

详细介绍python中文件操纵相关知识
电子说
描述
一、文件的打开和关闭
open()函数
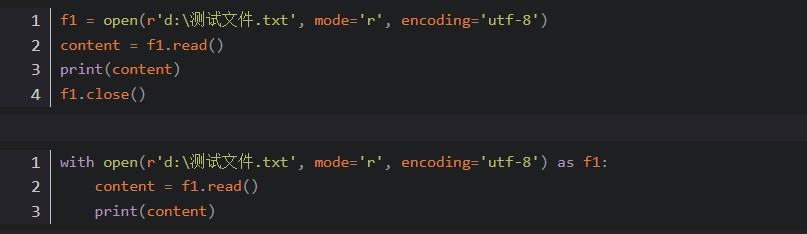
open()内置函数,open底层调用的是操作系统的接口。
f1变量,又叫文件句柄,通常文件句柄命名有f1,fh,file_handler,f_h,对文件进行的任何操作,都得通过文件句柄.方法的形式。
encoding:可以不写。不写参数,默认的编码本是操作系统默认的编码本。windows默认gbk,linux默认utf-8,mac默认utf-8。
mode:可以不写。默认mode='r'。
f1.close()关闭文件句柄。
另外使用with open()的好处:

绝对路径和相对路径
1.绝对路径:指的是绝对位置,完整地描述了目标的所在地,所有目录层级关系是一目了然的。比如C:/Users/Python37/python.exe
2.相对路径:是从当前文件所在的文件夹开始的路径。
2.1 test.txt:是在当前文件夹查找 test.txt 文件。
2.2 ./test.txt:也是在当前文件夹里查找test.txt文件, ./ 表示的是当前文件夹,可以省略。
2.3 ../test.txt:从当前文件夹的上一级文件夹里查找 test.txt 文件。../ 表示的是上一级文件夹。
2.4 demo/test.txt,在当前文件夹里查找demo这个文件夹,并在这个文件夹里查找 test.txt文件。
3.路径书写的三种方法 3.1:\
file = open('C:\Users\Python基础\xxx.txt')
3.2: r''
file = open(r'C:UsersPython基础xxx.txt')
3.3 :'/'(推荐)
file = open('C:/Users/Python基础/xxx.txt')
常用文件的访问模式


二、文件的读取和写入
1.读取



2.写入

关于清空
关闭文件句柄,再次以w模式打开此文件时,才会清空。
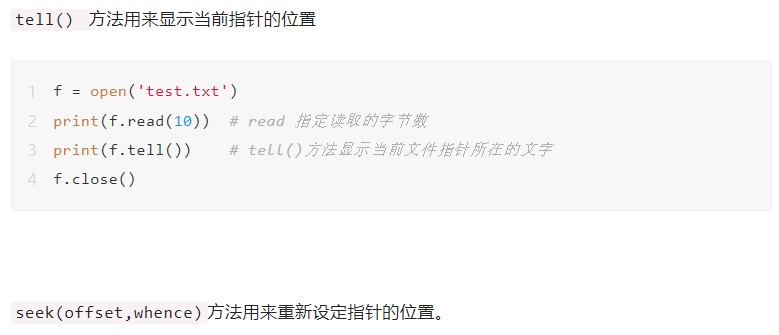
3.指针定位

三、实现文件拷贝功能

四、CSV文件的读写
CSV文件
CSV文件:Comma-Separated Values,中文叫逗号分隔值或者字符分割值,其文件**以纯文本的形式存储表格数据。**可以把它理解为一个表格,只不过这个表格是以纯文本的形式显示的,单元格与单元格之间,默认使用逗号进行分隔;每行数据之间,使用换行进行分隔。
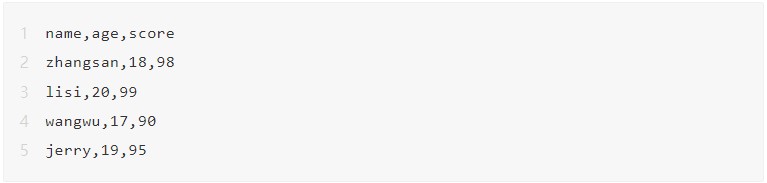
Python中的csv模块,提供了相应的函数,可以让我们很方便的读写csv文件。
CSV文件的写入 
CSV文件的读取

五、将数据写入内存
除了将数据写入到一个文件以外,我们还可以使用代码,将数据暂时写入到内存里,可以理解为数据缓冲区。Python中提供了StringIO和BytesIO这两个类将字符串数据和二进制数据写入到内存里。
StringIO

BytesIO
如果想要以二进制的形式写入数据,可以使用BytesIO类,它的用法和StringIO相似,只不过在调用write方法写入时,需要传入二进制数据。

六、sys模块的使用
sys.stdin 接收用户的输入,就是读取键盘里输入的数据,默认是控制台。input方法就是读取 sys.stdin 里的数据。

sys.stdout 标准输出,默认是控制台


七、序列化和反序列化
通过文件操作,我们可以将字符串写入到一个本地文件。但是,如果是一个对象(例如列表、字典、元组等),就无法直接写入到一个文件里,需要对这个对象进行序列化,然后才能写入到文件里。
序列化:将数据从内存持久化保存到硬盘的过程。 反序列化:将数据从硬盘加载到内存的过程。 python 里存入数据只支持存入字符串和二进制。 json:将Python里的数据(str/list/tuple/dict)等转换成为对应的json。 pickle:将Python里任意的对象转换成为二进制。 Python中提供了JSON和pickle两个模块用来实现数据的序列化和反序列化。
JSON模块
JSON(JavaScriptObjectNotation, JS对象简谱)是一种轻量级的数据交换格式,它基于 ECMAScript 的一个子集,采用完全独立于编程语言的文本格式来存储和表示数据。JSON的本质是字符串,区别在于json里要是用双引号表示字符串。
使用JSON实现序列化
dumps方法的作用是把对象转换成为字符串,它本身不具备将数据写入到文件的功能。

dump方法可以在将对象转换成为字符串的同时,指定一个文件对象,把转换后的字符串写入到这个文件里。

使用JSON实现反序列化
loads方法需要一个字符串参数,用来将一个字符串加载成为Python对象。

load方法可以传入一个文件对象,用来将一个文件对象里的数据加载成为Python对象。

pickle模块
和json模块类似,pickle模块也有dump和dumps方法可以对数据进行序列化,同时也有load和loads方法进行反序列化。区别在于,json模块是将对象转换成为字符串,而pickle模块是将对象转换成为二进制。
pickle模块里方法的使用和json里方法的使用大致相同,需要注意的是,pickle是将对象转换成为二进制,所以,如果想要把内容写入到文件里,这个文件必须要以二进制的形式打开。
使用pickle模块实现序列化
dumps方法将Python数据转换成为二进制

dump方法将Python数据转换成为二进制,同时保存到指定文件

load方法,读取文件,并将文件的二进制内容加载成为Python数据

json模块:
将对象转换成为字符串,不管是在哪种操作系统,哪种编程语言里,字符串都是可识别的。
json就是用来在不同平台间传递数据的。
并不是所有的对象都可以直接转换成为一个字符串,下标列出了Python对象与json字符串的对应关系。
| Python | JSON |
|---|---|
| dict | object |
| list,tuple | array |
| str | string |
| int,float | number |
| True | true |
| False | false |
| None | null |
如果是一个自定义对象,默认无法装换成为json字符串,需要手动指定JSONEncoder。
如果是将一个json串重新转换成为对象,这个对象里的方法就无法使用了。

pickle模块:
pickle序列化是将对象按照一定的规则转换成为二进制保存,它不能跨平台传递数据。
pickle的序列化会将对象的所有数据都保存。
审核编辑:刘清
-
Python中文乱码怎么处理?python中文乱码解决办法2017-12-27 4370
-
详细的EMC知识介绍!2021-09-23 6239
-
电阻式传感器原理及相关知识详细介绍2009-12-01 3049
-
Python的基础语法知识点大全2020-06-12 1364
-
Python的基本知识和特点及功能详细说明2020-07-09 1510
-
python文件读取的源代码免费下载2020-08-07 1332
-
如何使用Python绘制PDF文件教程详细说明2020-08-27 3149
-
python的基础知识培训教程课件免费下载2020-09-04 1575
-
python的文件操作实例代码说明2020-09-07 1165
-
使用文件保存游戏的python代码和资料说明2020-09-24 1702
-
Python的知识点总结详细说明2020-09-29 1775
-
Python进行配置文件的教程免费下载2020-09-30 1055
-
python的经典实例相关讲解2021-03-02 1059
-
介绍Python中文件创建与写入的基本方法2023-04-27 4262
-
如何解决Python爬虫中文乱码问题?Python爬虫中文乱码的解决方法2024-01-12 3975
全部0条评论

快来发表一下你的评论吧 !
