

基于知识的对话生成任务
描述
研究动机
基于知识的对话生成任务(Knowledge-Grounded Dialogue Generation,KGD)是当前对话系统的研究热点,这个任务旨在基于对话历史和外部知识来生成的富含信息量的回复语句。目前的工作通常使用结构化知识图(KGs)或非结构化文本作为知识来源。这些外部的知识来源可以缓解传统生成模型产生的无意义和乏味的回复,比如“我不知道”和“是的”。
最近的一些工作使得有些学者认识到实体(Entity)之间的相关性在多轮对话中起着重要的作用,因此他们提出在知识图谱中挖掘实体之间有价值的结构信息,以预测下一个回复中可能出现的实体,并利用预测的实体进一步指导回复语句的生成。然而,这种方法也存在两个缺陷:
○ 一方面,entity-guided KGD方法将对话中的实体作为唯一的知识去指导模型对上下文的理解和回复的生成,而忽略了KG中实体之间的关系(relation)的重要性。然而,人类对话背后的规律性可以概括为一系列话题的转换,其中每个话题可能对应于一个关系边,而不是KG中的单个实体。
○ 另一方面,现有的KGD方法仅利用最后一个对话回合中的知识去预测后续回复中的知识,这种方式并不足以学习人类如何在多轮对话中如何转换话题。
下图是一个知识对话的示例。Dialogue Context(a)展示了一个对话上下文,两个用户从莱昂纳多的职业聊到了他的代表作泰坦尼克号,然后讨论了泰坦尼克号这部电影的类型和主演阵容,并将最后的焦点实体落在凯特温斯莱特上。KG(b)展示了在这个对话过程中所有涉及到的实体以及它们在KG中的三元组。由这两个信息源可以得到两种贯穿这段对话的语言逻辑:
a. 回合级实体过渡路径:莱昂纳多——>泰坦尼克号——>凯特温斯莱特
b. 对话级关系转换路径:职业——>代表作——>电影类型/主演
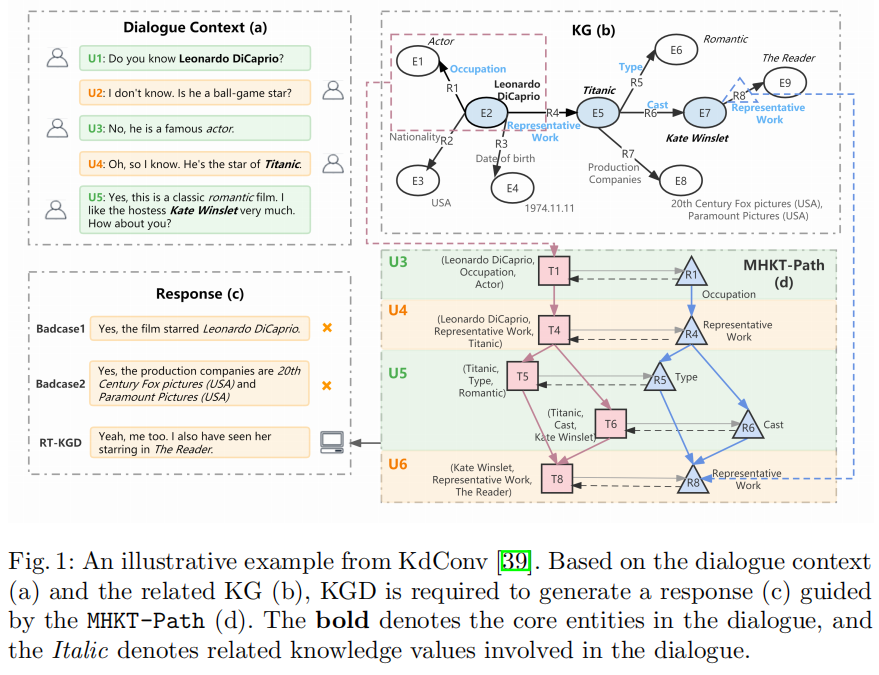
由此可见,如果不建模多轮知识,生成的回复可能是冗余且不连贯的,如Badcase1;如果只关注回合级的实体过渡路径,而忽略整个对话中话题的潜在转换路径时,模型生成的回复可能非常突兀,无法和对话上下文的语言逻辑顺畅地衔接起来,如Badcase2。
PART 02
贡 献
因此,本文提出了一种新的KGD模型:RT-KGD(Relation Transition aware Knowledge-Grounded Dialogue Generation),该模型通过将对话级的关系转换规律与回合级的实体语义信息相结合,来模拟多轮对话过程中的知识转换。具体来说,作者利用多轮对话上下文中包含的所有关系和实体,构建了MHKT-Path(Multi-turn Heterogeneous Knowledge Transition Path),它可以看作是外部 KG 的一个子图,同时又结合了多轮对话中关系和实体出现的顺序信息。基于所构建的 MHKT-Path,作者设计了一个知识预测模块,从外部KG中检索三元组作为后续回复中可能出现的知识,最后融合对话上下文和预测的三元组以生成回复语句。本文的主要贡献有以下三点:
• 本文是第一个将跨多轮对话中的关系转换引入 KGD 任务的工作,通过整合关系转换路径和实体语义信息来学习人类对话背后的规律性。
• RT-KGD 为每个对话都构建一个多轮异构知识转换路径(MHKT-Path),它将外部 KG 的结构信息和知识的顺序信息结合起来。基于MHKT-Path,模型可以从 KG 中检索适当的知识,以指导下一个回复的生成。
• 在多领域知识驱动的对话数据集KdConv上的实验结果表明,RT-KGD在自动评估和人工评估方面都优于基线模型。
PART 03
模 型
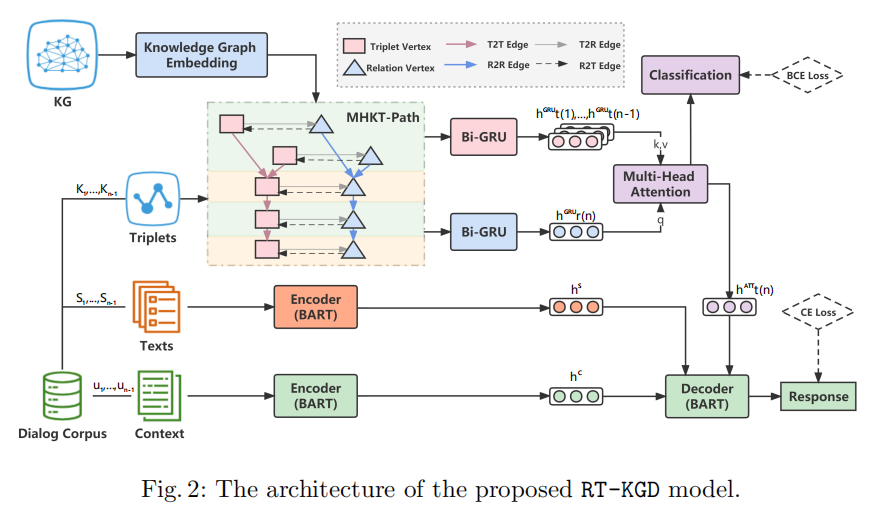
1.任务定义
给定一个对话上下文 C={u1,...,un-1}、其中每一条语句 ui 都对应一个三元组集合 Ki 和一个非结构化文本集合 Si 。模型的目标是利用对话上下文、结构化三元组和非结构化文本生成一句合适的回复语句 un 。
2.Multi-turn Heterogeneous Knowledge Transition Path(MHKT-Path)
作者为每个对话上下文都构建了一个多轮异构知识转移路径图,来将对话级的关系转换规律与回合级的实体语义信息结合起来。
MHKT-Path 有两类节点:
• 三元组节点 • 关系节点(关系节点是从对应三元组中抽取得到的) MHKT-Path 有四种边: • 连接三元组节点到三元组节点的边(边的方向按照三元组在对话上下文中出现的顺序决定) • 连接关系节点到关系节点的边(边的方向按照关系在对话上下文中出现的顺序决定,即与它们对应的三元组之间的边的方向相同) • 连接三元组节点到关系节点的边 • 连接关系节点到三元组节点的边
这样,两种粒度的知识信息就得到了充分交互和融合,共同促进模型对上下文知识和对话逻辑顺序的理解。
3. Knowledge Encoder
Knowledge Encoder用知识图谱表示学习模型和异构图神经网络将MHKT-Path中的节点转化为向量表示。
1. 初始化MHKT-Path中的所有节点。作者利用TransR得到KG中所有元素(实体和关系)的表示,这些表示融合了KG中的全局信息。因此,MHKT-Path中的节点表示就可以用这些元素的表示计算得到:对于关系节点,其向量表示就是该关系在KG中的表示;对于三元组节点,其向量表示由该三元组包含的头尾实体和关系的向量拼接而成。
2. HGT(Heterogeneous Graph Transformer)可利用MHKT-Path中的局部结构信息来更新节点的表示。
最后,结合上两步的结果得到节点的最终表示。
4. Knowledge Predictor
Knowledge Predictor用来预测下一句回复中可能出现的知识,此模块分为三部分:
1. 由于知识编码器只聚合局部邻域信息,作者进一步采用Bi-GRU来分别丰富关系节点和三元组节点的时序特征。具体来说,将此时间步中出现的所有关系节点和三元组节点的平均向量分别作为Bi-GRU的输入。
2. 基于前面的n-1轮(即n-1个时间步)的关系表示,通过Bi-GRU预测第n轮(t=n)的关系节点的表示:
与关系节点不同,作者先用Bi-GRU得到前n-1轮每轮三元组节点的表示:
然后利用多头注意力机制将对话级的第n轮关系节点的表示和回合级的前n-1轮三元组节点的表示结合起来,共同预测第n轮三元组节点的表示:
3. 因为一轮语句中可能包含多个知识,所以作者用多标签分类将得到的第n轮的三元组向量映射到一个标签向量上,其长度为KG中所有的三元组数量,并用二元交叉熵(BCE)损失函数来监督分类的效果。
5. Knowledge-Enhanced Encoder-Decoder
在Knowledge-Enhanced Encoder-Decoder中,BART用来给上下文语句和其中对应的非结构化描述文本S分别进行编码,Si代表第i轮语句中对应的非结构化描述文本。
在解码阶段,作者将上述步骤中得到的前n-1轮对话上下文C的表示、前n-1轮非结构化描述文本S的表示、和预测的第n轮三元组的表示拼接后输入BART的解码器中,生成第n轮富含信息量的回复语句:
模型最终的loss为知识分类标签的BCE损失函数和解码语句的交叉熵损失函数的加权和:
PART 04
实 验
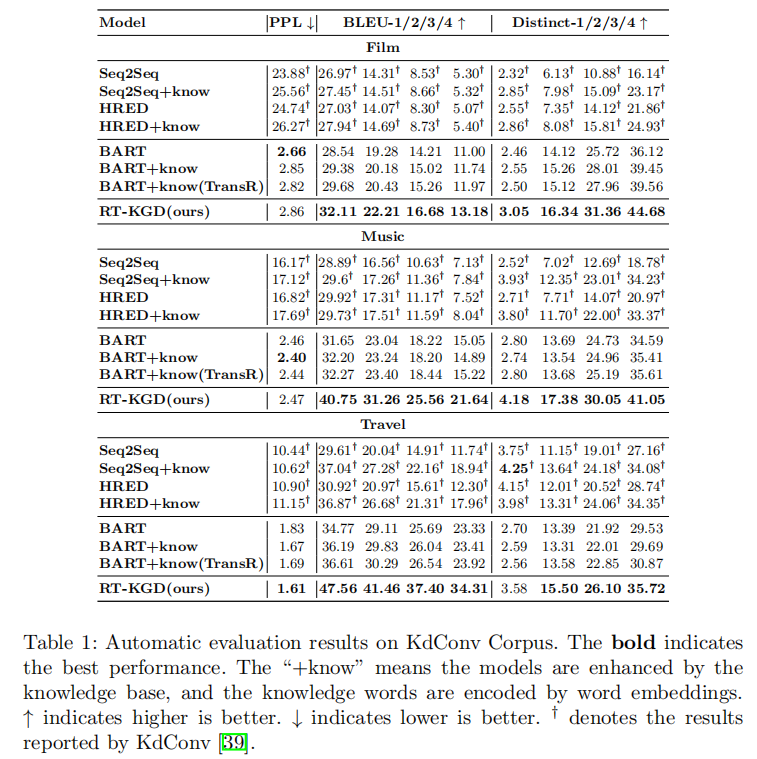
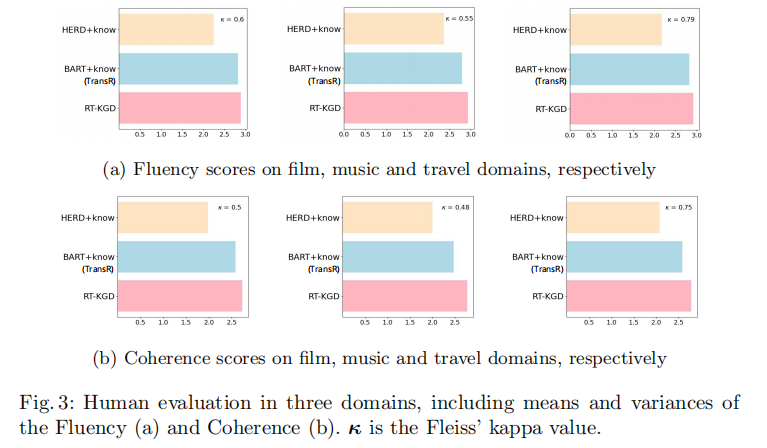
为了验证提出的模型,在数据集的选择时应该满足两个要求:(1)每轮语句都用相关的知识三元组进行标注;(2)在每个对话段中包含足够多轮次的语句。因此,KdConv是最佳的实验数据集。从实验结果来看,RT-KGD生成了更高质量的回复,利用了更合适的知识,并更接近人类的表达方式。
• 自动评估指标
• 人工评估指标
-
结合NLU在面向任务的对话系统中的具体应用进行介绍2019-03-21 6424
-
【安富莱原创】【STemWin教程】第39章 对话框基础知识2015-04-29 5634
-
第39章 对话框基础知识2016-10-16 4637
-
基于分层编码的深度增强学习对话生成2017-11-25 776
-
四大维度讲述了一个较为完整的智能任务型对话全景2019-02-04 8181
-
一种可转移的对话状态生成器2020-04-09 3152
-
对话系统最原始的实现方式 检索式对话2020-09-25 3251
-
华为公开 “人机对话”相关专利:可根据对话内容生成准确回复2021-02-27 4054
-
视觉问答与对话任务研究综述2021-04-08 1276
-
一种结合回复生成的对话意图预测模型2021-04-14 964
-
NLP中基于联合知识的任务导向型对话系统HyKnow2021-09-08 5144
-
受控文本生成模型的一般架构及故事生成任务等方面的具体应用2021-10-13 5025
-
NVIDIA NeMo 如何支持对话式 AI 任务的训练与推理?2023-05-11 2710
-
基于主观知识的任务型对话建模2023-10-31 1370
-
思必驰任务型对话算法通过国家备案2025-11-20 1220
全部0条评论

快来发表一下你的评论吧 !
