

基于OpenAI的GPT-2的语言模型ProtGPT2可生成新的蛋白质序列
描述
人类语言与蛋白质有很多共同点,至少在计算建模方面。这使得研究团队将自然语言处理(NLP)的新方法应用于蛋白质设计。其中,德国Bayreuth大学Birte Höcker的蛋白质设计实验室,描述了基于OpenAI的GPT-2的语言模型ProtGPT2,以基于自然序列的原理生成新的蛋白质序列。
正如字母表中的字母组成单词和句子一样,天然氨基酸以不同的方式结合形成蛋白质。和自然语言一样,蛋白质序列以极高的效率将结构和功能存储在氨基酸序列中。
ProtGPT2是一个深度的、无监督的模型,它利用了变压器架构的进步,而变压器架构也导致了NLP技术的快速发展。该体系结构有两个模块,Noelia Ferruz解释说,她是论文的合著者,也是培训ProtGPT2的人:一个模块理解输入文本,另一个模块处理或生成新文本。第二个是生成新文本的解码器模块,帮助了ProtGPT2的开发。
Researchers have used GPT-2 to train a model to learn the protein “language,” generate stable proteins, and explore “dark” regions of protein space.
“在我们创建这个模型的时候,还有许多其他人在使用第一个模块,”Noelia Ferruz说,“例如ESM、ProtTrans和ProteinBERT。我们的是当时第一个公开发布的解码器,这也是第一次有人直接应用GPT-2。”
Ferruz本人是GPT-2的忠实粉丝。“我发现有一个能写英语的模型给我留下了深刻印象,”她说。这是一个著名的transformer模型,以无监督的方式对40千兆字节的英语互联网文本进行预训练,即使用没有人类标记的原始文本生成句子中的下一个单词。GPT-x系列已被证明能够有效地生成长而连贯的文本,通常与人类书写的文本无法区分,因此潜在的误用是一个令人担忧的问题。
鉴于GPT-2的能力,Bayreuth的研究人员对使用它训练模型学习蛋白质语言、生成稳定的蛋白质以及探索蛋白质空间的“暗”区域持乐观态度。Ferruz在整个蛋白质空间中约5000万个无注释序列的数据集上训练了ProtGPT2。为了评估该模型,研究人员将由ProtGPT2生成的10000个序列的数据集与来自训练数据集的10000个随机序列集进行了比较。
他们发现该模型预测的序列在二级结构上与天然蛋白质相似。ProtGPT2可以预测稳定和功能性的蛋白质,不过,Ferruz说,这将在未来几个月内通过对一组大约30种蛋白质的实验室实验来验证。ProtGPT2还模拟了自然界中不存在的蛋白质,在蛋白质设计领域开辟了可能性。
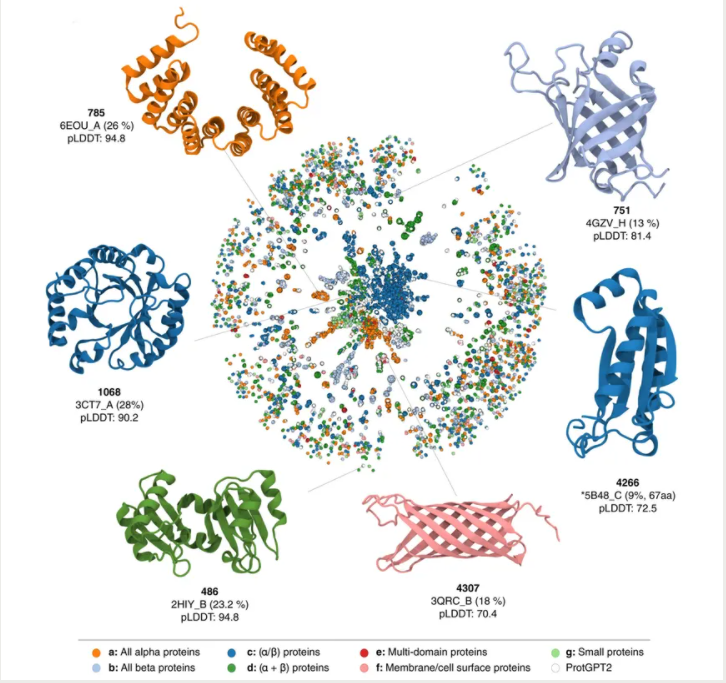
UNIVERSITY OF BAYREUTH/NATURE COMMUNICATIONS
Ferruz说,该模型可以在几分钟内产生数百万种蛋白质。“如果没有进一步的改进,人们可以采用免费提供的模型,并对一组序列进行微调,以在该区域产生更多的序列,例如抗生素或疫苗。”但是,她补充说,通过对训练过程进行小的修改,“我们可以添加标签,并有可能在未来开始生成具有特定功能的序列。”这反过来不仅在医疗和生物医学领域,而且在环境科学等领域有潜在的应用。
Ferruz承认NLP领域的快速发展为ProtGPT2的成功做出了贡献,但同时也指出,这是一个不断变化的领域 —— “过去12个月发生的所有事情都太疯狂了。”目前,她和她的同事已经在写一篇关于他们工作的评论。“我在2021圣诞节训练了这个模型,”她说,“当时,有另一个模型已经被描述过了……但它不可用。”不过她表示,到今年春天,其他模型已经发布。
ProtGPT2的预测序列跨越了新的、很少探索的蛋白质结构和功能区域。然而,几周前,DeepMind发布了超过2亿种蛋白质的结构。“所以我想我们已经没有那么多的暗蛋白质组了,”Ferruz说,“但仍有一些地区……尚未被探索。”
不过,前面还有很多准备工作要做。“我想控制设计过程,”Ferruz补充道,“我们将需要获取序列,预测结构,并可能预测功能(如果有的话)……这将是非常具有挑战性的。”ProtGPT2是面向高效蛋白质设计和生成迈出的一大步,为探索设计蛋白质结构和功能的参数及其后续实际应用的实验研究奠定了基础。
-
面向生物传感器和电路的蛋白质纳米线2018-12-03 2033
-
蛋白质组学技术与药物作用新靶点研究进展 精选资料分享2021-07-26 1734
-
点成分享 | 蛋白质浓度测定之BCA法2022-12-20 4825
-
基于PPI网络与机器学习的蛋白质功能预测方法2018-04-17 1566
-
OpenAI发布一款令人印象深刻的语言模型GPT-22019-05-17 5372
-
OpenAI宣布,发布了7.74亿参数GPT-2语言模型2019-09-01 3753
-
基于衰减系数的动态蛋白质预测网络模型2021-06-15 1000
-
食品蛋白质测定仪的特点及功能2021-07-27 833
-
蛋白质测定仪的特点、功能及参数2021-08-17 1072
-
蛋白质快速检测仪的特点及功能2021-09-02 1432
-
蛋白质测定仪工作原理是怎样的2021-11-15 3394
-
使用AlphaFold2进行蛋白质结构预测2022-11-07 4119
-
NVIDIA 和 Evozyne 创建用于生成蛋白质的生成式 AI 模型2023-01-13 1304
-
蛋白质快速检测仪 产品说明2021-03-09 1642
-
EvolutionaryScale推出基于NVIDIA GPU模型的新型蛋白质研究方案2024-08-23 2039
全部0条评论

快来发表一下你的评论吧 !
