

在时空表示学习框架中使用 MLP 所面临的挑战
电子说
描述
美图影像研究院(MT Lab)与新加坡国立大学提出高效的 MLP(多层感知机模型)视频主干网络,用于解决极具挑战性的视频时空建模问题。该方法仅用简单的全连接层来处理视频数据,提高效率的同时有效学习了视频中细粒度的特征,进而提升了视频主干网络框架的精度。此外,将此网络适配到图像域(图像分类分割),也取得了具有竞争力的结果。

引言
由于 Vision Transformer (ViT)[1] 的开创性工作,基于注意力的架构在各种计算机视觉任务中显示出强大的能力,从图像域到视频域都取得了良好的效果。然而近期的研究表明,自注意力可能并不重要,因其可以被简单的多层感知器 (MLP) 取代,目前通过替代注意力框架的方法已经在图像域任务上开发了许多类似 MLP 的架构,且取得了可喜的成果。但在视频域该应用仍属空白,因此是否有可能设计一个通用的 MLP 视频域架构成为受到关注的新问题。
美图影像研究院(MT Lab)联合新加坡国立大学 Show Lab 提出了一种 MLP 视频主干网络,实现了在视频分类上的高效视频时空建模。该网络模型在空间上提出 MorphFC,在早期层关注局部细节,随着网络的加深,逐渐转变为对远程信息进行建模,从而克服了当前 CNN 和 MLP 模型只能进行局部或者全局建模的问题。在时间上,该网络模型引入了时间路径来捕获视频中的长期时间信息,将所有相同空间位置帧的像素进行连接,并合并为一个块。同时,每个块都会经过全连接层处理得到一个新的块。
基于空间和时间上的建模,研究者们广泛探索了建立视频主干的各种方法,最终按照串联的顺序依次对空间和时间信息进行建模,并以高效的时空表示学习框架表示。该网络模型首次提出不借助卷积和自注意力机制,仅用全连接层进行高效的视频时空建模的方法,对比之前的视频 CNN 和 Transformer 架构,该网络模型在提升精度的同时还降低了计算量。此外,将此网络适配到图像域(图像分类分割),也取得了具有竞争力的结果。该论文目前已被国际会议 ECCV 2022 接收。
背景介绍
由于 MLP 模型尚未在视频领域进行应用,研究者们首先分析了在时空表示学习框架中使用 MLP 所面临的挑战。
从空间角度上看,当前的 MLP 模型缺乏对语义细节的深刻理解。这主要是因为它们在空间中的所有令牌上全局操作 MLP,同时忽略了分层学习视觉表征(如下图 1 所示)。从时间角度上看,学习视频中帧的长期依赖关系目前基于视频的 Transformers 来实现,但计算时间成本巨大。因此,如何有效地利用连接层替换远程聚合的自注意力对节省计算时间至关重要。
图 1:特征可视化
为了应对这些挑战,研究者们提出了一种高效的 MLP 视频表示学习架构,即MorpMLP,它由 MorphFCs 和 MorphFCt 两个关键层组成。研究者们沿着长和宽的方向逐渐扩大了感受野,使得 MorphFC 可以有效地捕捉空间中的核心语义(如下图 2 所示)。
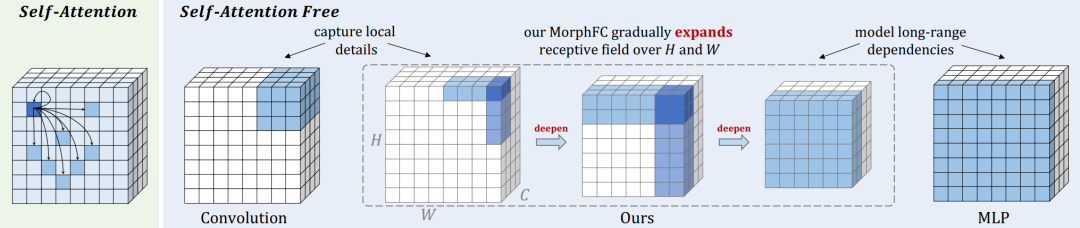
图 2:操作概览
这种渐进式的模式与现有的 MLP 模型设计相比,在空间建模方面带来了以下两个优势。
首先,它可以通过从小到大的空间区域操作全连接层,学习分层交互以发现判别性细节;
其次,这种从小到大的区域建模可以有效减少用于空间建模的全连接层的操作计算量。
此外,MorphFCt 可以自适应地捕获对帧的时序远程依赖。研究者们将所有帧中每个空间位置的特征连接到一个时间块中,通过这种方式,全连接层可以有效地处理每个时间块,并对长期时间依赖进行建模。最后,通过依次排列 MorphFC 和 MorphFCt 构建一个 MorphMLP 块,并将这些块堆叠到通用的 MorphMLP 主干网络中进行视频建模。
一方面,这种分层方式可以扩大 MorphFCs 和 MorphFCt 的协作能力,用以学习视频中复杂的时空交互;另一方面,这种多尺度和多维度的分解方法在准确性和效率之间取得了更好的平衡。MorphMLP 是首个为视频领域构建的高效 MLP 架构,与此前最先进的视频模型相比,该模型显著减少了计算量且精度更高。
MorphMLP 的时空建模模型
空间建模
如上所述,挖掘核心语义对于视频识别至关重要。典型的 CNN 和以前的 MLP-Like 架构只关注局部或全局信息建模,因此它们无法做到这一点。
为了应对这一挑战,研究者们提出了一种新颖的 MorphFC 层,它可以分层扩展全连接层的感受野,使其从小区域到大区域运行,按水平和垂直方向独立地处理每一帧。以水平方向处理为例(如下图 3 中蓝色块部分),给定某一帧,首先沿水平方向拆分该帧形成块,并将每个块沿通道维度分成多个组,以降低计算成本。
接下来,将每个组展平为一维向量,并应用全连接层来进行特征转换。特征转换完成后,重塑所有组回到该帧原来的维度,垂直方向处理方式相同(如图 3 中绿色块部分)。除了沿水平和垂直方向拆分,还应用了一个全连接层来单独处理每个空间位置,以保证组与组之间能够沿着通道维度进行通信。
最后,再将水平、垂直和通道特征相加。随着网络的加深,块长度分层增加,从而使得全连接层能够从小空间区域到大空间区域逐步发现更多核心语义。
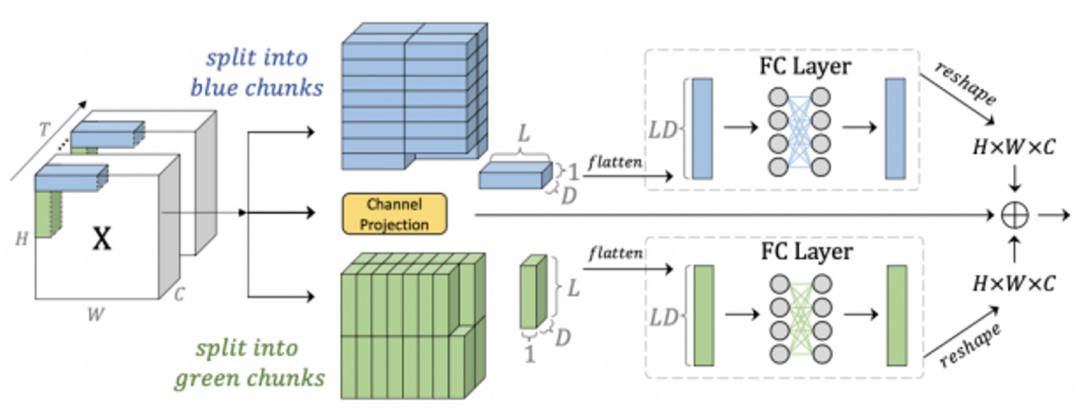
图 3:空间建模
时间建模
除了水平和垂直通路外,研究者们还引入了另一个时间通路,旨在使用简单的全连接层以低计算成本捕获长期时间信息。
具体而言,给定输入视频后,先沿通道维度分成几个组以降低计算成本,再将每个空间位置中所有帧的特征连接成一个块,接着应用全连接层来转换时间特征,最后将所有块重塑回原始维度。通过这种方式,全连接层可以简单地聚合块中沿时间维度的依赖关系,以对时间进行建模(如下图 4 中橙色块部分)。
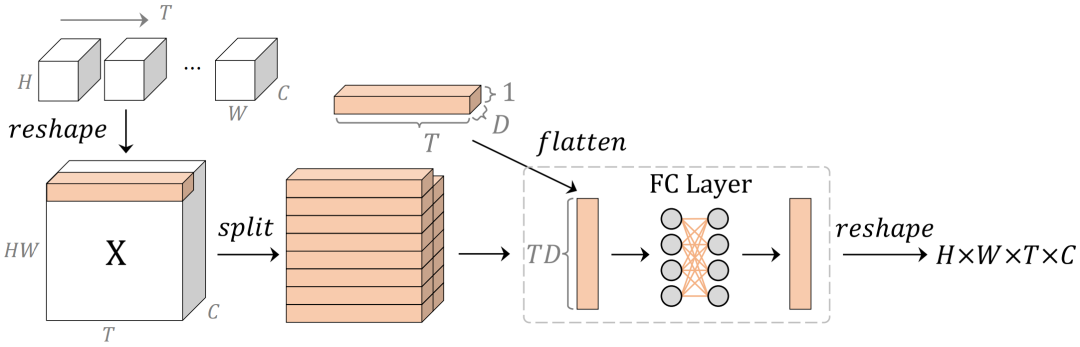
图 4:空间建模
时空建模
将时间和空间的全连接层串联在一起,以实现更稳定的时空优化收敛并降低计算复杂度,最终构建完成利用全连接层提取视频特征的主干网络,具体如下图 5 所示。在此基础上,只需简单地丢弃时间维度就可以完成到图像域的适配。

图 5:网络架构
结果
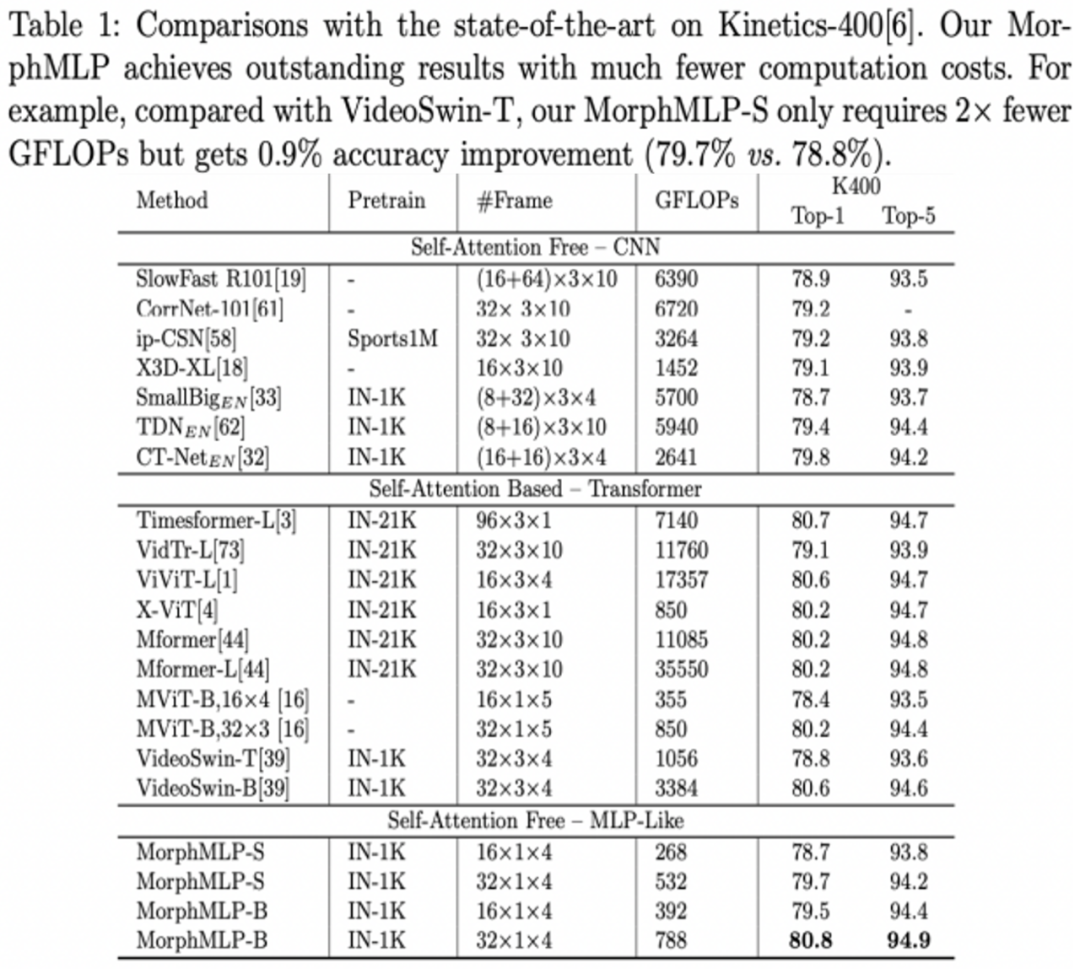
表 1:在 k400 数据集上的准确率和计算量表现
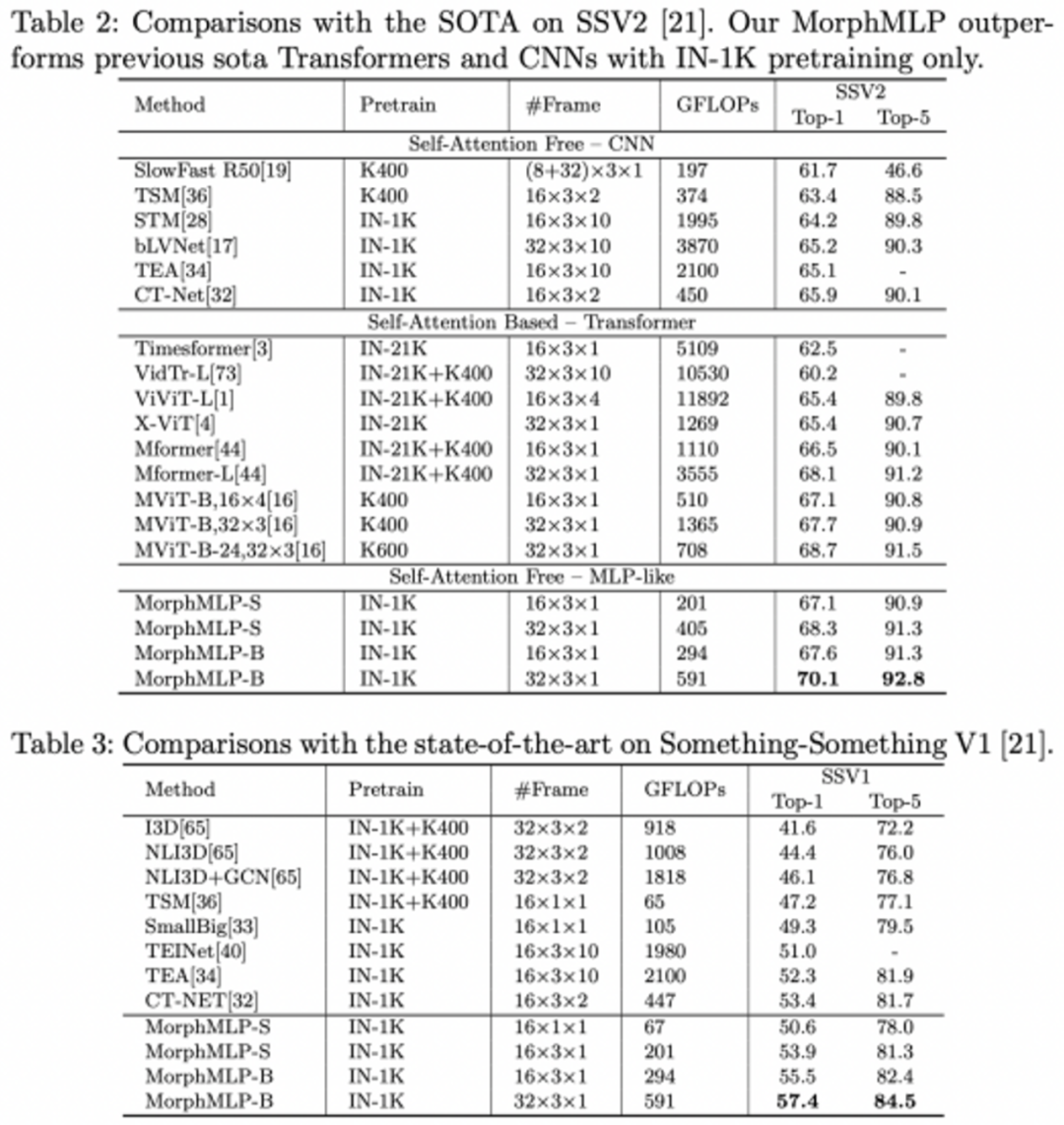
表 2:在 Something-Something 数据集上的准确率和计算量表现
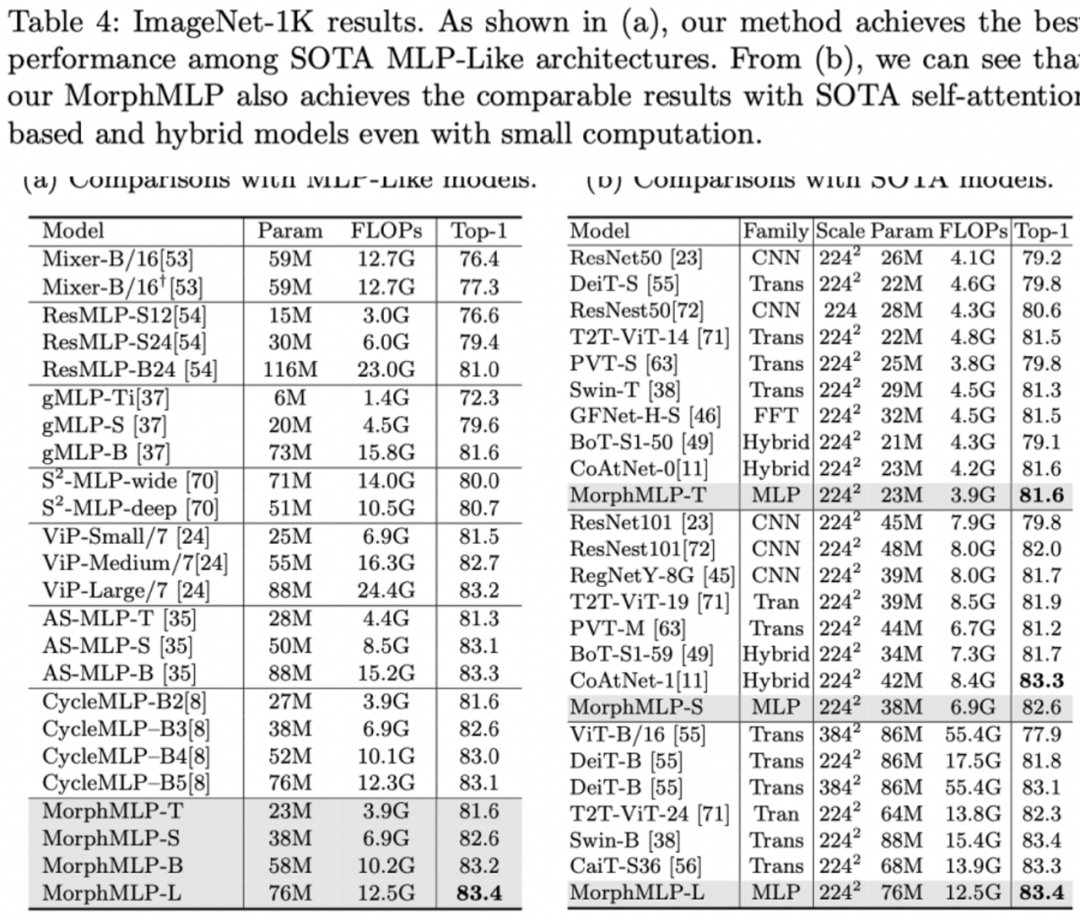
表 3:图像领域适配在 ImageNet 上的准确率和计算量表现
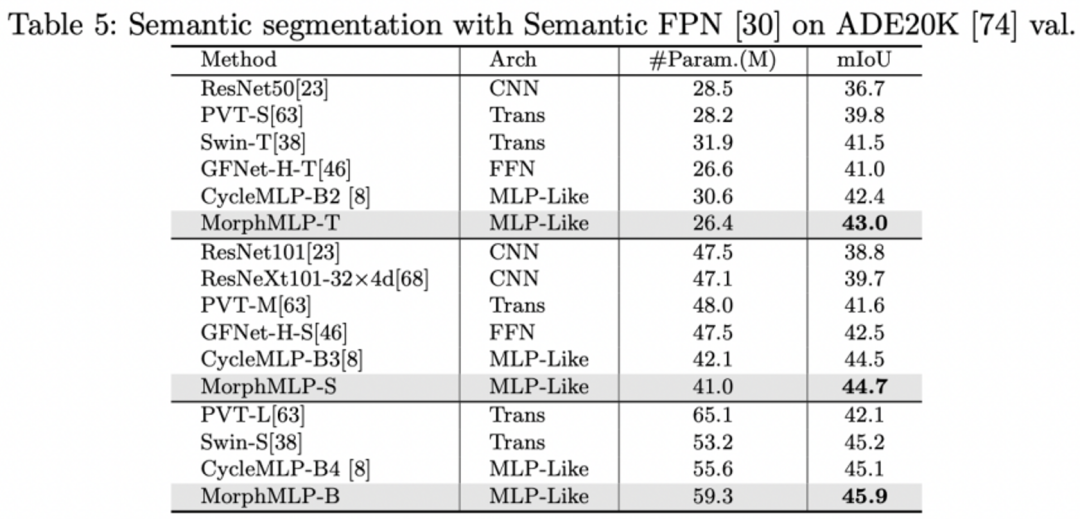
表 4:图像分割表现
总结
在本文中,研究者们提出了一种用于视频表示学习的无自注意力、类似 MLP 的主干网络 MorphMLP。该方法能够逐步发现核心语义并捕获长期时间信息,这也是第一个在视频领域应用 MLP 架构的主干网络。实验表明,这种无自注意力模型可以与基于自注意力的架构一样强大,甚至优于基于自注意力的架构。
-
移动电视射频技术面临什么挑战2019-06-03 2130
-
DVB-H接收器设计所面临的机遇和挑战讨论2019-07-08 2026
-
电力系统设计面临什么挑战?2019-08-20 2849
-
如何应对传感器信号调节所面临的挑战?2019-10-17 2253
-
精确测量阻抗所面临的挑战有哪些2021-01-27 2107
-
调试速度高达几个Gb每秒的连接时所面临的挑战2021-03-01 1255
-
电子系统设计所面临的挑战是什么2021-04-26 1948
-
LED在汽车领域应用面临哪些挑战?2021-05-11 1975
-
DVB-H接收器设计所面临的机遇和挑战是什么?2021-06-02 1501
-
5G终端天线研发所面临的主要挑战有哪些?如何去解决?2021-06-30 4082
-
复杂信号内部捕获所面临的常见挑战分析2013-01-21 12515
-
讨论在设计之初所面临的挑战及解决方案2018-06-25 3778
-
LiDAR系统所面临的五大挑战及如何应对2019-01-22 9313
-
一个通用的时空预测学习框架2023-06-19 3097
-
深度学习算法mlp介绍2023-08-17 6619
全部0条评论

快来发表一下你的评论吧 !
