

辐射场Plenoxels的感知数据集详解
人工智能
643人已加入
描述
作者丨黄浴
来源丨 计算机视觉深度学习和自动驾驶
arXiv论文“PeRFception: Perception using Radiance Fields“,2022年8月24日,PosTech、Nvidia和加州理工的工作。 隐式3D表示,即神经辐射场(NERF)的最新进展,使得可微分方式进行精确和真实感的3D重建成为可能。这种新的表示法可以以一种紧凑的格式有效地传达数百幅高分辨率图像的信息,并允许照片真实感合成新视图。这项工作,采用NeRF的变型,称为Plenoxels(“Plenoxels: Radiance fields without neural networks“. arXiv:2112.05131, 2021),创建第一个用于感知任务的大规模隐式表示数据集,称为PeRFception数据集,由两部分组成,包括以目标为中心和以场景为中心的扫描数据,用于分类和分割。PeRFception显示了原始数据集的显著内存压缩率(96.4%),同时以统一的形式包含2D和3D信息。作者构建了直接将这种隐式格式作为输入的分类和分割模型,并提出一种新的数据增强技术,避免图像背景的过拟合。代码和数据:https://postech-cvlab.github.io/PeRFception/.将低维坐标映射到场景的局部属性(如占用率、正负距离场或辐射场),可以表示3D场景。这种隐式表示提供了显式表示(如体素、网格和点云)没有的优点:更平滑的几何体、更少的存储空间、具有高保真度的新视图合成等等。因此,隐式表示已用于三维重建、新视图合成、姿态估计、图像生成等。特别是,神经辐射场(NeRF)表明,隐式网络,把静态场景表示为输出视角相关辐射场的隐式5D函数,可以捕捉精确的几何关系,并渲染真实感图像。它们使用可微分的体渲染、场景几何和视图相关的辐射,可以通过图像监督编码到隐式网络中。与传统的显式3D表示不同,这些组件允许网络以可微分的方式捕获高保真光度特征,例如反射和折射。事实上,NeRF存在缺点,阻碍了在3D场景和感知的标准数据格式广泛采用隐式表示。首先,训练隐式网络很慢,可能需要几天的时间。推理(体渲染)也可能需要几分钟,限制了NERF实时应用。第二,场景的几何和视觉属性隐式地编码为神经网络的权重。这些事实阻止了现有的感知流水线去直接处理信息。第三,隐式特征或权重是场景特定的,不能在场景之间迁移。然而,对于感知,通道或特征必须具有一致的结构,例如图像的RGB通道。例如,如果从图像到图像通道的顺序表现不同,则图像分类流水线将无法正常工作。最近的研究采用显式稀疏体素网格几何和特征基函数解决了这些限制。首先,为了解决速度慢的问题,使用显式稀疏体素几何,跳过空白空间来减少沿射线的采样数。其次,直接优化分配给显式几何结构的特征,而不是使用网络权重的隐式表示,减少了从网络中提取特征的时间。最后,场景之间的一致特征,对于感知或创建不同目标的NeRF格式的场景至关重要,Plenoxels满足数据表示的所有标准,支持快速学习和渲染,同时保持场景感知和合成的一致特征表示。Plenoxels (plenoptic voxels),将场景表示为具有球谐(spherical harmonics)函数的稀疏三维网格。该表示通过梯度方法和正则化从校准图像中优化,无需任何神经组件。Plenoxels的优化速度比神经辐射场(NeRF)快两个数量级,而视觉质量没有损失。如图所示:给定一组目标或场景的图像,重建(a)稀疏体素(“Plenoxel”)网格,每个体素具有密度和球谐系数。为了渲染光线,(b)通过相邻体素系数的三线性插值计算每个采样点的颜色和模糊度。如同NeRF,用(c)可微分体绘制来整合这些样本的颜色和模糊度。然后,可以用相对于训练图像的标准MSE重建损失以及TV(total variation)正则化来(d)优化体素系数。
隐式3D表示,即神经辐射场(NERF)的最新进展,使得可微分方式进行精确和真实感的3D重建成为可能。这种新的表示法可以以一种紧凑的格式有效地传达数百幅高分辨率图像的信息,并允许照片真实感合成新视图。这项工作,采用NeRF的变型,称为Plenoxels(“Plenoxels: Radiance fields without neural networks“. arXiv:2112.05131, 2021),创建第一个用于感知任务的大规模隐式表示数据集,称为PeRFception数据集,由两部分组成,包括以目标为中心和以场景为中心的扫描数据,用于分类和分割。PeRFception显示了原始数据集的显著内存压缩率(96.4%),同时以统一的形式包含2D和3D信息。作者构建了直接将这种隐式格式作为输入的分类和分割模型,并提出一种新的数据增强技术,避免图像背景的过拟合。代码和数据:https://postech-cvlab.github.io/PeRFception/.将低维坐标映射到场景的局部属性(如占用率、正负距离场或辐射场),可以表示3D场景。这种隐式表示提供了显式表示(如体素、网格和点云)没有的优点:更平滑的几何体、更少的存储空间、具有高保真度的新视图合成等等。因此,隐式表示已用于三维重建、新视图合成、姿态估计、图像生成等。特别是,神经辐射场(NeRF)表明,隐式网络,把静态场景表示为输出视角相关辐射场的隐式5D函数,可以捕捉精确的几何关系,并渲染真实感图像。它们使用可微分的体渲染、场景几何和视图相关的辐射,可以通过图像监督编码到隐式网络中。与传统的显式3D表示不同,这些组件允许网络以可微分的方式捕获高保真光度特征,例如反射和折射。事实上,NeRF存在缺点,阻碍了在3D场景和感知的标准数据格式广泛采用隐式表示。首先,训练隐式网络很慢,可能需要几天的时间。推理(体渲染)也可能需要几分钟,限制了NERF实时应用。第二,场景的几何和视觉属性隐式地编码为神经网络的权重。这些事实阻止了现有的感知流水线去直接处理信息。第三,隐式特征或权重是场景特定的,不能在场景之间迁移。然而,对于感知,通道或特征必须具有一致的结构,例如图像的RGB通道。例如,如果从图像到图像通道的顺序表现不同,则图像分类流水线将无法正常工作。最近的研究采用显式稀疏体素网格几何和特征基函数解决了这些限制。首先,为了解决速度慢的问题,使用显式稀疏体素几何,跳过空白空间来减少沿射线的采样数。其次,直接优化分配给显式几何结构的特征,而不是使用网络权重的隐式表示,减少了从网络中提取特征的时间。最后,场景之间的一致特征,对于感知或创建不同目标的NeRF格式的场景至关重要,Plenoxels满足数据表示的所有标准,支持快速学习和渲染,同时保持场景感知和合成的一致特征表示。Plenoxels (plenoptic voxels),将场景表示为具有球谐(spherical harmonics)函数的稀疏三维网格。该表示通过梯度方法和正则化从校准图像中优化,无需任何神经组件。Plenoxels的优化速度比神经辐射场(NeRF)快两个数量级,而视觉质量没有损失。如图所示:给定一组目标或场景的图像,重建(a)稀疏体素(“Plenoxel”)网格,每个体素具有密度和球谐系数。为了渲染光线,(b)通过相邻体素系数的三线性插值计算每个采样点的颜色和模糊度。如同NeRF,用(c)可微分体绘制来整合这些样本的颜色和模糊度。然后,可以用相对于训练图像的标准MSE重建损失以及TV(total variation)正则化来(d)优化体素系数。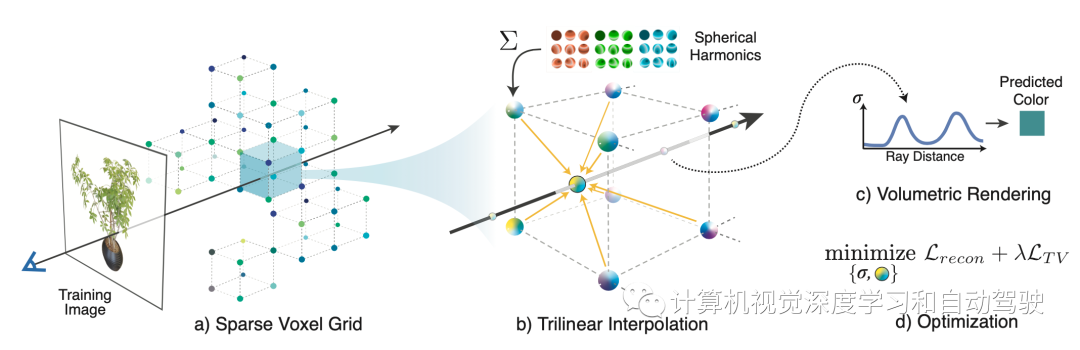 这里PeRFception数据集以一种紧凑的格式输送视觉(球谐系数)和几何(密度、稀疏体素网格)特征,可以直接应用于各种感知任务,包括2D分类、3D分类和3D分割,如图所示。
这里PeRFception数据集以一种紧凑的格式输送视觉(球谐系数)和几何(密度、稀疏体素网格)特征,可以直接应用于各种感知任务,包括2D分类、3D分类和3D分割,如图所示。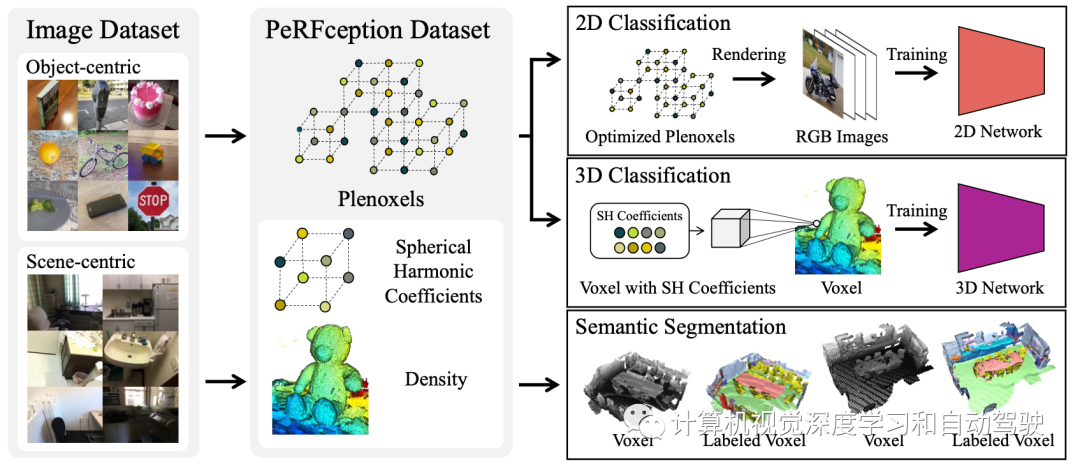
与传统的基于MLP的NeRF不同,NeRF使用单个神经网络来表示整个场景,Plenoxels独立优化每个非空体素中的球谐系数,用与NeRF中描述的体渲染相同的可微分模型,如下所示:
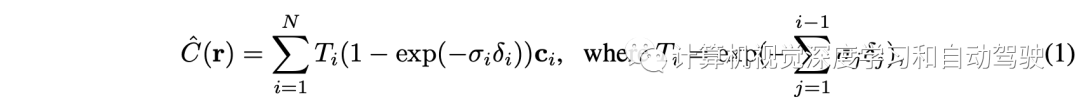 Plenoxels在稀疏体素网格中查找存储的密度和球谐系数。对于具有背景的场景,Plenoxels还使用lumisphere背景表示来渲染背景。下表1是PeRFception和目前开源数据集的对比:
Plenoxels在稀疏体素网格中查找存储的密度和球谐系数。对于具有背景的场景,Plenoxels还使用lumisphere背景表示来渲染背景。下表1是PeRFception和目前开源数据集的对比: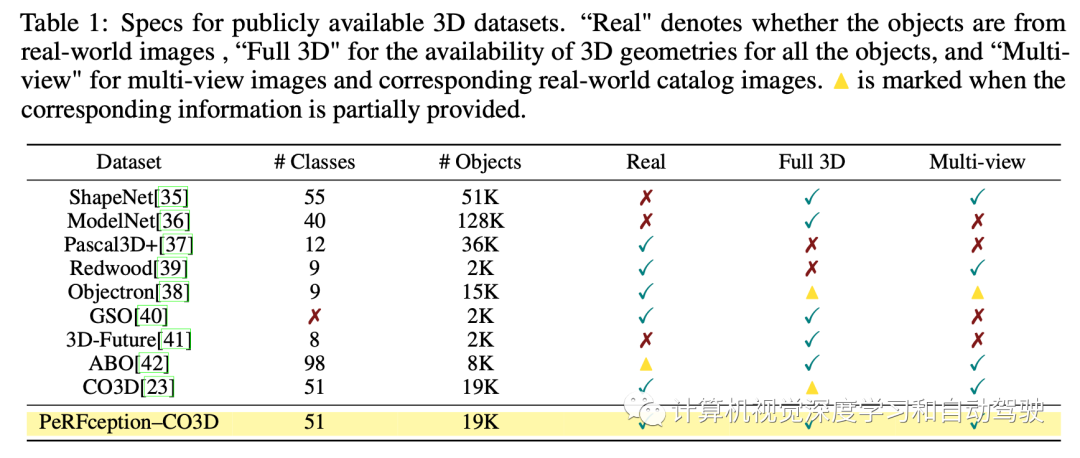 下表2是PeRFception和CO3D和ScanNet进行对比:把Plenoxels分别应用它们,生成两个新数据集。
下表2是PeRFception和CO3D和ScanNet进行对比:把Plenoxels分别应用它们,生成两个新数据集。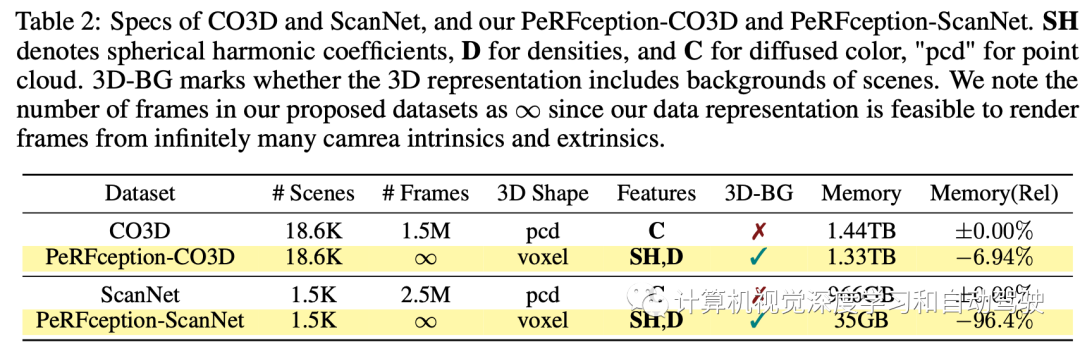 对于PeRFception-CO3D数据生成,用Plenoxels的官方实现,对默认配置进行了轻微修改。将背景亮度层的分辨率从1024降低到512,背景层的数量从64降低到16。对于更清晰的表面,将lambda稀疏度值设置为10^−10,比默认配置大10倍。以1283分辨率初始化一个体素网格,并训练25600次迭代。然后,将其上采样一次至256^3分辨率,并为进一步的51200次迭代进行训练。在保存数据之前,将训练参数量化为无符号8比特,最小化存储(密度值除外)。对于每个场景,首先过滤掉有缺陷的图像,并将10%的图像均匀采样作为测试集,评估渲染质量。对于PeRFception-SCANNet数据生成,ScanNet相当数量的帧包含运动模糊,这可能导致较差的场景几何。在实践中,在训练之前生成射线批处理,并将其加载到CPU内存中,以便在训练期间有效利用内存带宽。由于ScanNet中每个场景的帧数不同,最多使用均匀采样的1500个图像帧。对于少于1500幅图像的场景,滤除具有Laplacian低方差的模糊图像。ScanNet的另一个特点是,图像是从里向外的房间内捕获的。这样观察空间同一部分的图像较少,从而导致在ScanNet数据集上重建Plenoxel几何结构的效果不佳。具体而言,Plenoxel重建会人为地在空白空间中创建过多体素(即漂浮物),最小化图像重建损失。相反,为了在Plenoxel训练之前提供额外的几何先验知识,用ScanNet中提供的反投影深度图初始化体素网格,而不是从密集体素网格开始。然而,由于所提供的ScanNet深度图受到噪声观测的污染,结合CCA(connected component analysis)来过滤反投影点云中的分离出格点。这带来稳定和更精确的重建,并且不会过度生成漂浮物最小化渲染损失。产生的PeRFception-ScanNet数据集仅占用35GB的磁盘空间,而ScanNet的原始视频流需要大约966GB的磁盘。这是一个显著的压缩率(96.4%),强调了其作为数据集表示的可访问性。下表3是生成数据集PeRFception的渲染质量:
对于PeRFception-CO3D数据生成,用Plenoxels的官方实现,对默认配置进行了轻微修改。将背景亮度层的分辨率从1024降低到512,背景层的数量从64降低到16。对于更清晰的表面,将lambda稀疏度值设置为10^−10,比默认配置大10倍。以1283分辨率初始化一个体素网格,并训练25600次迭代。然后,将其上采样一次至256^3分辨率,并为进一步的51200次迭代进行训练。在保存数据之前,将训练参数量化为无符号8比特,最小化存储(密度值除外)。对于每个场景,首先过滤掉有缺陷的图像,并将10%的图像均匀采样作为测试集,评估渲染质量。对于PeRFception-SCANNet数据生成,ScanNet相当数量的帧包含运动模糊,这可能导致较差的场景几何。在实践中,在训练之前生成射线批处理,并将其加载到CPU内存中,以便在训练期间有效利用内存带宽。由于ScanNet中每个场景的帧数不同,最多使用均匀采样的1500个图像帧。对于少于1500幅图像的场景,滤除具有Laplacian低方差的模糊图像。ScanNet的另一个特点是,图像是从里向外的房间内捕获的。这样观察空间同一部分的图像较少,从而导致在ScanNet数据集上重建Plenoxel几何结构的效果不佳。具体而言,Plenoxel重建会人为地在空白空间中创建过多体素(即漂浮物),最小化图像重建损失。相反,为了在Plenoxel训练之前提供额外的几何先验知识,用ScanNet中提供的反投影深度图初始化体素网格,而不是从密集体素网格开始。然而,由于所提供的ScanNet深度图受到噪声观测的污染,结合CCA(connected component analysis)来过滤反投影点云中的分离出格点。这带来稳定和更精确的重建,并且不会过度生成漂浮物最小化渲染损失。产生的PeRFception-ScanNet数据集仅占用35GB的磁盘空间,而ScanNet的原始视频流需要大约966GB的磁盘。这是一个显著的压缩率(96.4%),强调了其作为数据集表示的可访问性。下表3是生成数据集PeRFception的渲染质量: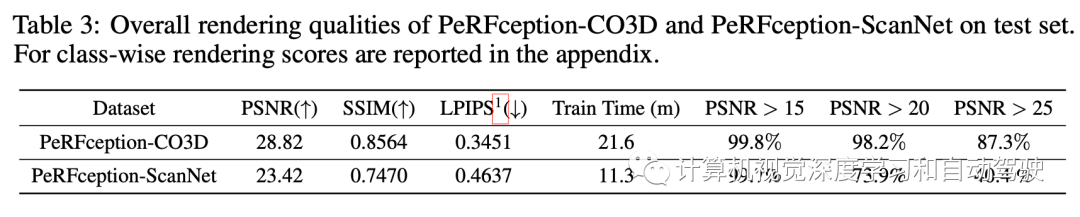
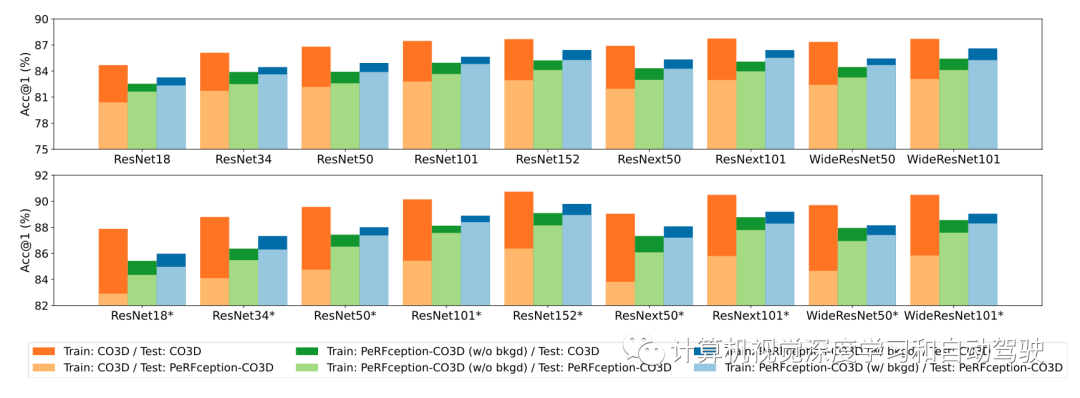
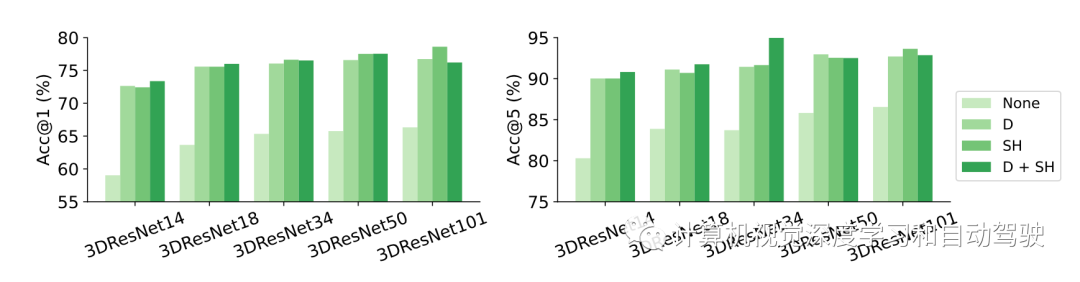
实验结果如下:
编辑:黄飞
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
基于几何分析的神经辐射场编辑方法2023-11-20 1605
-
电流探头注入替代辐射场的电磁敏感度测试方法的可行性2023-09-14 1386
-
EMC防护中半导体远场辐射2022-08-15 3919
-
Netflix Prize数据集讲解2020-06-01 1953
-
就近区场范围内的防电磁辐射整体屏蔽2019-05-30 2384
-
EMC辐射传导租场测试多少钱一个小时?2018-04-11 3479
-
字符集与字符集编码详解2017-09-12 780
-
ESD辐射场测试研究2011-06-20 825
-
ARM指令集详解2010-03-09 1160
-
核辐射剂量场实时成像测量系统的研究2009-10-21 1105
-
飞机电晕辐射场仿真2009-05-27 608
-
可调辐射场测量仪电路图2009-04-12 726
-
辐射场测量仪电路图2009-04-11 779
-
有限长V锥天线的辐射场2009-03-15 582
全部0条评论

快来发表一下你的评论吧 !
