

几个经典的立体匹配算法的评价指标和数据集
电子说
描述
一. ADCensus背景介绍
到目前为止,我通过解读Stefano Mattoccia教授的经典讲义,介绍了立体匹配算法的全貌。然后介绍了几个经典的立体匹配算法的评价指标和数据集。下一步我将介绍经典的立体匹配算法,并展示它们在实际中的应用。 先来看看你现在读到哪里了吧:
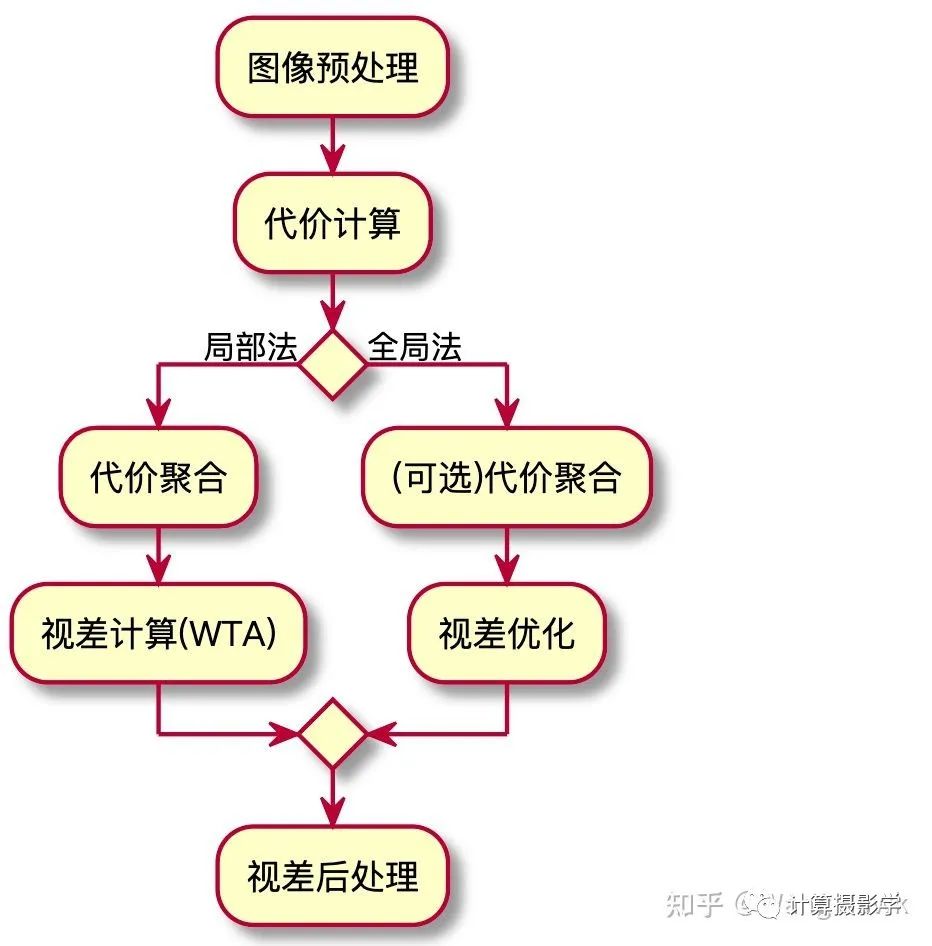
经典立体匹配算法局部法和全局法的总体流程,如下图所示:
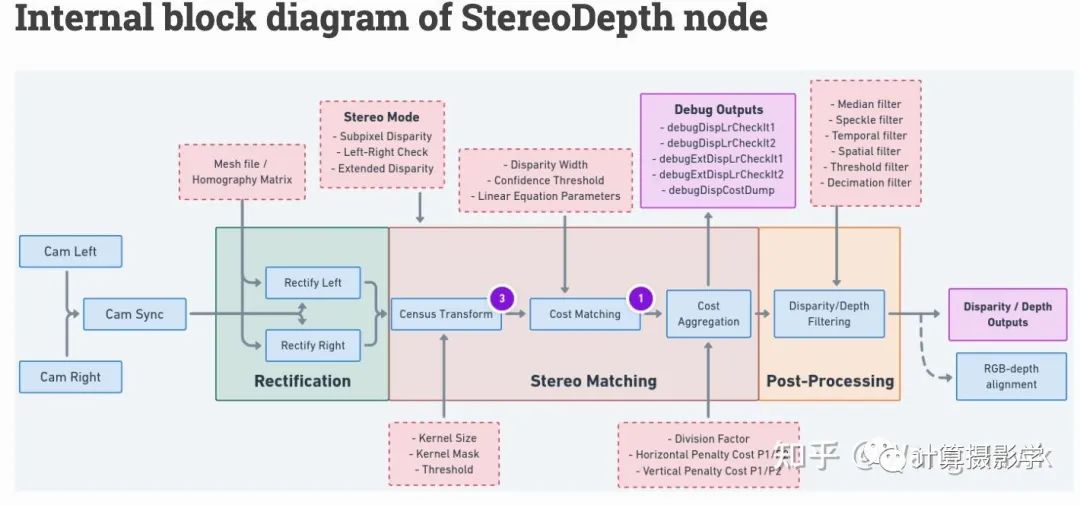
事实上,有一些算法的流程比较混合——比如今天我将介绍的一个经典立体匹配算法,它总体来说是局部法的流程,但其中也有少量模块在进行视差优化的过程。 这个方法很多人简称为ADCensus,是三星先进技术研究院中国实验室以及中科院自动化所的一群学者的成果,文章发表于2011年:

我用下图总结这篇文章的完整流程,我们可以利用Stefano Mattoccia教授给出的流程来对比理解ADCensus。
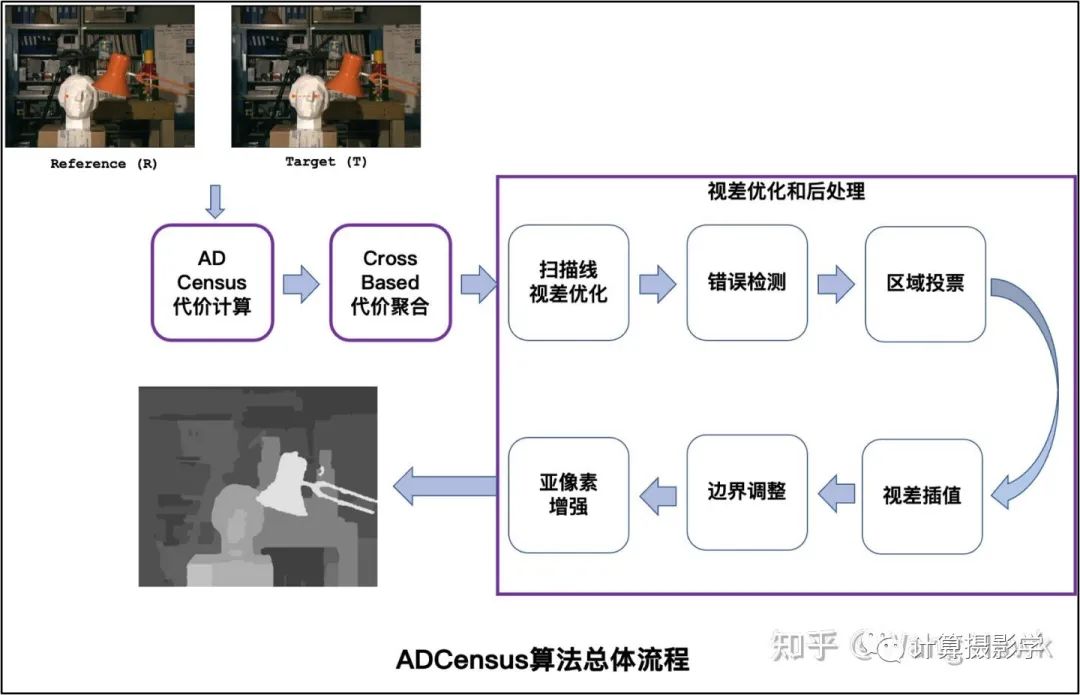
这个算法我个人非常喜欢,因为它的流程非常规范,而且易于理解。简直就像学习了Stefano Mattoccia教授的讲义后,将各个标准组件用当时各种优秀的算法实现并串联起来的作品,可以说上面图中每一个组件都有当时已经发表的论文做基础。但作者也并非简单的搞了一个缝合怪出来, 而是把许多组件都做了创造性的优化。比如把AD和Census两种特征融合在一起计算代价,并优化了基于十字架的代价聚合算法,同时组合使用了一系列的视差优化的后处理算法。而且,作者还在文章中描述了算法的CUDA实现,使得这个算法可以高效的在硬件上运行。 每一年计算机视觉领域都有大量的研究成果,但其中能够实用化的真的不多,而ADCensus就是其中之一。据我了解,很多硬件实现的立体匹配算法受到了ADCensus的启发。比如OAK相机,这是一个由OpenCV基金会发起的成功的众筹产品,可以实时计算深度图,完成一系列复杂的功能。
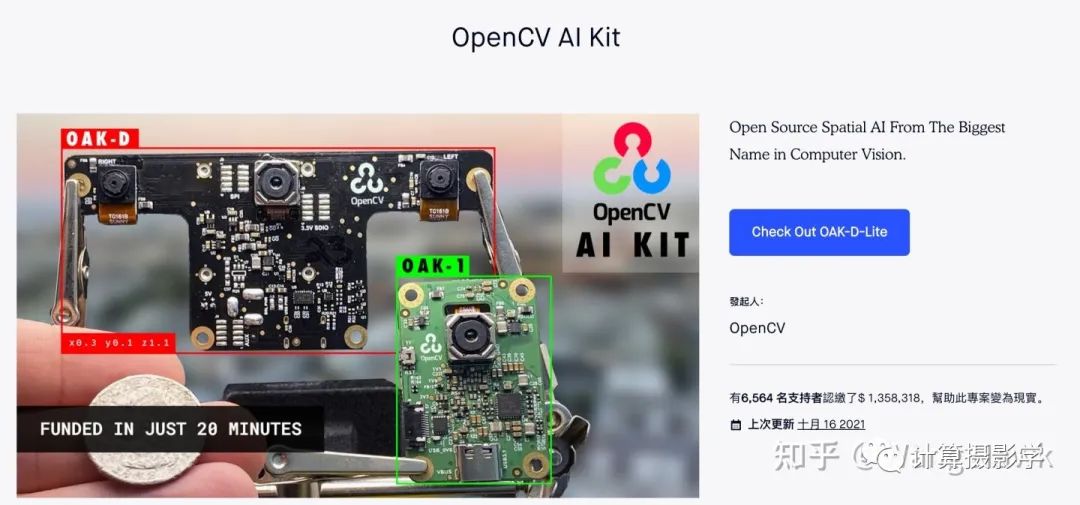
它们推出了多款产品,我手上有下面这一款:

这个相机内部集成的立体匹配算法,就是基于ADCensus的思想实现的,我们可以在这里查到相应的介绍,如下图所示,当然这里为了效率在原始的算法上做了必要的裁剪和调整。
另外,Intel公司的著名产品Intel Realsense D400后的系列RGBD相机也借鉴了本文作者提出的立体匹配算法,特别是其中代价计算部分,在Census特征基础上叠加AD这样的特征,就是从ADCensus方法中借鉴的方法。 如果你查看2017年CVPR的下面这篇关于Intel RealSense的论文,你会看到对此的清晰描述

总之,一群中国学者,在2011年左右搞出了一种非常实用化的立体匹配算法,在很多领域都得到了应用,非常值得钦佩!
二. 效果展示
我在github上找到了一个比较原汁原味的算法实现:https://github.com/DLuensch/StereoVision-ADCensus,我们来看看效果吧。 先来看两对MiddleBurry中的经典图像,左上和左下是校正后的图像,右边是算法默认参数生成的视差图,看起来还不错:

再看看这把椅子吧,看起来对这种复杂的场景稍微差点意思,需要仔细的调优参数才行(我几乎用的是默认参数):

来试试摩托车,尽管还遗留了一些空洞,整个画面的深度图还是被正确恢复出来了,总的来说,效果还是令人满意的

再看看在MPI Sintel数据集上的效果,这个数据集的具体介绍请见76. 三维重建11-立体匹配7,解析合成数据集和工具,可以看到前景效果总体来说不错,背景似乎都为0,看起来是因为太远了的原因?

然后我们请出我的御用模特Sunny妹来试试,看起来默认参数在这种场景下有很多错误,需要仔细调参才能得到更好的结果。我们待会会仔细分析下ADCensu算法的各个步骤和相关参数:

三. 原理简介
3.1 代价计算
立体匹配算法总体理解中说过代价计算的过程类似于连连看的过程:
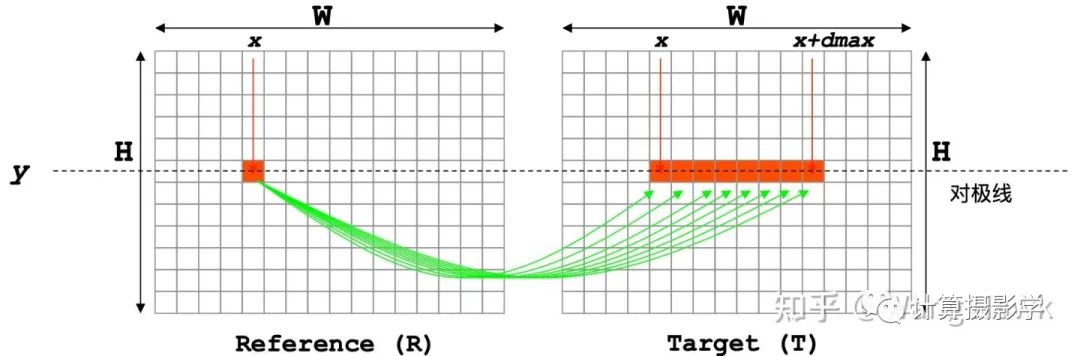
最简单的代价就是左右图中相应像素的亮度绝对差,这种代价被称为AD:
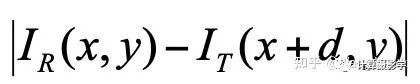
然而,这种代价在图像中的平坦区域(亮度值都差不多)很显然会得到错误的结果。此时显然应该使用别的特征来计算代价。Cencus就是一种很好的特征,它衡量了局部区域中像素亮度的排序,这是一种结构信息。这就使得它很好的避免了左右图像素亮度差异、噪声、重复纹理等因素带来的错误。 不过,仅使用Census特征的话,在图像中重复结构的区域,也会得到错误的结果。这时候颜色或亮度特征则可以加以辅助。所以ADCensus的作者创造了一种很不错的融合亮度差异和结构差异的方法,如下面公式所述。这里前一部分是基于Census的代价,后一部分是AD代价,所以这个算法才被很多人称为ADCensus:
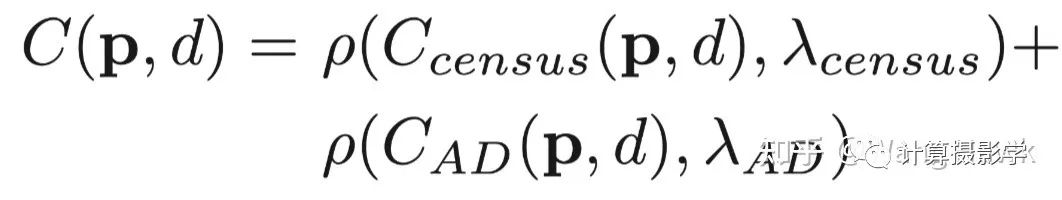
这里面,为了让两部分代价归一化到[0,1]之间,作者采用了下面这个归一化函数,它能很方便的将输入的原始代价转换为[0,1]之间的值,而这里的λ则用于设置代价的权重:
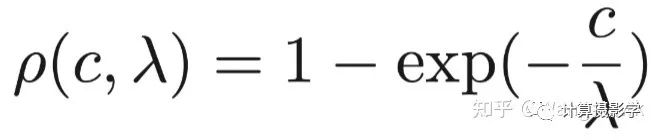
我们通过作者给出的下图可以很容易的看到混合两种代价带来的好处:

这时候,直接利用AD-Census计算固定窗口的代价,然后用WTA得到视差图,如下图所示。我们可以看到这里有大量的噪声和空洞区域。这是很容易理解的,所以才需要下一节所述的代价聚合过程:

3.2 代价聚合
ADCensus所用的代价聚合方法很有意思。在我的文章71. 三维重建6-立体匹配2,立体匹配中的代价聚合中,我提到了代价聚合的假设:
空间上接近的像素,其视差值也是接近的,于是代价值也是接近的
像素值接近的像素,其视差值也是接近的,于是代价值也是接近的
左右两张图的相邻像素,在关键信息上具有局部相似性
我们还看到了各种各样的聚合方式,有一类方式就是用可变形状的支持窗来进行聚合的——ADCensus的方法就属于这种。当要确定某个像素点p的支持窗时,它是通过寻找上下左右四个"臂",在这四个臂的包裹下构成了其支持窗。确切说,首先找到p的上下臂,也就是在空间和像素值两个维度上都尽可能接近p的两端像素。这样就构成了一个包含在p内的垂直的像素线段。在这条线段上的任何一个点q,我们都确定其左右臂,得到水平的远端像素。这样,所有q点的左右臂的远端像素就形成了一个包络,其中就是p点的支持窗。
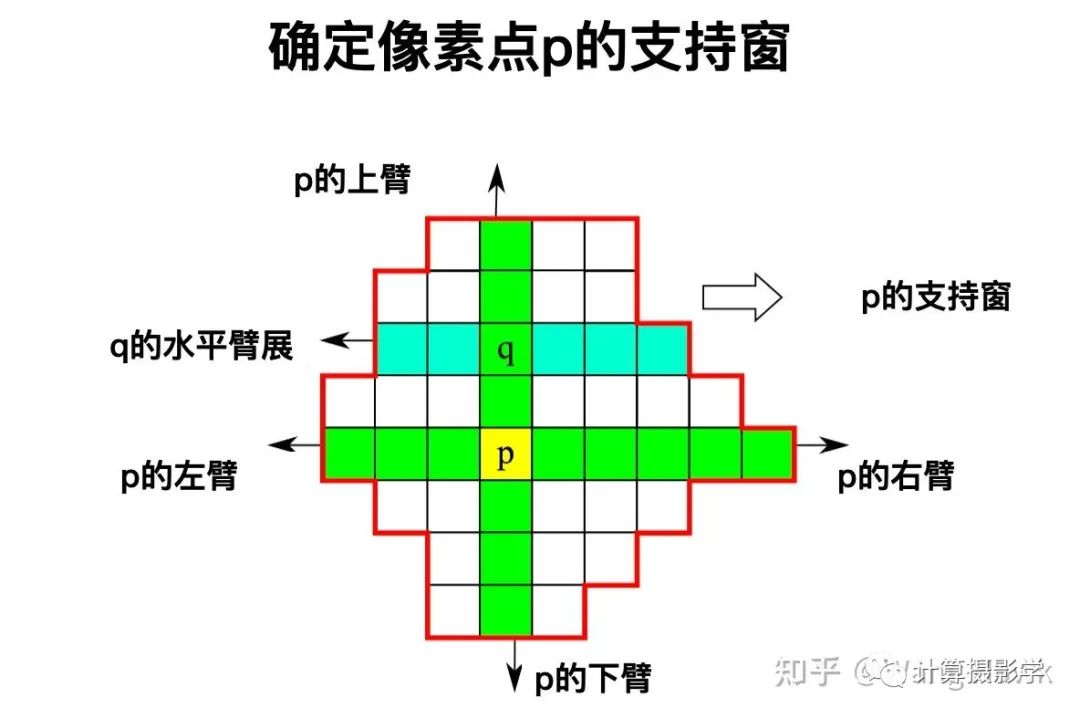
有了支持窗后,就比较容易聚合了,先在水平方向聚合,将水平方向的代价值加到一起。然后在垂直方向聚合,得到总的代价:
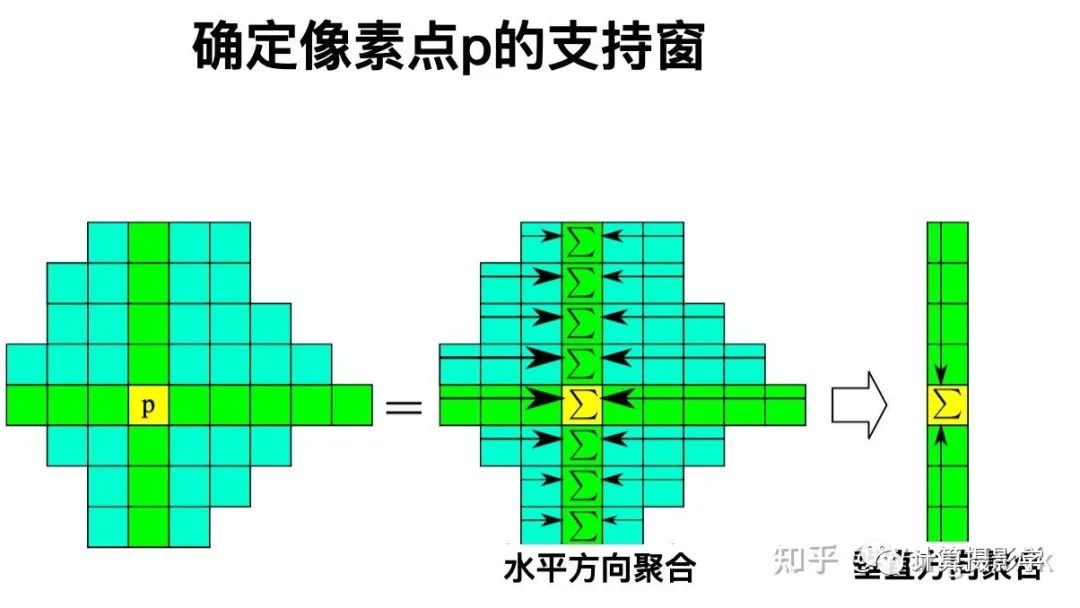
事实上,ADCensus中为了让结果更好,进行了4次交替方向的聚合。即先水平再垂直,这是第1次。第二次相反,先垂直,再水平。然后再进行2次交替的聚合。最终四次的代价整合到一起,成为最后聚合后的代价值。 那么,如何得到上面所说的p点的四个臂呢?这似乎是得到支持窗的关键。我们以获得p的左臂为例来说明:

所以很显然,这里面的几个参数L1, L2等参数 τ2 都很重要。总之,通过这一步代价聚合后,我们能够得到更加平滑的视差图,如下图所示:

3.3 扫描线优化
在文章72. 三维重建7-立体匹配3,立体匹配算法中的视差优化中,我们看到了一种扫描线优化的方法。ADCensus也采用了这种方法,通过聚合后的代价优化得到视差图。在这篇文章中我已经详细阐述了方法,这里只说说不同之处。在原始的扫描线优化方法中,一共是8个方向。而ADCensus为了提高计算速度,只采用了其中的0、1、2、3这几个水平和垂直的扫描线:
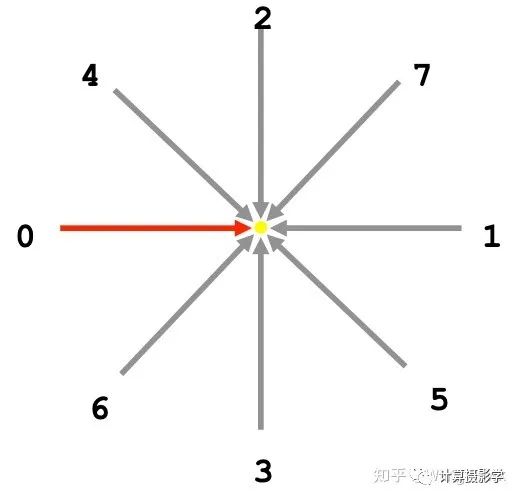
通过这一步,能得到更加准确的视差图,如下图所示。相比上面代价聚合后的结果,这里明显噪声小了很多:

3.4 视差后处理
接下来就是视差后处理了,这里是我觉得这个算法的可圈可点之处。作者几乎把我在73. 三维重建8-立体匹配4,利用视差后处理完善结果中提到的视差后处理方法都用上了,形成了一个复杂的管线,如下图所示。我会在后面对这种方式进行评价,但让我们先跟着作者的脉络往下学习吧。

3.4.1 错误检测和区分
首先需要通过左右一致性检查判断哪些像素是错误的:
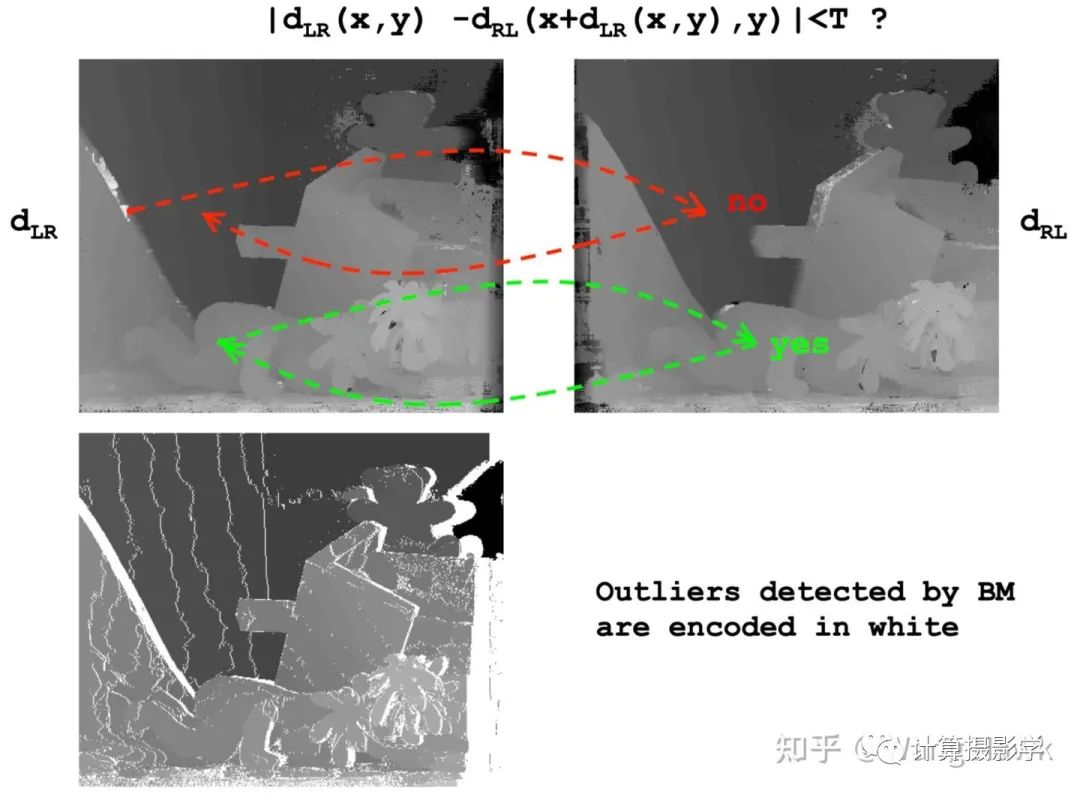
然后,通过一个简单的法则来区分到底是因为遮挡导致的错误,还是因为错误匹配导致的错误。遮挡像素无论调整d为多少,都无法通过左右一致性检测。而错误匹配则可以通过调整d,得到满足左右一致性检查的新视差值。
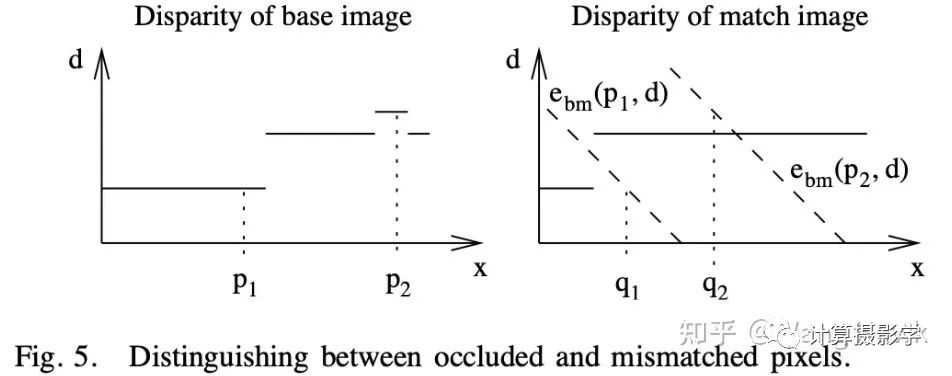

接下来,就可以分别对遮挡和错误匹配进行处理了。
3.4.2 区域投票
首先进行区域投票。在错误像素点p的支持窗内,对所有正确计算视差的像素(即通过了左右一致性检测)的视差值建立一个直方图。如果这个支持窗中稳定视差值足够多,并且直方图中占比最大的视差值的占比大于某个阈值,我们就把p点的视差值更新为最大占比的视差值:
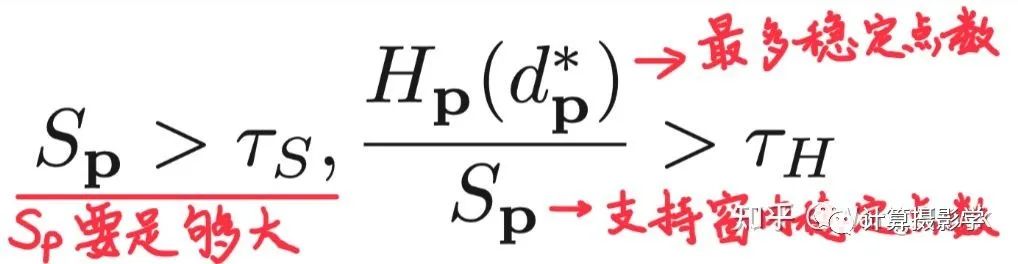
这里面,Sp代表支持窗中正确视差值的个数,Hp(d*p)代表直方图中占比最大的视差值的数量

3.4.3 分情况插值
前面我们区分了遮挡像素和错误匹配的像素,现在分情况进行插值。
首先对于错误像素,我们寻找16个方向上的最相似的正确匹配的像素。
接下来,如果当前像素在3.4.1节中被划分为了遮挡像素,那么就从这些正确像素中挑选最小的视差,用于填充当前像素的视差值,也就是说假设遮挡像素属于背景。
而如果当前像素是错误匹配的像素,那么就从这些正确点中挑选与当前像素颜色维度最相似的那一个,用其视差填充当前像素。
现在再来看看结果,很明显大量的错误像素被成功插值了。不过也可以看到,部分遮挡像素还是未填充视差值,这是因为在其16个方向都找不到满足条件的正确像素,这里主要是因为用1个参数限制了在一个方向上的最大搜索像素。如果增加这个参数的值,应该可以使得更多的像素得到填充。

3.4.4 修正边缘处的视差值
考虑到物体边缘的视差值不稳定,容易出错,因此作者还加入了一个步骤,对边缘处的视差值进行微调。具体来说,先检测到所有的边缘,接着对边缘上的像素p,我们判断其在边缘两侧的两个相邻像素p1或p2的代价是否小于p点的代价。如果确实如此,那么就用p1和p2中代价最小的那个像素的视差值来替换p点的视差值。 不过对于当前这对图像,似乎边缘调整带来的变化很小,肉眼几乎分不出来。当然,这是可以理解的,因为这只是“微调”

3.4.5 亚像素增强和滤波
调整完边缘后,作者采用了我在文章73. 三维重建8-立体匹配4,利用视差后处理完善结果中提到的亚像素增强,将整数型的视差值插值为了浮点数型的视差值
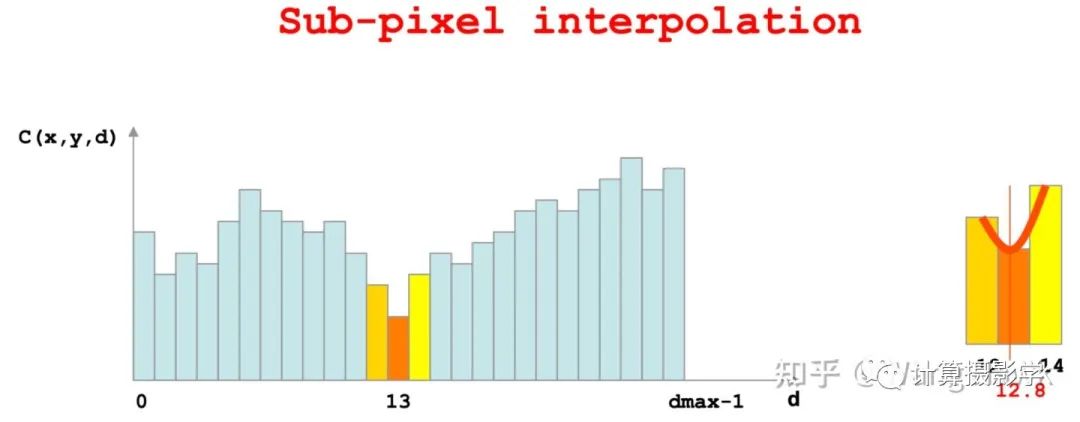
然后,对最后的视差图做了1个3x3的中值滤波,去除微小的噪声,这就得到了最终的视差图:

我把整个过程做成一个视频,可以看得更清楚些:
四. 算法讨论
正如我在文章开篇所说,我挺喜欢ADCensus这个算法的。因为它是由一个又一个非常容易理解的子部件组合而成的。这种结构也使得实现起来很容易,而且还可以根据工程需要删除或者替换其中的子部件。 比如,在文章开篇我们看到的OAK Camera的流程,通过官方的流程图可以看出跟原版ADCensus很相似,用了Census特征,扫描线优化,左右一致性检测后的插值,还增加了更多的滤波器。似乎裁减掉了区域投票、边缘调整等步骤:
从效果上看,OAK Camera仅通过单通道的双目图像,就已经能实时得到不错的结果,这进一步证明了类ADCensus算法的有效性:


而且,作者还专门阐释了在硬件上优化实现的方案,包括代价计算,代价聚合,扫描线优化等在内的步骤都可以用硬件来并行计算。在作者的论文中,通过硬件加速,算法执行速度提升了最高140倍!OAK Camera应该也是借鉴了其中的思想,所以能实时计算得到视差图。 然而,硬币总有两面,由多个子部件来构成一个完整的算法管线,也会带来新的问题。由于每个部件都有自己的参数,这就导致要将算法调整到最佳状态非常困难,因为参数数量太多了,而且各个部件之间有强相关关系,调整前一个步骤的参数,可能会影响到后一个步骤,这就使得调整参数更加复杂。而且,在不同的数据集上,参数的值显然不相同,所以导致这个算法的泛化性很成问题。 前面的开源实现 https://github.com/DLuensch/StereoVision-ADCensus, 里面,就定义了众多参数:
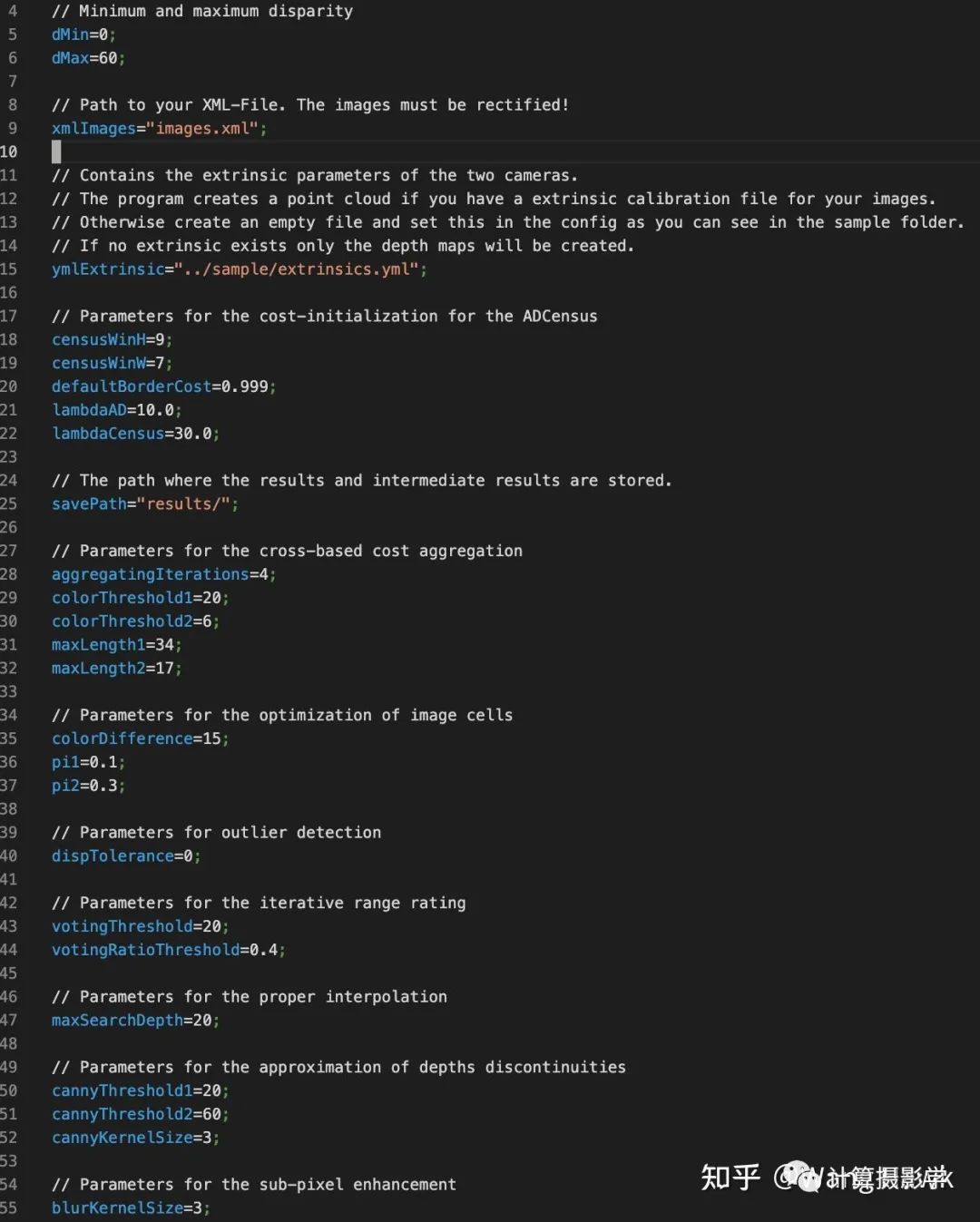
前面我们Sunny妹的图片,采用MiddleBurry数据集上调出的默认参数时就存在很多区域的错误。很显然,此时应该在这种场景下对参数进行精调才行。
比如在OAK-Camera上调整参数后,可以得到这个结果,明显的错误像素少了许多:

用多个子部件组成算法管线,还存在性能优化的问题。因为你不得不优化每一个部件的性能,才能得到一个高性能的算法——这对立体匹配通常非常重要。
五. 总结
今天,我为你介绍了一个经典的立体匹配算法ADCensus,其流程非常规整。它很容易理解,很容易实现,并且被许多知名的硬件设备所借鉴,比如OpenCV官方推出的OAK Camera,以及Intel Realsense。 它的作者是一群中国学者,嗯,好感度++ 它遵循的范式是用一堆容易理解的子模块构成整个算法,似乎咱普通人也能想得到这种思想:
ADCensus算法也有自己的缺点:参数众多、难以调整、泛化性不够高。模块众多,优化复杂,很吃经验。 那么,有没有更好的方式呢?这也是我后面的文章中会讲述的,让我们拭目以待吧。
六. 参考资料
1.X. Mei etc.,On building an accurate stereo matching system on graphics hardware2.OAK-Camera:https://store.opencv.ai/products/oak-d3.Leonid Keselman etc. Intel RealSense Stereoscopic Depth Cameras4.开源实现:https://github.com/DLuensch/StereoVision-ADCensus
审核编辑 :李倩
-
CREStereo立体匹配算法总结2023-05-16 3863
-
融合边缘特征的立体匹配算法Edge-Gray2021-04-29 1275
-
一种基于PatchMatch的半全局双目立体匹配算法2021-04-20 975
-
双目立体计算机视觉的立体匹配研究综述2021-04-12 1386
-
如何使用跨尺度代价聚合实现改进立体匹配算法2021-02-02 1215
-
立体匹配SAD算法原理2019-06-05 2874
-
视觉显著性的快速区域立体匹配算法2017-12-28 1012
-
基于mean-shift全局立体匹配方法2017-11-20 1083
-
超像素分割的快速立体匹配2017-11-15 1339
-
基于颜色调整的立体匹配改进算法2017-11-02 730
-
基于扩展双权重聚合的实时立体匹配方法2017-10-31 1081
-
双目视觉立体匹配算法研究2010-08-14 1469
-
基于蚁群优化算法的立体匹配2009-06-26 1052
-
基于外极线分区的动态立体匹配算法2009-04-11 739
全部0条评论

快来发表一下你的评论吧 !
