

Vision Transformers比基于CNN的模型更具有潜力
描述
Vision Transformer (ViT)自发布以来获得了巨大的人气,并显示出了比基于CNN的模型(如ResNet)更大的潜力。但是为什么Vision Transformer比CNN的模型更好呢?最近发表的一篇文章“Do Vision Transformers See Like Convolutional Neural Networks?”指出,ViT的优势来自以下几个方面:
ViT不同层的特征更加均匀,而CNN模型不同层的特征呈网格状
ViT的低层的注意力包含全局信息,而CNN的性质在低层只关注局部
在ViT的较高层中,跳跃连接在信息传播中发挥突出作用,而ResNet/CNN跳跃连接在较高层中传递的信息较少
此外,数据的规模和全局平均池化的使用都会对ViT的表示产生很大的影响。
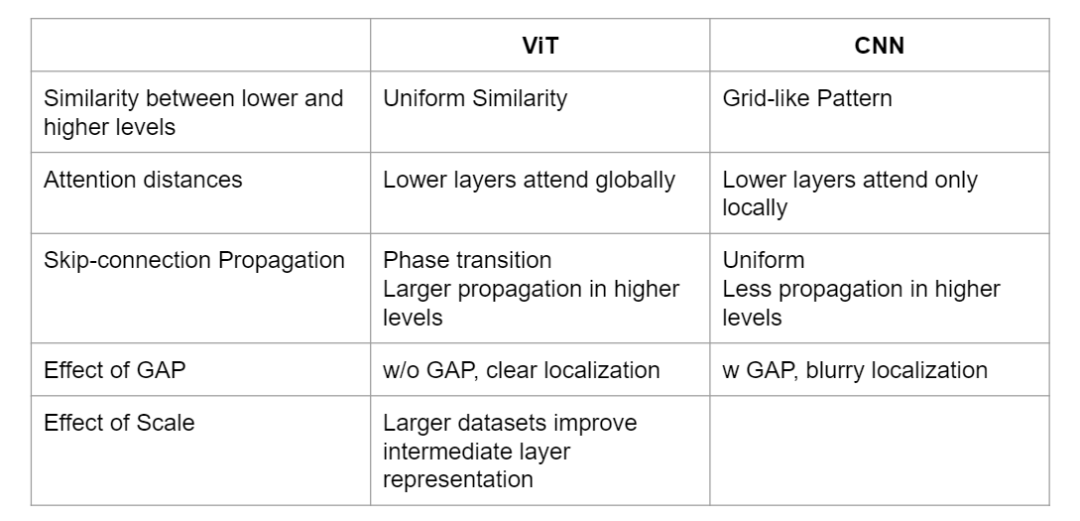
ViT和CNN的主要区别
首先,让我们看看下面的两个架构,ViT和一个典型的CNN模型ResNet50。ResNet50接收整个狗图像,并进行2D卷积,内核大小为7×7,用残差块叠加50层,最后附加一个全局平均池化和一个dense层,将图像分类为“狗”。ViT首先将狗图像分解为16*16个patch,将每个patch视为一个“token”,然后将整个token序列送入transformer编码器,该编码器由多头自注意力块组成,编码器特征随后被发送到MLP层,用于分类“狗”类。
上: ResNet50; 下: ViT
对于两个长度不同的特征向量,很难衡量它们的相似性。因此,作者提出了一种特殊的度量,中心核对齐(CKA),整个论文中都在使用这个。假设X和Y是m个不同样本的特征矩阵,K=XX^T^, L=YY^T^,则利用Hilbert-Schmidt独立准则(HSIC)的定义,定义CKA如下:
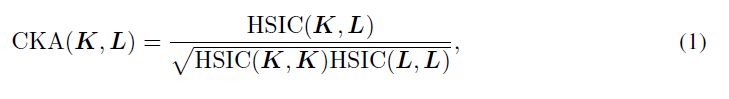
X和Y越相似,CKA值越高。更多的定义细节可以在论文的第3节中找到。
有了CKA的定义,一个自然的问题出现了:ViT和CNN的不同层的特征有多相似?作者表明,模式是相当不同的, ViT在所有层上有一个更统一的特征表示,而CNN/ResNet50在较低和较高的层上有一个网格状的模式。这意味着ResNet50在它的低层和高层之间学习不同的信息。
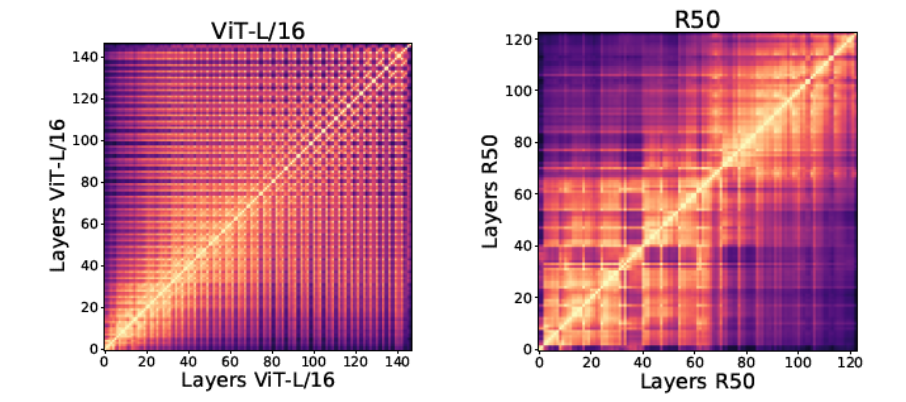
左:ViT各层特征对之间的CKA值,右:ResNet50所有层的特性对之间的CKA值。
但是ResNet在其较低层次和较高层次学习的“不同信息”是什么呢?我们知道对于CNN模型,由于卷积核的性质,在较低的层只学习局部信息,在较高的层学习全局信息。所以在不同的层之间有一个网格状的模式就不足为奇了。那么我们不禁要问,ViT怎么??ViT是否也在其底层学习局部信息?
如果我们进一步观察自注意力头,我们知道每个token会关注所有其他token。每个被关注的token都是一个查询patch,并被分配一个注意力权重。由于两个“token”代表两个图像patch,我们可以计算它们之间的像素距离。通过将像素距离和注意力权重相乘,定义了一个“注意力距离”。较大的注意力距离意味着大多数“远处的patch”具有较大的注意权重——换句话说,大多数注意力是“全局的”。相反,小的注意距离意味着注意力是局部的。
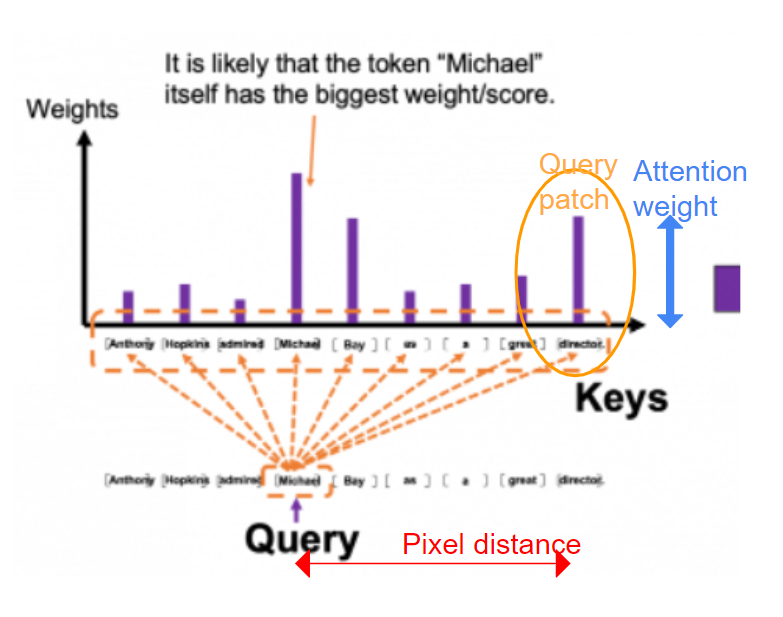
注意力距离的计算
作者进一步研究了ViT中的注意力距离。从下面的结果中,我们可以看到,虽然从较高层(block 22/23,红色高亮显示)的注意力距离主要包含全局信息,但是,即使是较低层(block 0/1,红色高亮显示)仍然包含全局信息。这和CNN的模型完全不同。
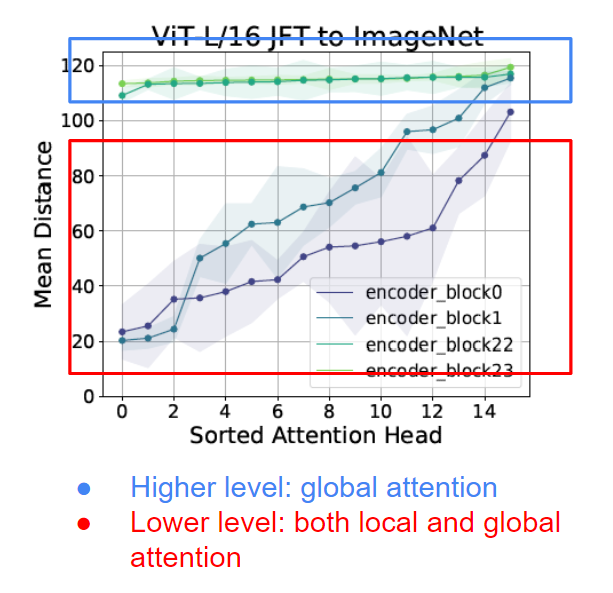
现在我们知道ViT甚至在它的底层也学习全局表示,下一个要问的问题是,这些全局表示会忠实地传播到它的上层吗?如果是这样,是怎么实现的?
作者认为关键是ViT的跳跃连接。对于每个block,在自注意力头和MLP头上都存在跳跃连接。通过将跳跃连接的特征的范数除以通过长分支的特征的范数,作者进一步定义了一个度量:归一化比率(Ratio of norm, RoN)。他们发现了惊人的相变现象,在较低的层次上,分类(CLS)token的RoN值很高,而在较高的层次上则低得多。这种模式与空间token相反,其中RoN在较低的层中较低。
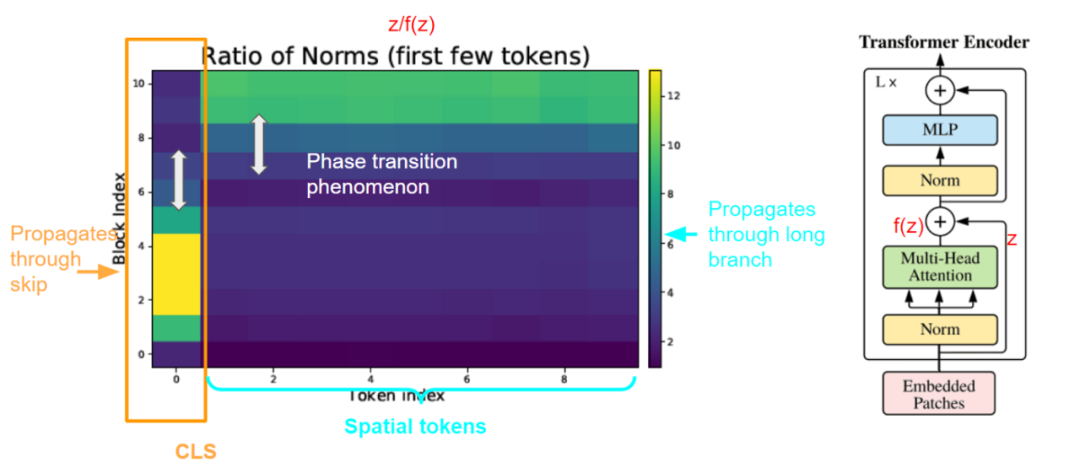
归一化比率:|z|/|f(z)|。其中z是通过跳跃连接的特特征。F (z)是经过长分支的特征。
如果他们进一步删除ViT不同层的跳跃连接,那么CKA映射将如下所示。这意味着跳跃连接是使ViT不同层之间的信息流成为可能的主要(如果不是全部的话)机制之一。
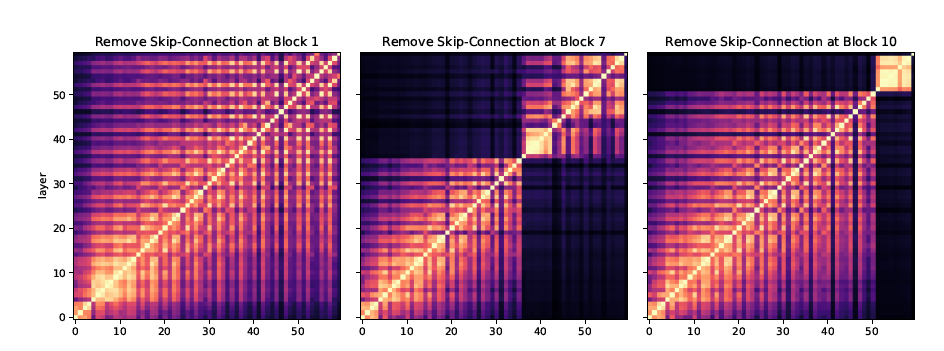
除了强大的跳跃连接机制和在较低层次学习全局特征的能力外,作者还进一步研究了ViT在较高层次学习精确位置表示的能力。这种行为与ResNet非常不同,因为全局平均池化可能会模糊位置信息。
此外,作者指出,有限的数据集可能会阻碍ViT在较低层次学习局部表示的能力。相反,更大的数据集特别有助于ViT学习高质量的中间层表示。
-
构建CNN网络模型并优化的一般化建议2025-10-28 243
-
知行科技大模型研发体系初见效果2024-12-27 1175
-
cnn常用的几个模型有哪些2024-07-11 3187
-
图像分割与语义分割中的CNN模型综述2024-07-09 3477
-
深度神经网络模型cnn的基本概念、结构及原理2024-07-02 12877
-
为什么三相电机比单相电机更具优势?2023-11-09 1320
-
cnn卷积神经网络模型 卷积神经网络预测模型 生成卷积神经网络模型2023-08-21 2475
-
在线研讨会 | 释放 Vision Transformers、NVIDIA TAO 和最新一代 NVIDIA GPU 的潜力2023-06-16 1363
-
如何将DS_CNN_S.pb转换为ds_cnn_s.tflite?2023-04-19 582
-
Github开源的数字手势识别CNN模型简析2022-04-02 5410
-
大家是怎么压榨CNN模型的2019-05-29 1425
-
基于数字CNN与生物视觉的仿生眼设计2009-09-19 20770
全部0条评论

快来发表一下你的评论吧 !
