

墨芯当选“2022中国AI芯片企业50强”
人工智能
描述
2022年8月底,稀疏化计算引领者——墨芯人工智能携高稀疏率计算卡S30、S10和S4参展「GTIC 2022全球AI芯片峰会」(以下简称GTIC),展现稀疏化计算在AI算力和能效比上的领导力,以及推动AI计算向更高算力、更高能效比、更低成本快速发展的最新商业进展。
在刚结束的上午会议中,墨芯当选“2022中国AI芯片企业50强”。
GTIC由人工智能和芯片领域权威媒体智一科技举办,本次于今年26日-27日在深圳湾万丽酒店大宴会厅举行。
在此次GTIC的核心展台——5号展台,墨芯人工智能首次向业内全面发布首批高稀疏率计算卡S4、S10和S30。
云端AI芯片市场持续扩容
稀疏化计算有力满足下游市场降本增效的需求
峰会以“不负芯光 智算未来”为主题,设置五大主题论坛——AI芯片高峰论坛、云端AI芯片专题论坛、边缘端AI芯片专题论坛等。26日下午墨芯人工智能创始人兼CEO王维以“面向未来的稀疏化计算”发表演讲,全面阐述了稀疏化计算如何推动AI计算降本增效,以及这其中蕴含的社会价值和经济价值。
AI、5G等新兴产业的蓬勃发展催生了海量数据和计算需求,市场需要强大、普惠的算力引擎。公开数据显示,2021-2025年中国云端AI芯片市场规模CAGR预计达29%。云端AI芯片重点面向互联网、泛政府、行业应用等下游细分市场,国内广阔的市场空间为有实力的高端AI芯片厂商带来崛起机遇,这个市场背景对于稀疏化计算的发展可谓天时地利人和。
墨芯是全球最早研发稀疏化算法及架构的企业之一,并在2018年开始稀疏化的全球专利布局。
所谓稀疏化计算,是一种以人脑得到灵感的模型压缩方法。简单来说,就是通过底层创新、软硬协同设计,让神经网络模型消减冗余,以提高计算效率。
稀疏化计算相较于业内其他AI加速技术,并不是微量的差异化创新,而是能够让性能带来十倍、百倍的创新。
王维拿标志性的AI大模型——GPT-3来举例说明稀疏化计算的惊人性能表现。GPT-3有1700多亿参数,如果放在GPU上去做推理的话,需要内存量是要几百G,也就是需要很多张80G的GPU,且会有明显时延;但通过稀疏化计算,用一张墨芯S30计算卡,就可以跑通GPT-3,并且计算速度还变快了很多。
S30计算卡算力超90000 FPS
TCO约为竞品1/3
墨芯正通过打造这一套芯片和软硬件产品,去推动深度学习往更高算力、更大规模、更低计算成本的方向去发展。
墨芯此次展出的S4、S10和S30均搭载墨芯三颗芯片Antoum,分别为单芯片卡、双芯片卡和三芯片卡,专注于数据中心AI推理应用,可广泛应用于互联网、运营商、生命科学、自动驾驶等众多AI推理场景,满足客户对性能和功耗不同的组合需求。
Antoum是首个商用高稀疏率芯片,于2022年元旦一次流片成功,实测性能颠覆性提升。基于Antoum的单芯片计算卡S4首次推出后经过多方性能实测,具有以下特点:
1
高吞吐:
单芯片计算卡S4实运行ResNet-50算力达33197 FPS
2
低功耗:
S4稳定功耗仅有70W左右,实测性能对表国际大厂主流推理卡主近6倍能效比
3
低延时:
墨芯板卡S4(单颗Antoum)对比主流GPU产品,延时可以做到后者的1/4~1/5
三芯片卡S30在250W功率下提供等效于 2832 TOPS INT8 和 1415.4 TFLOPS BF16 的算力(32倍稀疏化)。板载60GB LPDDR4x内存,S30可以提供高达252 GB/s 理论内存峰值访问带宽。
墨芯人工智能S30计算卡
实测数据显示,S30相较于S4和S10,可提供更高的算力。ResNet-50和Bert-Large模型在S4、S10和S30计算卡的测试结果如下所示:
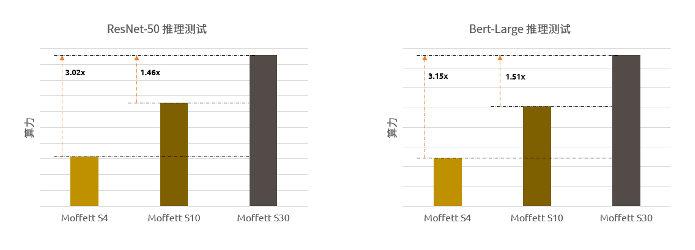
S30和S4、S10计算卡在ResNet-50和Bert-Large模型推理结果对比
TCO为主流竞品约1/3
已有多家客户
稀疏化生态发力三大市场
流片成功仅半年,墨芯人工智能已在核心细分市场获得几家客户。在互联网市场,墨芯已在一些头部互联网公司进入适配阶段;在垂直行业市场,墨芯也与生命科学领域部企业项目落地。
在未来一个阶段中,墨芯将围绕互联网、泛政府行业及垂直行业三大方向进行市场推广。在定价上,墨芯将整个算力服务器的TCO(总拥有成本)达到现有主流产品的1/2,甚至1/3。
王维此前在接受智东西专访时曾表示,稀疏化计算是一个通用的发展方向,它在技术层面上没有什么局限性。现在最大的挑战是关于稀疏化的计算生态。只有生态完备,这些产品才能够更快速地让各个行业的用户快速使用起来、熟悉起来。
因此,墨芯面对的下一步更大的挑战是如何未来去建立一个生态同盟的合作关系。
在算法生态方面,由于墨芯是从算法创新,与当下主流算法框架高度兼容,已通过众多SDK布局TensorFlow、PyTorch等主流框架接口,让客户在使用时好像“仍然是在用原来的平台一样”。
在硬件生态上,墨芯也与市面上主流服务器厂商展开合作,比如而在一个月前,墨芯刚刚与浪潮信息签订元脑战略合作协议,通过加入计算生态进行市场推广。而后,墨芯也将与其他服务器提供商以及运营商开放生态合作。
近日,墨芯已成为非营利性机器学习开放组织MLCommons会员,后者由谷歌、英伟达、英特尔、Facebook、浪潮等全球AI领军企业创建,每年会发布业内权威AI基准测试MLPerf。今年9月,将公布墨芯首批稀疏化计算卡S4和S30在MLPerf推理测试V2.1的性能测试结果,有望代表国产AI芯片达到一个新里程碑。
-
亿铸科技入选毕马威中国“芯科技”新锐企业50强2024-11-18 1600
-
芯翼信息科技荣登中国物联网企业投资价值50强!2024-03-13 4065
-
澜起科技成功入选福布斯“2023中国创新力企业50强”榜单2023-11-10 1996
-
苹芯科技入选“2023中国AI芯片新锐企业TOP10”榜单2023-09-19 2525
-
国科微入选2022中国新经济企业500强2023-04-12 1864
-
联创电子入选“2022中国VR50强企业”名单2022-11-29 1550
-
【AI简报20221014】2022中国AI芯片企业50强、大众与地平线成立合资企业2022-11-10 4633
-
传音控股连续入选2022中国大企业创新100强、中国战略性新兴产业领军企业100强2022-10-27 4760
-
智芯科登榜2022中国AI芯片企业50强2022-09-02 3322
-
芯光璀璨!2022中国AI芯片企业50强榜单揭晓2022-08-31 4198
-
亿智电子入选2022中国AI芯片企业50强榜单2022-08-29 2610
-
立讯精密成功入选2022中国创新力企业50强2022-08-16 2144
-
中微公司荣登福布斯中国“2022中国创新力企业50强”2022-08-14 2819
全部0条评论

快来发表一下你的评论吧 !
