

编译器理论之别名分析分类
描述
1.简介
别名分析是编译器理论中的一种技术,用于确定存储位置是否可以以多种方式访问。如果两个指针指向相同的位置,则称这两个指针为别名。但是,它不能与指针分析混淆,指针分析解决的问题是一个指针可能指向哪些对象或者指向哪些地址,而别名分析解决的是两个指针指向的是否是同一个对象。指针分析和别名分析通常通过静态代码分析来实现。
别名分析在编译器理论中非常重要,在代码优化和安全方面有着非常广泛且重要的应用。编译器级优化需要指针别名信息来执行死代码消除(删除不影响程序结果的代码)、冗余加载/存储指令消除、指令调度(重排列指令)等。编译器级别的程序安全使用别名分析来检测内存泄漏和内存相关的安全漏洞。
2.别名分析分类
别名分析种类繁多,通常按如下属性进行分类:域敏感度(field-sensitivity)、过程内分析(Intra-Procedural)v.s.过程间分析(Inter-Procedural)、上下文敏感度(context-sensitivity)和流敏感度(flow-sensitivity)。
2.1 域敏感(Field-Sensitivity)
域敏感度是对用户自定义类型进行分析的一种策略(亦可以处理数组)。在域敏感维度共有三种分析策略:域敏感(field-sensitive)、域非敏感(field-insensitive)、域基础分析(field-based)。以下面代码为例:
struct Test {
int field1;
int field2;
}
Test a1;
Test a2;
Note:field这里为结构体或者类的数据成员。
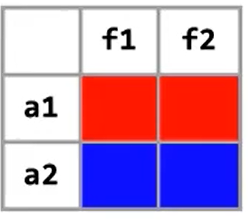
域非敏感:对每个对象建模,而对对象中的成员不进行处理;其建模后的结果如下图,仅有a1.*和a2.*的区别:
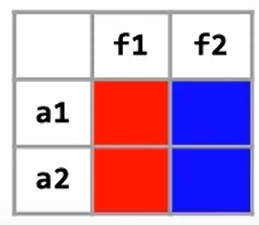
域基础分析:仅对结构体中的成员进行建模,而不感知对象。其建模后的结果如下图,仅有*.field1和*.field2:
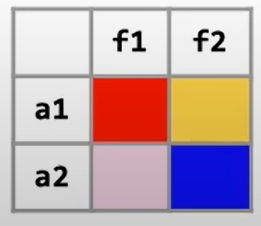
域敏感:既对对象建模,又对成员变量进行处理。其建模后的结果如下图,有a1.field1、a1.field2、a2.field1、a2.field2:
处理数组时,相同的原则亦适用。以C整数数组为例:int a[10],域非敏感分析仅使用一个节点建模:a[*],而域敏感分析创建10个节点:a[0]、a[1]、...、a[9]。
总结:域敏感别名分析准确性高,但是当存在嵌套结构或者大数组时,节点数量会迅速增加,分析成本也会陡然上升。
2.2 过程内分析(Intra-Procedural)v.s.过程间分析(Inter-Procedural)
过程内分析仅分析函数体内部的指针,并没有考虑与其他函数之间的相互影响。需要特别指出的是,过程内分析当处理包含指针入参的函数或者返回指针的函数时,其分析可能不够准确。相反,过程间分析会在函数调用过程中处理指针的行为。
过程内分析不易于扩展,精度较低。相比过程间分析,过程内分析更容易实现,且过程内/间分析与上下文敏感度分析高度相关,因为一个上下文敏感分析必定是一个过程间分析。
2.3 上下文敏感度(Context-Sensitivity)
上下文敏感度用来控制函数调用该如何分析。有两种分析方法:上下文敏感(context-sensitive) 和上下文非敏感(context-insensitive)。上下文敏感在分析函数调用的目标(被调用者)时考虑调用上下文(调用者)。以如下代码为参考[1]:
1 public static void main(String[] args) {
2 String name1 = getName(3); // Tainted
3 String sql1 = "select * from user where name = " + name1;
4 sqlExecute(sql1); // Taint Sink
5
6 String name2 = getName(-1); // Not Tainted
7 String sql2 = "select * from user where name = " + name2;
8 sqlExecute(sql2);
9 }
10
11 private static String getName(int x) {
12 if (x > 0) {
13 return System.getProperty("name");
14 } else {
15 return "zhangsan";
16 }
17 }
如上所示,getName()方法基于入参的不同,会返回不同的结果,在第2行和第6行,获取到的name1和name2的污点信息不同,当入参为3时,返回的是一个从环境变量中获取的污染的数据,导致sql注入,而当入参为-1时,返回的是一个常量,不是污染数据,不会有问题。在上下文敏感的分析中,在第4行应该报一个sql注入问题,而在第8行则不应该报sql注入问题。而上下文非敏感的分析中,不考虑传入参数的不同,getName()方法则全部返回一个{System.getProperty("name")}∨{zhangsan},从而导致第4行和第8行都会报一个sql注入的问题。
上下文敏感别名分析需要有一种方法,为函数getName创建抽象描述,以便每次调用它时,分析器都可以将调用上下文应用于抽象描述。
总结:上下文敏感分析比较准确,但是增加了复杂度。
2.4 流敏感度(Flow-Sensitivity)
流敏感度是一种是否考虑代码顺序的原则。有两种方法:流敏感(flow-sensitive)和流非敏感(flow-insensitive)。
流非敏感不考虑代码顺序,并为整个程序生成一组别名分析结果,而流敏感考虑代码顺序,计算程序中每个指针出现的位置的别名信息。以如下代码为例:
1 int a,b; 2 int *p; 3 p = &a; 4 p = &b;
流非敏感的分析结果是针对整个代码块,其结果应该是:指针p可能指向变量a或者变量b。流敏感生成的别名信息是,在第3行,指针p指向变量a,在第4行以后指针p指向变量b。
Note:当程序具有许多条件语句、循环或递归函数时,流敏感分析的复杂性会大大增加。要执行流敏感分析,需要完整的控制流图。因此,流敏感分析非常精确,但对于大多数情况来说,它的分析成本过高,无法在整个程序上执行。
3.别名分析常见算法介绍
常见的别名算法共有三种:Andersen's指针分析算法、Steensgaard's指针分析算法和数据结构分析算法。
Andersen's指针分析是一种流非敏感和上下文非敏感的分析算法。Andersen's指针分析算法复杂度较高,实践应用性较差,其时间复杂度为,其中n为指针节点个数。
Steensgaard's指针分析算法也是一种流非敏感,上下文非敏感且域非敏感的别名分析算法。其时间复杂度较低,实现相对简单,实践应用广,其时间复杂度为,其中无限接近于1,但是其别名分析的准确性较低。
数据结构分析算法是一种流非敏感,上下文敏感和域敏感的算法。其时间复杂度较低,为O(n * log(n)) ,应用性较好,但是由于不支持MustAlias(参考“AliasAnalysis Class概览”章节),导致其应用有局限性。
4.别名分析在LLVM中的应用与实现
4.1 应用
别名分析在代码优化和安全方面有着非常重要且广泛的应用,以下面C代码为例,来简单介绍别名分析在代码优化方面的应用[2]。
int foo (int __attribute__((address_space(0)))* a,
int __attribute__((address_space(1)))* b) {
*a = 42;
*b = 20;
return *a;
}
__attribute__属性指定了变量a指向地址0,变量b指向地址1。我们知道在ARM架构中,地址0和地址1是完全不同的,修改地址0中的内存永远不会修改地址1中的内存。以下为该函数可能生成的LLVM IR信息:
define i32 @foo(i32 addrspace(0)* %a, i32 addrspace(1)* %b) #0 {
entry:
store i32 42, i32 addrspace(0)* %a, align 4
store i32 20, i32 addrspace(1)* %b, align 4
%0 = load i32, i32* %a, align 4
ret i32 %0
}
第一个store将42存储到变量a指向的地址,第二个store指令将20存储到变量b指向的地址。%0 = ... 指向的行将变量a中的值加载到一个临时变量0中,并在最后一行返回该临时变量0。
上述代码是未对foo函数进行优化的情况,下面我们考虑对foo函数进行优化。
我们优化后的代码可能如下:删除了load指令对应的行,最后一行直接返回了常量42。
define i32 @foo(i32 addrspace(0)* %a, i32 addrspace(1)* %b) #0 {
entry:
store i32 42, i32 addrspace(0)* %a, align 4
store i32 20, i32 addrspace(1)* %b, align 4
ret i32 42
}
然而,我们进行优化的时候需要仔细一些,因为上述优化仅在a和b指向的地址不会相互影响时有效。例如:当我们给foo函数传递的指针相互影响时:
int i = 0; int result = foo(&i, &i);
在未开启优化的版本中,变量i将先被设置为42,然后被设置为20,最后返回20。然而,在优化版本中,虽然我们执行了两次store操作依次将42、20赋值给变量i,但是返回值是42,而不是20。因此优化版本破坏了foo函数本身的行为。
如果应用了别名分析,编译器能够合理地执行上述优化。在执行优化前判断入参a和b是否为别名,如果是别名,则不执行删除load指令对应行的操作,否则执行删除操作。
4.2 实现
本文以LLVM16.0.0版本为参考,从代码接口入手,带领大家学习别名分析的代码实现。
LLVM AliasAnalysis类是LLVM系统中客户使用和别名分析实现的主要接口,或者说一个“基类” 。除了简单的别名分析信息外,这个类还声明了Mod/Ref信息,从而使强大的分析和转换能够很好地协同工作。
源码参考链接:AliasAnalysis.h[3]、AliasAnalysis.cpp[4]。
4.2.1 基础知识
MemoryLocation:LLVM中对内存地址的描述,主要应用在别名分析中,我们需要掌握该类中三个属性:

其中,Ptr表示内存开始地址,Size表示内存大小,AATags是描述内存位置别名的metadata节点集合 。
4.2.2 AliasAnalysis Class 概览
AliasAnalysis类定义了各种别名分析实现应该支持的接口。这个类导出两个重要的枚举:AliasResult和ModRefResult,它们分别表示别名查询或mod/ref查询的结果。
1、关键代码如下,AliasAnalysis为AAResults类别名:

2、AliasResult关键代码如下:

其中NoAlias表示两个内存对象没有任何重叠区域;MayAlias表示两个指针可能指向同一对象;PartialAlias表示两个内存对象对应的地址空间有重叠;MustAlias表示两个内存对象总是从同一位置开始。
3、ModRefResult关键代码

其中NoModRef表示访问内存的操作既不会修改该内存也不会引用该内存;Ref表示访问内存的操作会可能引用该内存;Mod表示访问内存的操作可能会修改该内存;ModRef表示访问内存的操作既可能引用该内存也可能修改该内存。
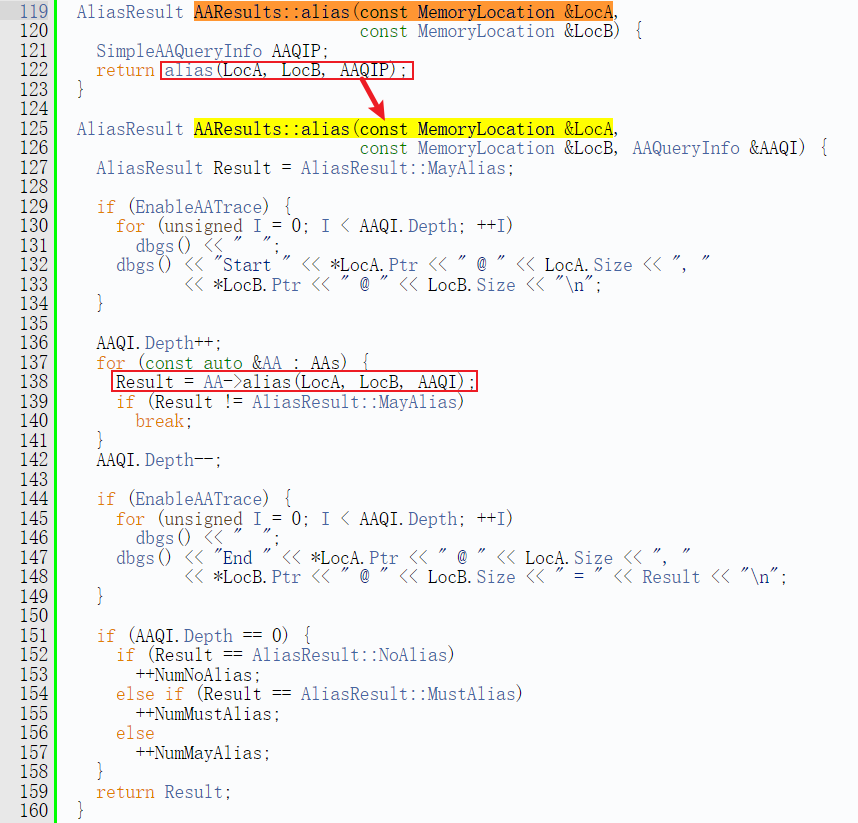
alias接口
其接口定义如下:
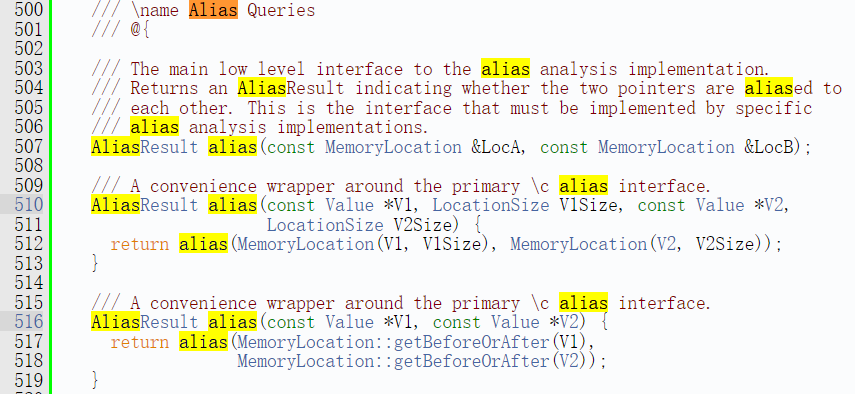
别名方法是用于确定两个MemoryLocation对象是否相互别名的主要接口。它接受两个MemoryLocation对象作为输入,并根据需要返回MustAlias、PartialAlias、MayAlias或NoAlias。与所有AliasAnalysis接口一样,alias方法要求其入参的两个MemoryLocation对象定义在同一个函数中,或者至少有一个值是常量。
其接口实现如下:
getModRefInfo 接口
getModReInfo方法返回关于给定的指令执行是否可以读取或修改给定内存位置的信息。Mod/Ref信息具有保守性:如果一条指令可能读或写一个位置,则返回ModRef。其接口定义众多,我们以如下接口为例来进行学习。

其接口实现如下:

从上述代码可知,处理共分为四步:
(1)遍历AAs,如果发现其任一结果是NoModRef,则直接返回,对应代码行228-234;
(2)调用节点(call)操作中是否访问了一个在LLVM IR中无法访问的地址,如果是的话,直接返回NoModRef,否则获取其调用节点的ModRefInfo信息,对应代码行239-240;
(3)处理调用节点中指针入参的ModRefInfo信息,如果发现是NoModRef,则直接返回NoModRef,否则将ModRefInfo信息和之前的结果合并,对应代码行247-266;
(4)如果getModRefInfo函数中的入参Loc指定的内存地址具有常量属性并且ModRefInfo信息包含Mod,则调用节点一定不会修改Loc内存,因此需要将Ref属于与之前的结果做逻辑与操作,对应代码行271-272。
4.2.3 LLVM中已经实现的别名分析
-basic-aa pass
-basic-aa pass是一种激进的本地分析,它提供许多重要的事实信息[5]:
不同的全局变量、堆栈分配和堆分配永远不能别名。
全局变量、栈分配的变量和堆分配变量永远不会和空指针别名。
结构体中的不同字段不能别名。
同一数组,索引不同的两个对象不能别名。
许多通用的标准C库函数从不访问内存或只读取内存。
-globals-aa pass
这个pass实现了一个简单的对内部全局变量(该变量的地址没有被获取过)进行上下文敏感的mod/ref分析和别名分析。如果某个全局变量的地址没有被获取,则该pass可以得出如下结论:没有指针作为该全局变量的别名。该pass还会识别从不访问内存或从不读取内存的函数。这允许某些指定的优化(例如GVN)完全消除调用指令。
这个pass的真正威力在于它为调用指令提供了上下文敏感的mod/ref信息。这使优化器清楚的了解到对于某些函数的调用不会破坏或读取全局变量的值,从而允许消除加载和存储指令。
Note:该pass在使用范围上有一定限制,仅支持没有被取过地址的全局变量,但是该pass分析速度非常快。
除了上述pass外,LLVM中还实现了cfl-steens-aa、cfl-anders-aa、tbaa、scev-aa。目前LLVM中O1,O2,O3优化默认开启的别名分析是basic-aa,globals-aa和tb-aa。
5.写在最后
编译器技术从20世纪50年代起,已经发展了近70年的历史,但是编译器技术发展到今天,依然是一个非常热门的技术,各大硬件厂商都在开发自己的编译器,包括因特尔推出的Inter C++、ARM公司推出的armclang以及华为推出的毕昇编译器等,且上述三款编译器都是基于LLVM开发。
编译器技术是一门庞大且繁杂的技术,对于初学者来说,这条学习之路道阻且长,盼那些热爱这门技术的赶路人能够行而不辍,未来可期。
-
Triton编译器的优势与劣势分析2024-12-25 2437
-
Triton编译器功能介绍 Triton编译器使用教程2024-12-24 3718
-
编译器优化那些事儿:别名分析概述2023-05-24 1417
-
领域编译器发展的前世今生2023-02-03 3023
-
交叉编译器安装教程2022-09-29 5076
-
编译器优化那些事儿(6):别名分析概述2022-09-15 12135
-
Verilog HDL 编译器指令说明2021-11-03 5338
-
编译器原理到底是怎样的带你简单的了解编译器原理2018-12-23 12659
-
编译器是如何工作的_编译器的工作过程详解2017-12-19 18523
-
NEC编译器培训手册2016-05-03 719
-
PICC编译器下载2015-05-25 2075
-
基于CoSy的编译器开发的研究2013-08-19 900
-
ICC AVR编译器的安装与使用2010-07-09 1391
全部0条评论

快来发表一下你的评论吧 !
