

基于深度学习的光流估计算法解析
人工智能
描述
光流估计是计算机视觉研究中的一个重要方向,其不像其他感知任务会显式的在应用中呈现。如今,光流估计也在基于视频的任务中承担着越来越重要的作用。
光流的基本概念
光流(Optical Flow)是一个有关物体运动的概念。最早由Gibson提出,描述的是空间中运动的物体在成像平面上,造成像素运动的瞬时速度。主要由以下三类组成:
场景中前景目标本身在移动
成像平面在移动(比如,相机)
或者两者共同运动而所产生的混合动作
光流是在一系列连续变化的图像中产生类似光“流动”的效果,故简称为光流。光流是一个有方向、有长度的矢量,光流估计的目的就是根据2个连续的帧来求解对应像素的运动速度(或偏移量)。根据是否选取图像稀疏点进行光流估计,可以将光流估计分为稀疏光流和稠密光流,demo如下所示: OpenCV也集成了相应的算法接口,稀疏光流cv2.calcOpticalFlowPyrLK()和稠密光流cv2.calcOpticalFlowFarneback(),其中稀疏光流估计算法是最经典的Lucas-Kanade算法,在此不再赘述。
FlowNet
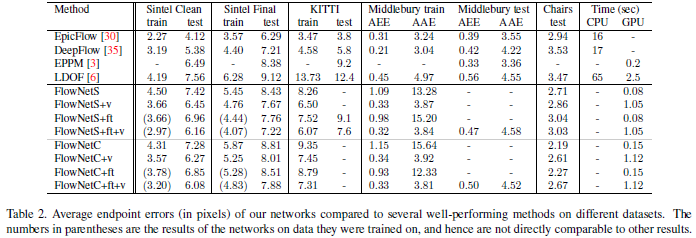
首篇基于深度学习的光流估计算法FlowNet,收录于ICCV2015。FlowNet构建了能够将光流估计问题作为监督学习任务来解决的CNN。提出并比较了两种架构,一种通用架构,另一种包括在不同图像位置关联特征向量的层。由于缺乏相关标注数据集,FlowNet还生成了一个大型合成 Flying Chairs数据集。实验结果表明,在合成数据集上训练的模型可以很好的推广到现实场景,如 Sintel 和 KITTI,在 5 到 10 fps的帧率下实现具有不错的性能。
FlowNet的输入为待估计光流的两张图像,输出即为图像每个像素点的光流。光流的评价指标或损失函数EPE(End-Point-Error),定义为预测的每个像素的光流(2维向量)和groundtruth之间的欧式距离。 对于训练数据集,人工标注光流真值几乎不可能。因此,作者设计了一种生成的方式,得到包括大量样本的训练数据集FlyingChairs。其生成方式为对图像做仿射变换生成对应的图像。为了模拟图像中存在多种运动,比如相机在移动,同时图像中的人或物体也在移动。作者将虚拟的椅子叠加到背景图像中,并且背景图和椅子使用不同的仿射变换得到对应的另一张图,如下图所示:

FlowNetSimple
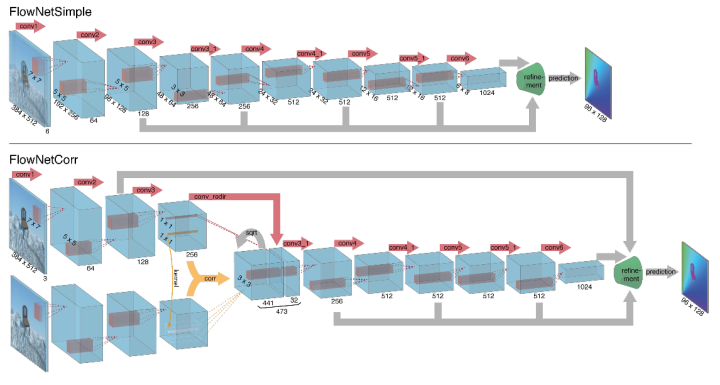
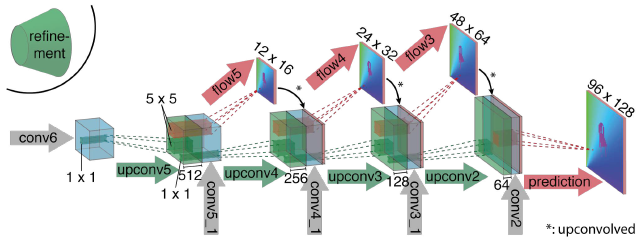
FlowNet提出的通用架构为FlowNetSimple,即将两个输入图像堆叠在一起,并通过一个通用的网络将其输入,从而使网络可以自行决定如何处理图像对以提取运动信息。这种仅包含卷积层的架构为“FlowNetSimple”,而refinement部分,与Unet解码器类似,但是又有独特的光流模型的特性,如下图所示。
FlowNetCorr
和simple版本的区别在于:先对图片做了相同的特征处理,类似于孪生网络,然后对于提取的两个特征图,做论文中提出的叫做correlation处理,融合成一个特征图,然后再做类似于simple版本的后续处理。 FlowNet的实验结果在15年还是比较不错的,与传统方法互有优劣。
FlowNet 2.0
FlowNet证明了光流估计可以作为一个学习问题。然而,关于光流质量的现有技术仍然由传统方法定义。特别是在小位移和真实世界数据上,FlowNet与传统算法还有一定差距。FlowNet 2.0进一步提升了算法的速度和光流质量。首先,FlowNet 2.0增加了训练数据,并使用更复杂的训练策略提升性能。其次,利用堆叠结构对预测结果进行多级提升,最后针对小位移的情况引入特定的子网络进行处理。FlowNet 2.0牺牲了一点运行速度,却降低了50%以上的误差。在各个公开数据集上,精度已经追平了目前最好的一些传统算法。同时,在速度上依然保持着高效快速的优势。
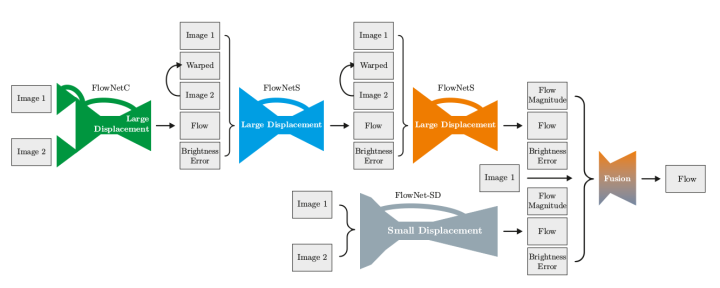
此外,FlowNet 2.0提出了更快的网络结构,速度高达140fps,并且精度与原始FlowNet相当。
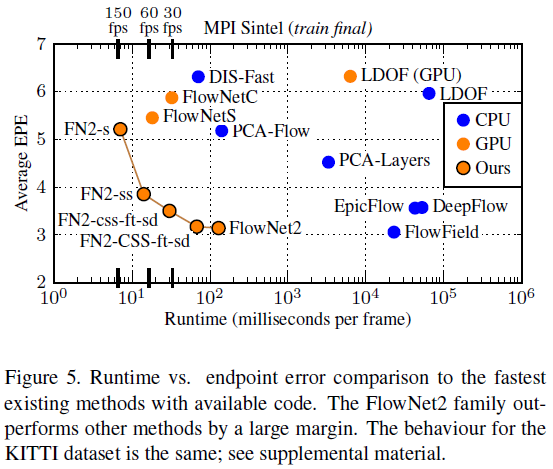
PWC-Net
CVPR2018收录的PWC-Net。PWC-Net根据金字塔式处理;基于上一层习得的光流偏移下一层特征,逐层学习下一层细部光流(warping)和设计代价容量函数(cost volume)实现了比FlowNet 2.0小17倍的网络,更容易训练,性能也更好。在 Sintel分辨率 (1024×436) 图像上以约 35 fps 的速度运行。
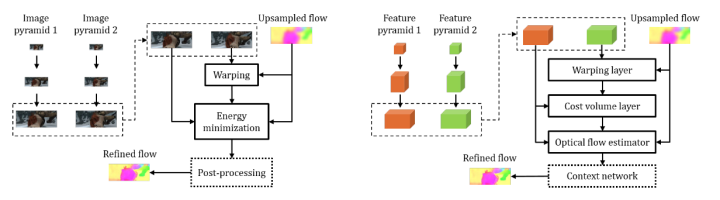
特征金字塔提取器:给定两个输入图像I1和I2,生成特征表示的l级金字塔,底部(0)级是输入图像。为了在第l层生成特征表示,使用卷积层对第1−1金字塔层的特征进行降采样。从第一层到第六级,特征通道的数量分别为16、32、64、96、128和196。 warp层:在l层上,是要warp第二张图到第一张上,l+1层上采样到l层,本文使用双线性插值来实现warp操作,并计算相应梯度。 Cost volume layer:接下来,使用这些特征构造一个cost volume,存储下一帧像素与其相应像素关联的匹配cost volume。
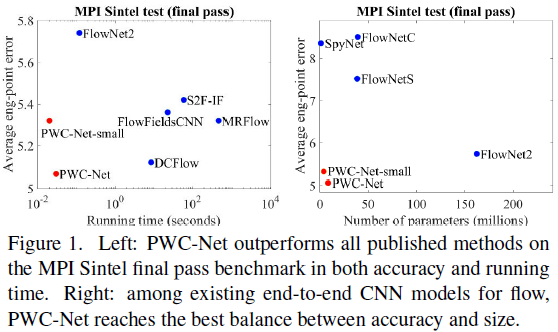
LiteFlowNet2
TPAMI2020!港中文汤晓鸥团队~ FlowNet2需要超过 160M 的参数才能实现准确的流量估计。LiteFlowNet2的模型尺寸小30倍,运行速度快1.36倍,且性能更好。FlowNet2希望在传统光流估计算法和轻量级光流CNN中已经建立的认知之间搭建对应的关系;从早期工作成果LiteFlowNet发展而来的轻量级卷积网络LiteFlowNet2,通过提高流场精度和计算时间更好地解决光流估计问题。主要贡献有如下几点:
轻量级级联式流场推理:提高了光流估计的准确性,允许网络无缝地结合描述子匹配;
新颖的流场正则化层:级联流量推理类似于传统最小化方法中数据保真度的作用。为了解决流场中模糊的流场边界和伪像问题,文章建议使用由特征驱动的局部卷积f-lconv对级联式流场推理的光流场进行规范化。
引入f-warp层:从前一级别的流场估计将F2向F1变形来构建成本量之前减少F1和F2之间的特征空间距离,即Feature Warping。
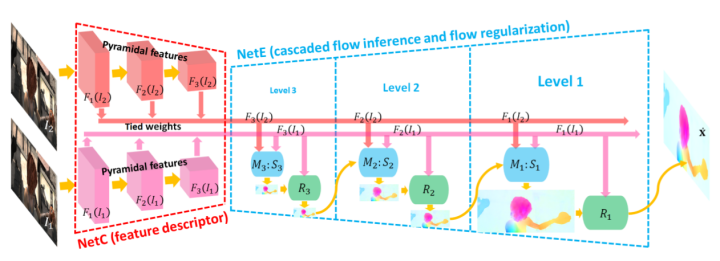
在Sintel和KITTI基准测试集上性能超过了SOTA方法FlowNet2,并且模型尺寸缩小25.3倍,推理速度快3.1倍。GTX1080显卡上的光流估计帧率达到25。
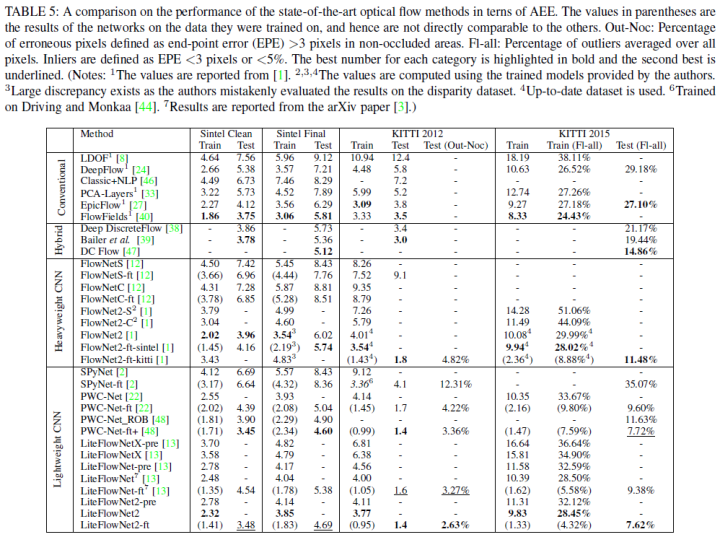
IRR
CVPR2019收录的Iterative Residual Refinement for Joint Optical Flow and Occlusion Estimation 上述算法的共同特征都是从初始光流由粗到细进行Flow推断。虽然精度高,但是参数量也随之增加。IRR从经典的能量最小化方法和残差网络中汲取灵感,提出一种基于权重共享的迭代残差细化方法,IRR可以与多个主干网络结合。减少了参数量的同时,提高了准确性。此外集成了遮挡预测和双向流估计后。IRR可以进一步提升性能。
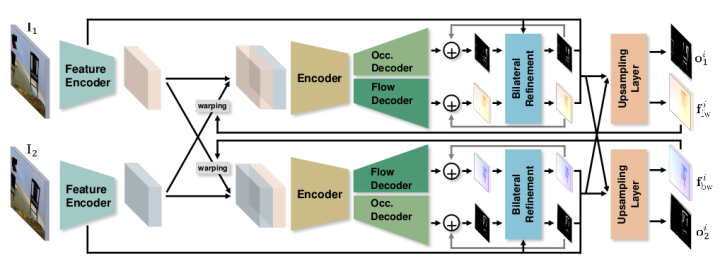
性能和网络参数量对比图如下:
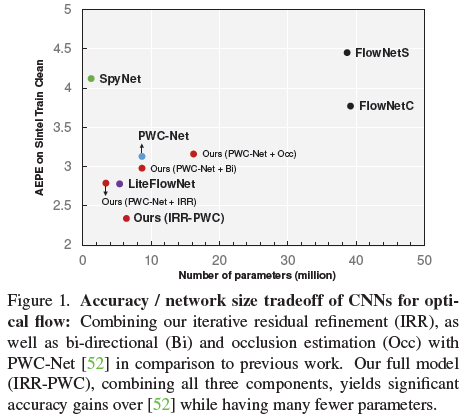
MaskFlownet
特征扭曲是光流估计的核心技术,然而扭曲过程中由遮挡区域引起的模糊性是一个尚未解决的主要问题。图像扭曲导致遮挡区域的模糊,在特征扭曲过程中也存在同样的问题,这些区域可以在没有任何明确监督的情况下被掩盖。因此,MaskFlownet应运而生,主要贡献如下:
MaskFlownet提出了一个非对称遮挡感知特征匹配模块,用于学习一个粗糙的遮挡掩码,在没有任何显式监督的情况下,在特征扭曲后立即过滤无用(遮挡)区域;
模块可以很容易地集成到端到端网络架构中,计算量可忽略同时提升性能。学习到的遮挡掩码可以进一步输入到具有双特征金字塔的后续网络级联中,从而达到SOTA;
RAFT
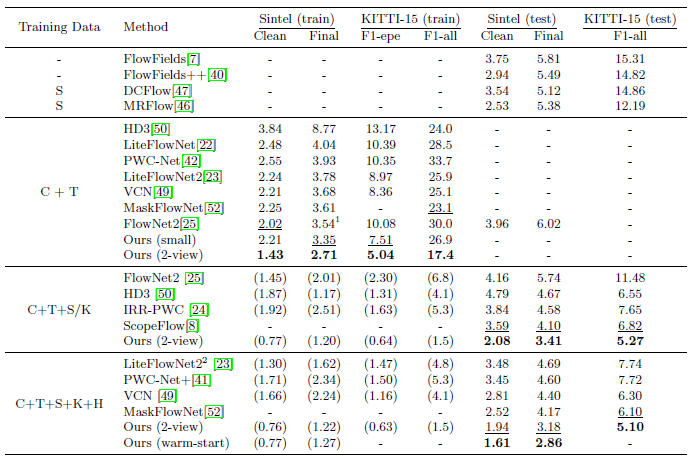
ECCV 2020 best paper! 光流法需要估计视频帧中每个像素的运动,在计算机视觉中这是一个还未被攻克的难题,常见的问题有快速移动的小物体,物体之间的遮挡,运动模糊和存在无纹理区域等问题。传统的光流法常被认为是一种手工设计的优化方法,近年来一些基于深度学习的方法开始有了替代传统方法的趋势。下面介绍一种新的基于深度学习来估计光流的方法——Recurrent All-Pairs Field Transformers(RAFT)。它有以下优势:
state-of-the-art: 在KITTI上RAFT达到了目前最高的准确率。
有很强的泛化性,当只在生成的数据集上训练时RAFT也能有很好的效果。
高效,在1080Ti上能够以10帧每秒运行1088×436像素的图像。
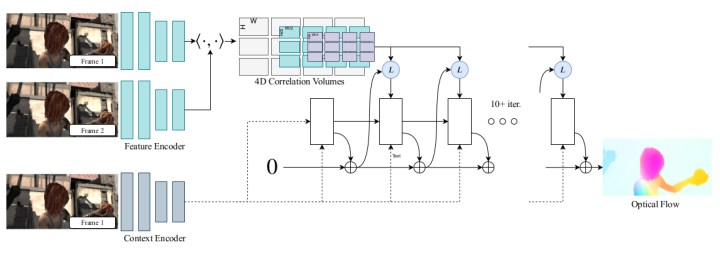
RAFT由以下三部分构成: 1)一个特征编码器来用来从像素中提取特征:特征图的大小是原始分辨率的1/8; 2)一个correlation层用来建模图像上任意两个点之间的相似度; 3)一个基于门控循环网络GRU的更新结构用来迭代的更新最后生成的光流图。 实验结果如下:
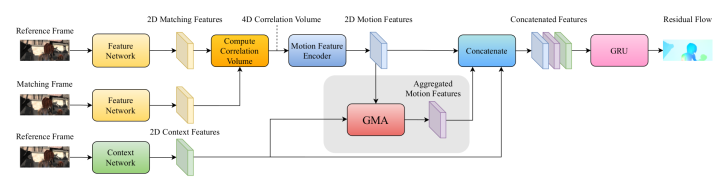
GMA
ICCV2021 收录的Learning to Estimate Hidden Motions with Global Motion Aggregation GMA着重解决光流估计中被遮挡点的光流估计问题。GMA定义的遮挡点是在当前帧中可见但在下一帧中不可见的点。以前的工作依赖CNN来学习遮挡,但收效不大,或者需要多帧并使用时间平滑度来推理遮挡。GMA通过对图像自相似性进行建模,来更好地解决遮挡问题。GMA引入了全局运动聚合模块,这是一种基于transformer的方法,用于查找第一张图像中像素之间的远程依赖关系,并对相应的运动特征进行全局聚合。GMA在不损害非遮挡区域的性能的情况下,可以显著改善遮挡区域中的光流估计。具体的解决方案如下:
两帧之间的运动信息,可以通过计算cost volume的匹配信息进行估计
当没有匹配信息时,基于这样一个假设,单个物体(在前景或背景中)的运动通常是均匀的,运动信息必须从其他像素开始传播
同时,对于每个像素理解他属于哪个对象。也就是说,非被遮挡的自相似点的运动信息可以传播到被遮挡的点。
CNN不适合做全局运动估计,因为CNN是局部的,transformer更适合做全局估计。
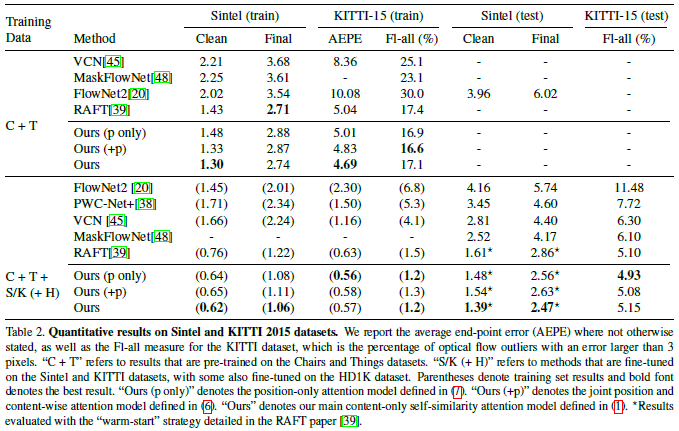
GMA在Sintel 数据集上取得了新SOTA,实验结果如下:
编辑:黄飞
-
目前主流的深度学习算法模型和应用案例2024-01-03 3805
-
基于深度学习的光流计算技术应用2023-09-29 1300
-
深度学习算法简介 深度学习算法是什么 深度学习算法有哪些2023-08-17 10926
-
信道估计算法2022-12-12 2933
-
基于深度学习的二维人体姿态估计算法2021-04-27 1218
-
基于全局背景光估计和颜色校正的图像增强算法2021-03-19 1198
-
基于单目图像的深度估计算法,大幅度提升基于单目图像深度估计的精度2018-06-04 36427
-
基于相位补偿的FDOA估计算法2018-02-28 912
-
山世光谈深度学习生产线、以及中科视拓深度学习算法平台SeeTaaS2017-12-26 5117
-
基于FFT的高精度频率估计算法2012-02-08 943
-
基于空子载波的信噪比估计算法2010-04-23 1962
-
基于PN序列的频偏估计算法2009-08-19 1548
全部0条评论

快来发表一下你的评论吧 !
