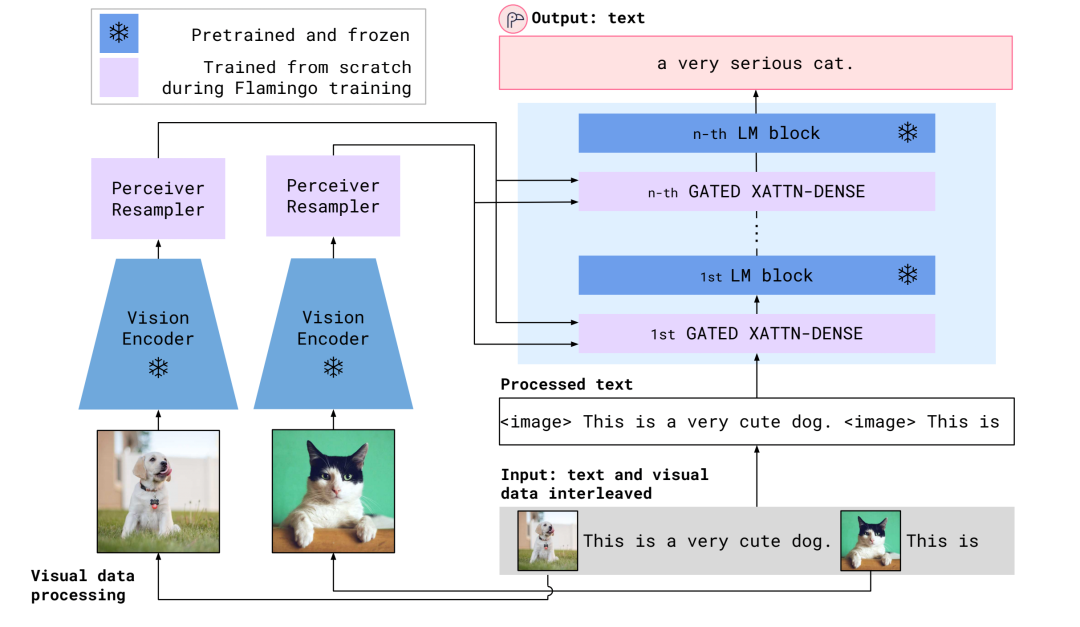
Flamingo模型结构
可以看到, 不同于Frozen,这一次visual encoder也是冻结的。参数可以学习的就两部分,一个是Perceiver Resampler,一个是嵌入在LM模型中的Gated Block。Perceiver Resampler结构如下:
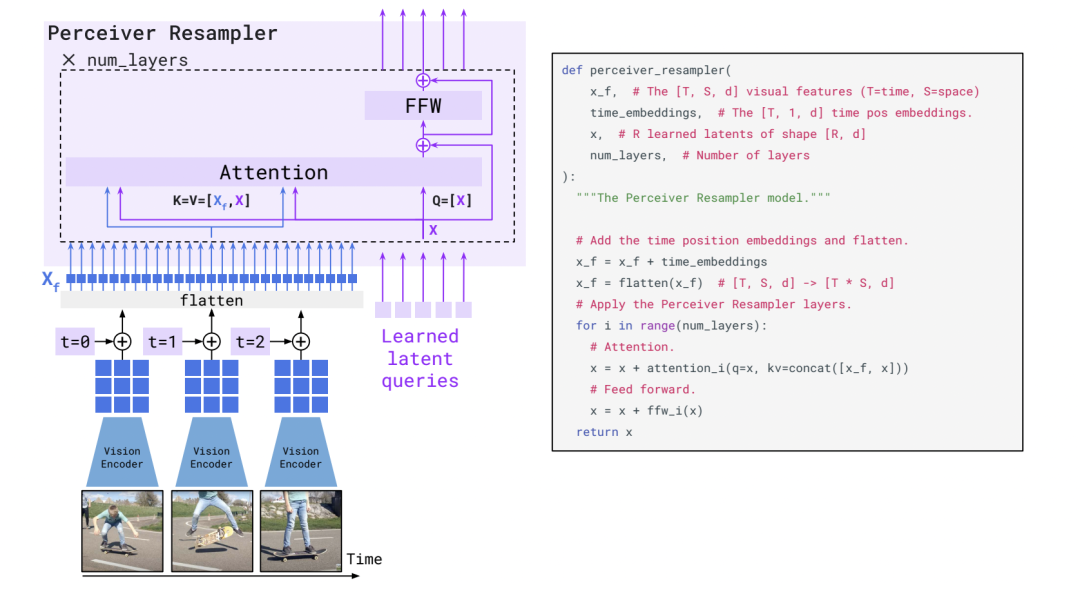
Perceiver Resampler结构
Perceiver Resampler结构一目了然,一些可学习的embedding作为query,然后图片特征或者时续的视频特征attend到query上,作为最后的输出。
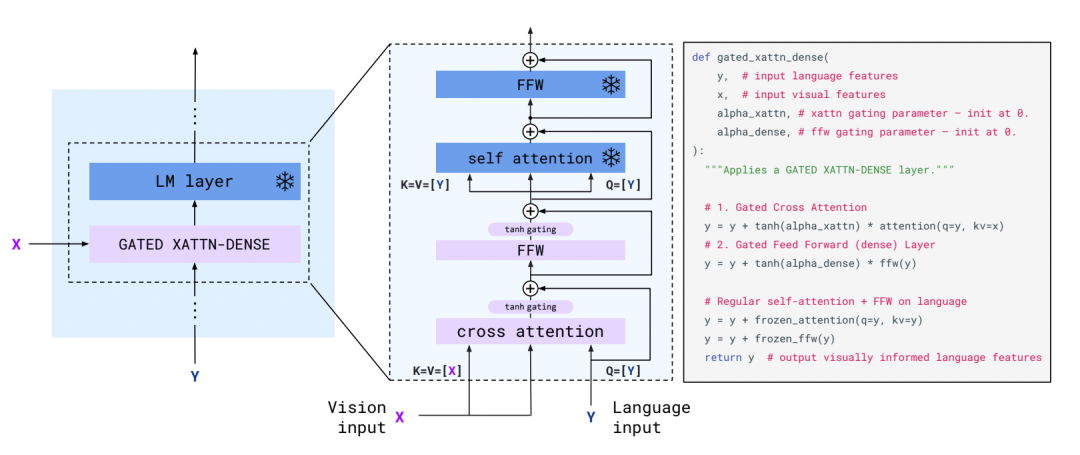
gated xattn-dense结构
嵌入在LM模型中的gated xattn-dense的结构同样一目了然,使用文本信息作为query去aggregate视觉信息。其中text embedding作为query,visual embedding作为key和value。类比于transformer结构,唯一小的差别就是cross-attention和FFN之后额外加了一个gate。
介绍完了Flamingo的模型结构,简单看看它的爆表性能吧,可以说,下游场景中只用few-shot的情况下做到这种程度,让人惊讶...... 在一些答案集合固定的任务中,比如传统的VQAv2中优势不明显, 但是open-ended的knowledge-based VQA任务中,比如OKVQA,只用few-shot就可以刷新当前SOTA 。 在盲人场景的VizWiz以及OCR信息特别多的TextVQA等任务中,效果同样可圈可点。一些基于视频的QA比如NextQA和iVQA效果同样刷新当前最好性能......
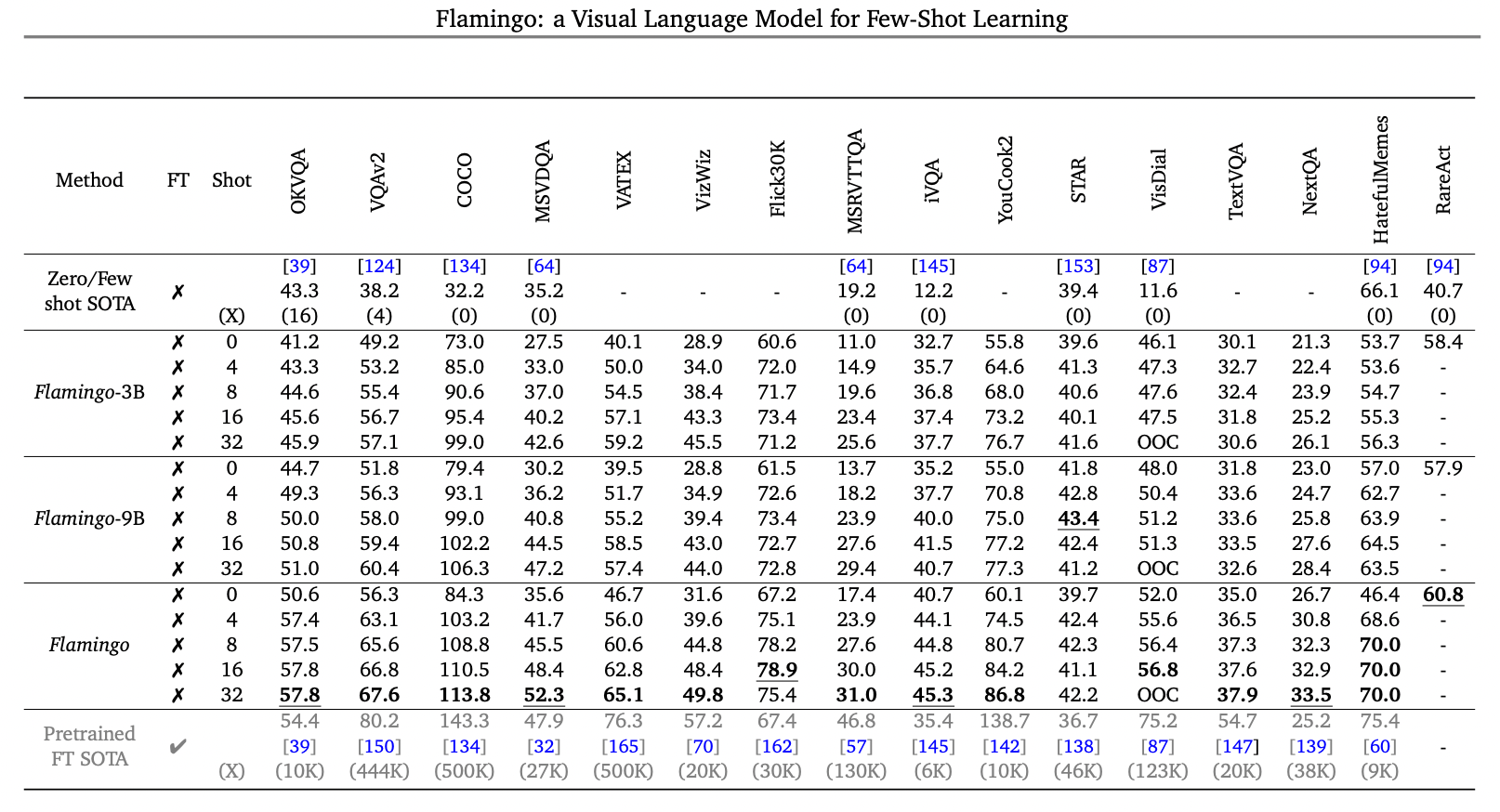
如果Flamingo不使用few-shot模式,而进行fine-tune模式,论文中显示,同样可以刷新不少业界SOTA指标,这里就不列举了。最后再列出几个让人惊叹的示例结束本文,准备再去好好研究一番论文细节。
多模态描述,多模态问答,多模态对话,多模态推荐……以前很多人觉得很遥远,但是近年来进展飞速,距离实际场景的gap也在逐步缩小,未来可期~


-
《多模态大模型 前沿算法与实战应用 第一季》精品课程简介2026-05-01 186
-
体验MiniCPM-V 2.6 多模态能力jf_23871869 2025-01-20
-
多文化场景下的多模态情感识别2017-12-18 1279
-
如何让Transformer在多种模态下处理不同领域的广泛应用?2021-03-08 3544
-
简述文本与图像领域的多模态学习有关问题2021-08-26 7924
-
如何使用多模态信息做prompt2021-11-03 2658
-
一个真实闲聊多模态数据集TikTalk2023-02-09 3824
-
中文多模态对话数据集2023-02-22 2482
-
如何利用LLM做多模态任务?2023-05-11 1905
-
更强更通用:智源「悟道3.0」Emu多模态大模型开源,在多模态序列中「补全一切」2023-07-16 1682
-
基于视觉的多模态触觉感知系统2023-10-18 2280
-
人工智能领域多模态的概念和应用场景2023-12-15 14195
-
海康威视发布多模态大模型文搜存储系列产品2025-02-18 1665
-
格灵深瞳多模态大模型Glint-ME让图文互搜更精准2025-11-02 1978
-
商汤SenseNova U1图文交错增强版开源,支持多页连续创作2026-06-16 182
全部0条评论

快来发表一下你的评论吧 !
