

特斯拉Dojo超算指令集结构细节史上首次被公开
人工智能
描述
导读:在刚刚举办的硅谷芯片技术研讨会Hot Chips 34会议上,备受关注的特斯拉Dojo超算指令集结构细节史上首次被公开。 为了满足对人工智能和机器学习模型越来越大的需求, 特斯拉创建了自己的人工智能技术,来教特斯拉的汽车自动驾驶。 最近,特斯拉在Hot Chips 34会议上,披露了大量关于Dojo(道场)超级计算架构的细节。
本质上,Dojo是一个巨大的可组合的超级计算机,它由一个完全定制的架构构建,涵盖了计算、网络、输入/输出(I/O)芯片到指令集架构(ISA)、电源传输、包装和冷却。所有这些都是为了大规模地运行定制的、特定的机器学习训练算法。 Ganesh Venkataramanan是Tesla自动驾驶硬件高级总监,负责Dojo项目,以及AMD的CPU设计团队。Hot Chips 34会议上,他和众位芯片、系统和软件工程师首次公开了该机器的许多架构特性。
数据中心「三明治」 「 一般来说,我们制造芯片的过程,是把它们放在包装上,把包装放在印刷电路板上,然后进入系统。系统进入机架。」Venkataramanan说。 但是这个过程中存在一个问题:每次数据从芯片移动到封装上并离开封装时,都会产生延迟和带宽损失。 为了绕过这些限制,Venkataramanan和他的团队决定从头开始。

由此,Dojo的训练瓦片诞生了。 这是一个独立的计算集群,占地半立方英尺,在15千瓦的液冷封装中能够达到556TFLOPS的FP32性能。 每个瓦片都配备了11GB的SRAM,并在整个堆栈中使用定制的传输协议,通过9TB/s结构连接。 Venkataramanan说:「这块训练板代表了从计算机到存储器、到电源传输、到通信的无与伦比的集成度,不需要任何额外的开关。」 训练瓦片的核心是特斯拉的D1,这是一个500亿个晶体管芯片,基于台积电的7纳米工艺。特斯拉表示,每个D1能够在400W的TDP下实现22TFLOPS的FP32性能。

特斯拉然后用25个D1,把它们分到已知的好模具上,然后用台积电的晶圆上系统技术把它们包装起来,以极低的延迟和极高的带宽实现大量的计算集成。 然而,晶片上的系统设计和垂直堆叠架构,给电力输送带来了挑战。
据Venkataramanan说,目前大多数加速器将电源直接放在硅片旁边。他解释说,这种方法虽然行之有效,但这就意味着加速器的很大一部分区域必须专门用于这些组件,这对Dojo来说是不切实际的。于是,特斯拉选择直接通过芯片底部直接提供电源。 此外,特斯拉还开发了Dojo接口处理器(DIP),它是主机CPU和训练处理器之间的桥梁。 每个DIP都有32GB的HBM,最多可以将五个这样的卡以900GB/s的速度连接到一个训练瓦片上,以达到4.5TB/s的总量,每个瓦片共有160GB的HBM。

特斯拉的V1配置成对的这些瓦片——或150个D1模具——在阵列中支持四个主机CPU,每个主机CPU配备五个DIP卡,以实现声称的BF16或CFP8性能的exaflop。

软件 这样一个专门的计算架构,就需要一个专门的软件栈。然而,Venkataramanan和他的团队认识到,可编程性将决定Dojo的成败。
「当我们设计这些系统时,软件同行的易编程性是最重要的。研究人员不会等待你的软件人员为适应我们想要运行的新算法而写一个手写的内核。」
为了做到这一点,特斯拉放弃了使用内核的想法,围绕编译器设计了Dojo的架构。 「我们的做法是使用PiTorch。我们创建了一个中间层,它帮助我们并行化,以扩展其下面的硬件。所有东西下面都是编译过的代码。」为了创建可适应任何未来工作负载的软件堆栈,这是唯一的方法。 尽管强调了软件的灵活性,Venkataramanan指出,目前在他们的实验室中运行的平台,暂时仅限于特斯拉使用。 Dojo架构一览 看完了以上这些,让我们深入了解一下Dojo的架构。
特斯拉拥有用于机器学习的百亿亿次人工智能级系统。特斯拉有足够的资金规模来雇佣员工,并专门为其应用构建芯片和系统,就像特斯拉的车载系统一样。

特斯拉不仅在构建自己的AI芯片,还在构建超级计算机。

分布式系统分析 Dojo的每个节点都有自己的CPU、内存和通信接口。
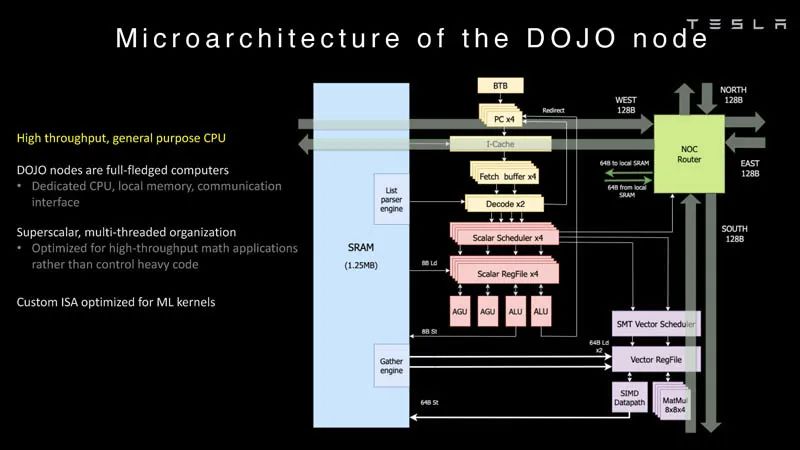
Dojo节点 这是Dojo处理器的处理管线。
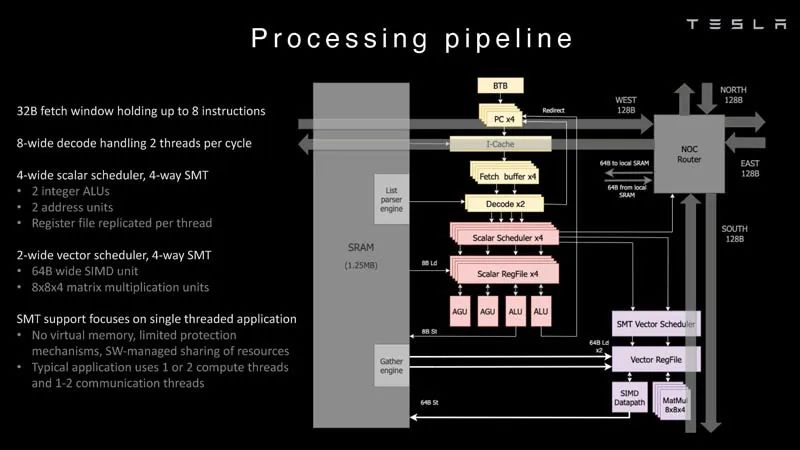
处理管道 每个节点有1.25MB的SRAM。在AI训练和推理芯片中,一种常见的技术是将内存与计算共置,以最大限度地减少数据传输,因为从功率和性能的角度来看,数据传输非常昂贵。
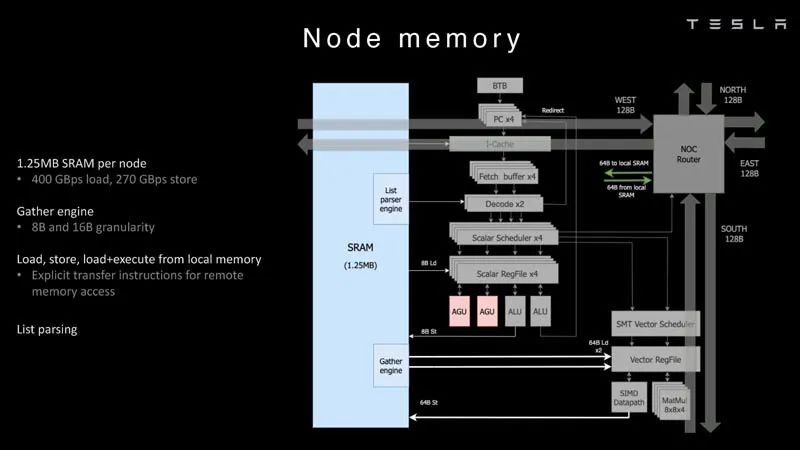
节点内存 然后每个节点都连接到一个2D网格。
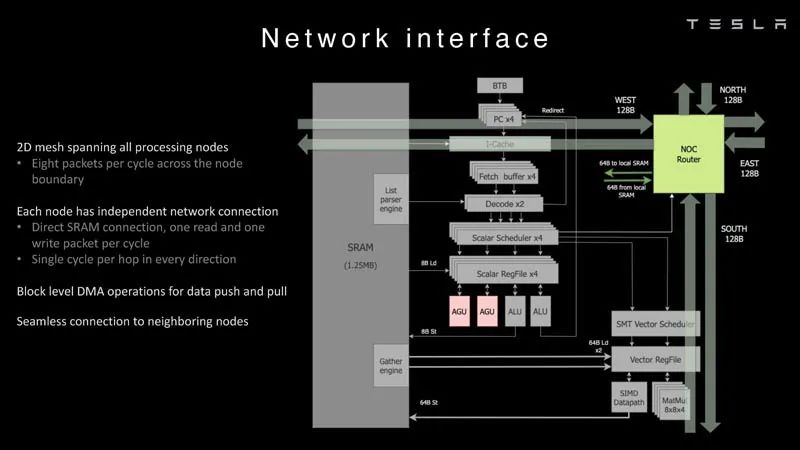
网络接口 这是数据路径概述。
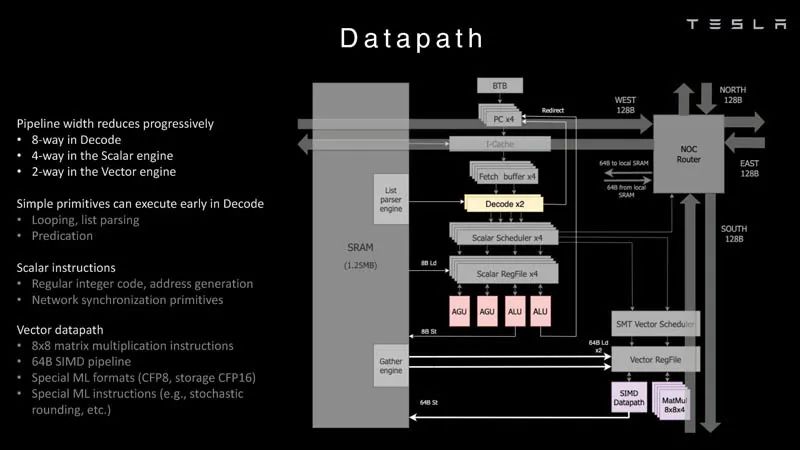
数据路径 下面是一个例子,说明芯片可以做的列表解析。

列表解析 这里有更多关于指令集的内容,属于特斯拉原创,而不是典型的Intel、Arm、NVIDIA或AMD CPU/GPU的指令集。
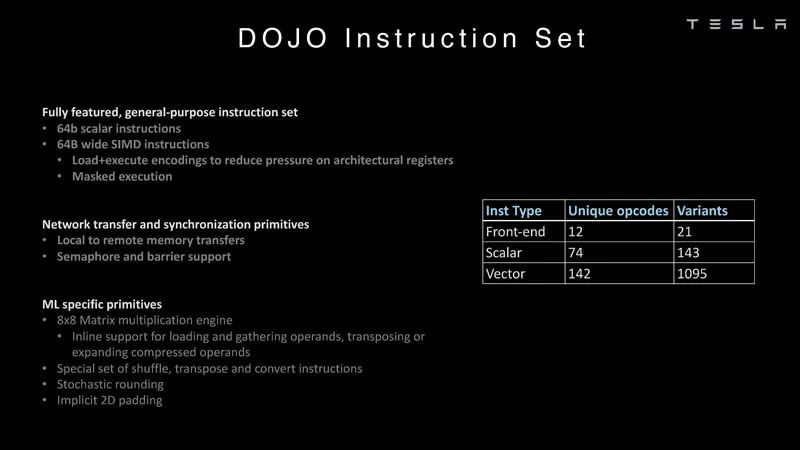
指令集 在人工智能中,算术格式很重要,尤其是芯片支持哪些格式。利用DOJO,特斯拉就可以研究常用格式,例如FP32、FP16和BFP16。这些是常见的行业格式。

算术格式 特斯拉也在研究可配置的FP8或CFP8。它有4/3和5/2的范围选项。这类似于 NVIDIA H100 Hopper配置的FP8。我们还看到Untether.AI Boqueria 1458 RISC-V核心AI加速器专注于不同的FP8类型。
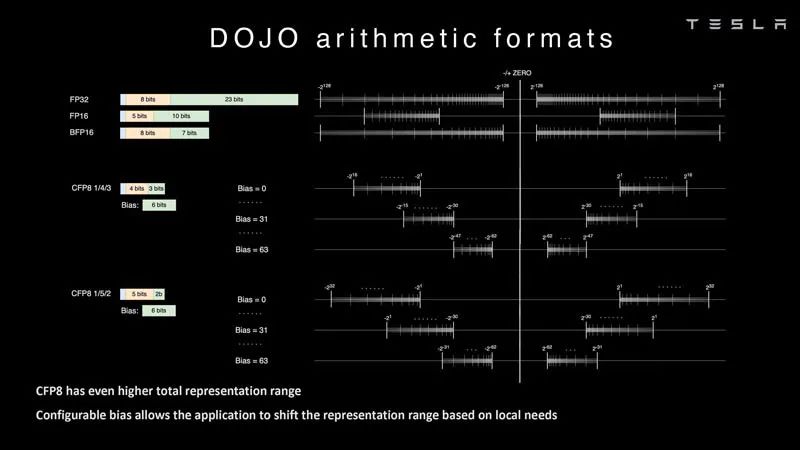
算术格式 2 Dojo还具有不同的CFP16格式,以实现更高的精度,并支持FP32、BFP16、CFP8和CFP16。

算术格式 3 然后将这些核心集成到制造的模具中。特斯拉的D1芯片由台积电以7nm工艺制造。每个芯片有354个Dojo处理节点和440MB的SRAM。
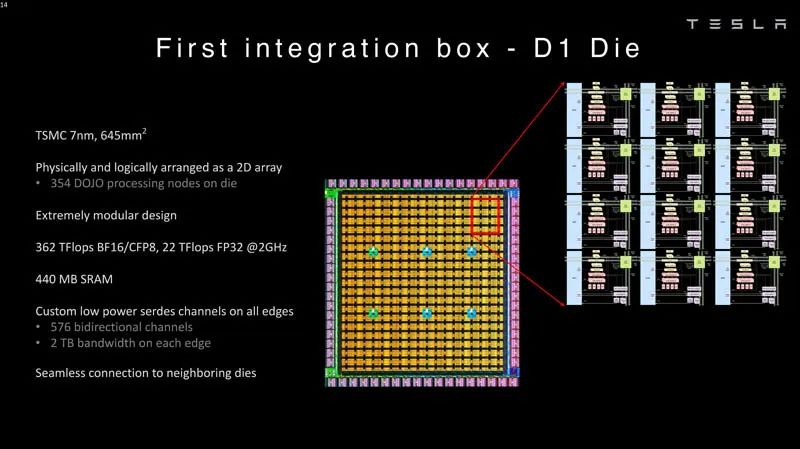
First Integration Box D1 模具 这些D1芯片被封装在一个道场训练瓦片上。D1芯片经过测试,然后被组装成一个5×5的瓦片。这些瓦片每个边缘有4.5TB/s的带宽。它们还具有每个模块15kW的功率传输包络,或者可以说,每个D1芯片去掉40个I/O裸片所使用的功率后,大约还有600W。 通过对比可以看出,如果一家公司不想设计这种东西,为什么像Lightmatter Passage会更有吸引力。

二次集成箱Dojo训练瓦片 Dojo的接口处理器位于2D网格的边缘。每个训练块有11GB的SRAM和160GB的共享DRAM。

Dojo系统拓扑 以下是连接处理节点的2D网格的带宽数据。

Dojo系统通信逻辑二维网格 每个DIP和主机系统提供32GB/s的链接。

Dojo系统通信 PCIe链接DIP和主机 特斯拉还具有用于更长路线的Z平面链接。在接下来的演讲中,特斯拉谈到了系统级的创新。

通信机制 这里是die和tiles的延迟边界,这就是为什么在Dojo中对它们进行不同处理的原因。需要Z平面链路的原因是,长路径很昂贵。
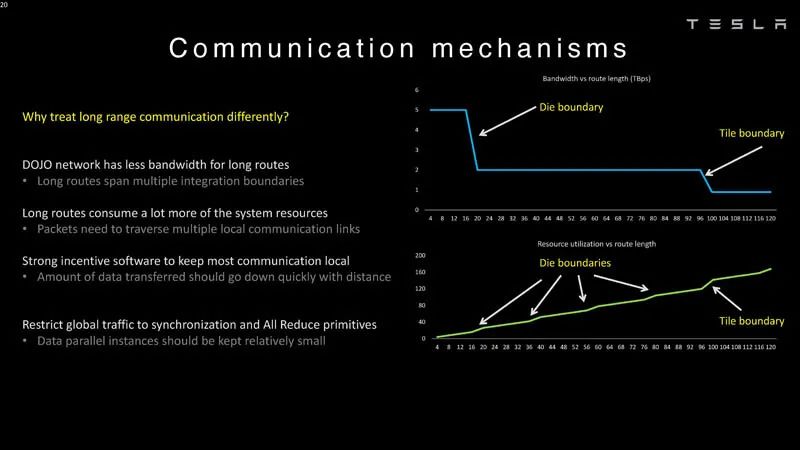
Dojo系统通信机制 任何处理节点都可以跨系统访问数据。每个节点都可以将数据推送或拉取到SRAM或DRAM。

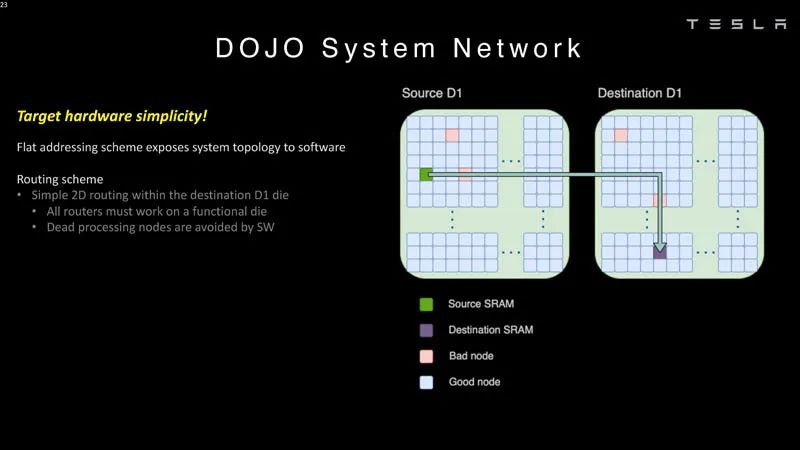
Dojo系统批量通信 Dojo使用平面寻址方案进行通信。

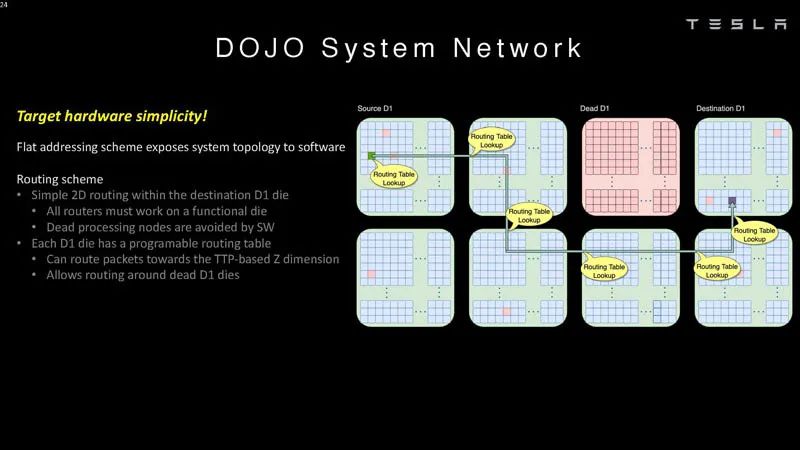
系统网络1 这些芯片可以在软件中绕过错误的处理节点。
系统网络2 这意味着软件必须了解系统拓扑。
系统网络3 Dojo不保证端到端的流量排序,因此需要在目的地对数据包进行计数。
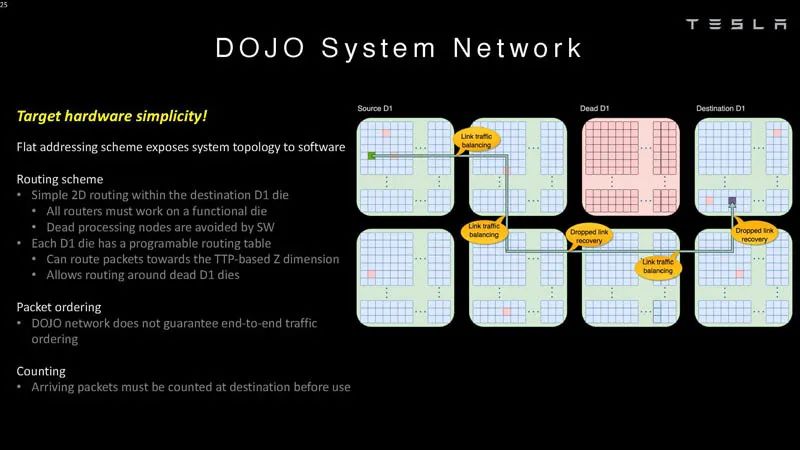
系统网络4 以下是数据包如何计入系统同步的一部分。
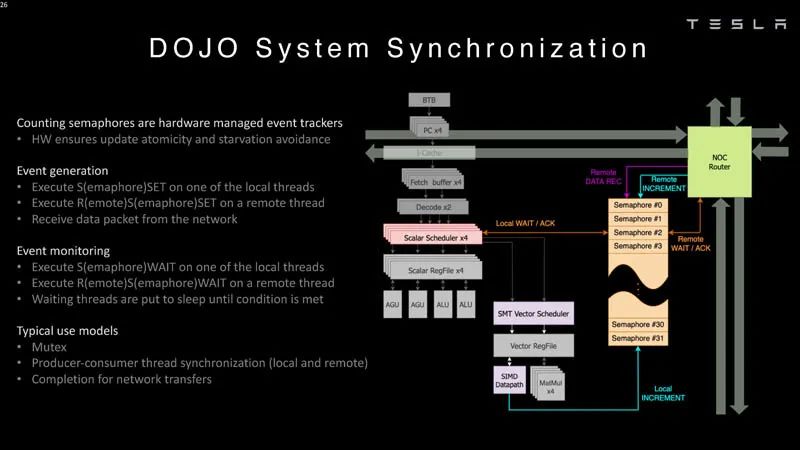
系统同步 编译器需要定义一个带有节点的树。
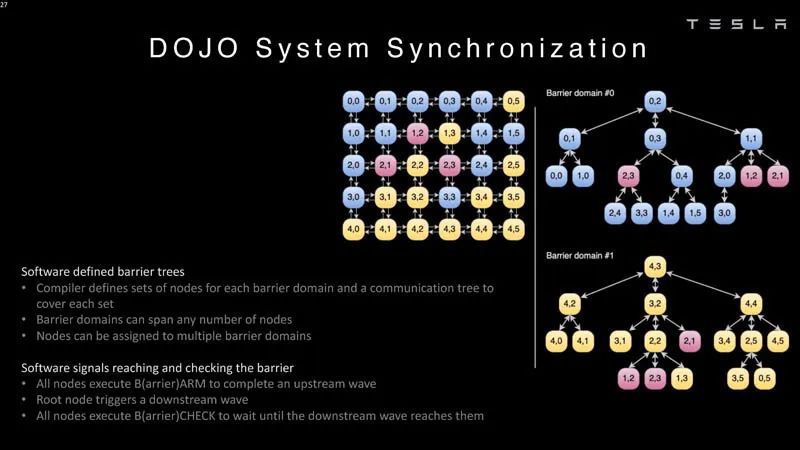
系统同步2 特斯拉表示,一个exa-pod拥有超过100万个CPU(或计算节点)。这些都是大型系统。

总结
特斯拉专门为大规模工作而建造了Dojo。通常,初创公司都希望为每个系统构建一个或几个芯片的AI芯片。显然,特斯拉专注于更大的规模。 在许多方面,特斯拉拥有一个巨大的人工智能训练场是合理的。更令人兴奋的是,它不仅使用商业上可用的系统,而且还在构建自己的芯片和系统。标量方面的一些ISA是借用RISC-V的,但矢量方面和很多架构特斯拉都是定制的,所以这需要大量的工作。
编辑:黄飞
-
特斯拉的自动驾驶标注员正在被DOJO超算取代2022-08-25 3204
-
超算负责人离职,特斯拉下一代自动驾驶何去何从?2024-01-02 2823
-
史上最全的51单片机指令集2016-09-27 8252
-
Hexagon DSP的指令集2018-09-19 3939
-
Microarchitecture指令集体系结构2021-12-14 1983
-
复杂指令集结构CISC和精简指令集结构RISC介绍2021-12-23 1596
-
道指历史上首次突破苹果首功2017-03-02 524
-
thumb指令集是什么_thumb指令集与arm指令集的区别2017-11-03 19555
-
bc95中文指令集公开版资源下载.pdf2018-04-19 1404
-
CPU结构与指令集的详细资料说明2020-07-13 1891
-
苹果实现史上首次单季营收突破1000亿美元的纪录2021-01-28 1846
-
吉利公布2025销量目标,特斯拉AI日发布Dojo超算+Tesla机器人.zip2023-01-13 387
-
内存涨疯!全球手机巨头三星却面临史上首次亏损2026-04-28 3586
全部0条评论

快来发表一下你的评论吧 !
