

预训练模型在搜索中使用的思路和方案
描述
当然了,和往常的文章一样,我不会复述这一篇文章,而是聊聊里面的一些关键点和一些有意思的内容,拿出来和大家讨论一下。
搜索的常规结构
有关搜索的结构,其实在很多之前的文章都已经有聊过,这里再借这篇文章聊聊吧,直接上图:
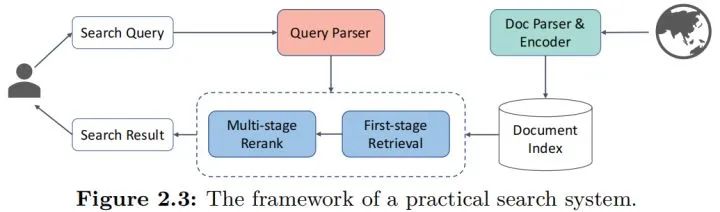
先从左边开始,是用户视角的处理流程,用户输入检索query后,需要经过一系列的预处理和解析,包括以前常说的意图识别,在这个图里都算入parser中,经过预处理后,就会进入常规的信息检索流程,现在的主流就是“检索+召回”的模式,即先从库里面找出一整批比较接近的,然后经过一定的排序模型对这些结果进行排序,最终给出搜索结果。
而从右边开始,是各种文档,或者说物料的输入到入库的流程,Parser和Encoder就是预处理和编码的流程,然后就可以入库了,这里用“index”就是一个索引的过程,索引本身是一个协助检索加速的过程,有了索引能让检索过程变得足够快,毕竟用户视角的检索速度不能因为库很大而被降低,这其实是搜索里面非常重要的问题了,因和本文无关这个点到为止。
因此,其实要算法工作的地方,其实就这几个:
Query Parser,即query预处理和理解部分,需要通过算法的方式对query进行解析。
Retrieval,即检索部分,从库里面粗筛出可能对的结果的部分。
Rerank,即排序部分,这里涉及的就是排出最优的结果有限放到用户面前的过程。
Doc Parser&Encoder,即对文档处理的部分,什么样的解析和表征能更好地入库检索的同时,更快更准地被Retrieval找到。
Retrieval
所谓的检索,其实就是输入用户query,然后从库里面找到和query最相关的TOPN的结果的这个过程,而一般地,主要是3种情况,按照论文的说法:
sparse,稀疏型,其实就是经典的全匹配的形式,我理解是因为onehot化后其实就是稀疏的所以这么说吧。
dense,稠密型,说白了就是我们常说的向量表征后用ANN的方式来进行查询的方法。
综合型,就是综合上述两者来进行的操作。
首先聊聊sparse型吧,这应该是前一个阶段比较流行的方案了,但是现在仍方兴未艾。在预训练的使用上,则更聚焦在稀疏型特征的更精准地抽取上,例如上游意图识别的处理(这个其实放在了后续的章节里),或者是在词权重问题上的进一步优化(term-weighting),这些其实在比较老的阶段已经有一些比较优秀的方案,但是换上预训练模型后,确实有不小的提升,同时从系统层面,系统的迭代升级,直接更换模型会比较方便,风险低而且可控性高,确实是大家更容易想到的手段了。
而dense型,对应的就是我们说的语义向量召回,别以为只是把表征模块换成预训练模型那么简单(如SBERT),其实还有很多花样,我来列举一下:
单向量表征和多向量表征,即在计算相似度的时候是用一个向量还是多个向量,这种用多个向量的其实并不少见,至少在论文里。
专门为了向量检索而设计的预训练模型和任务,也可以说是Further pretrain或者是fine-tuning的一种思路。
难负例的挖掘和使用的探索,这方面在排序阶段也有提及,属于语义相似度上的老问题了。
而综合型,则是一些统一考虑两种类型特征,一起使用的方案,本质上研究的是这两种信息的融合方式,同时也是在探索两者的分工和地位,例如有的研究是让预训练模型拟合BM25后的残差,有的研究这是考虑复杂的融合。
Rerank
排序也是搜索中非常重要的部分,要最终的结果足够准,排序肯定是更为关键的一环,甚至更为极端的,很多搜索在架构上,设计的排序模块是多层多元的,和推荐类似,所以更多大家会叫reranker,这个点到为止,回到排序本身,而常见的,模型在排序侧,尤其是预训练模型的使用上,会有两种形式:
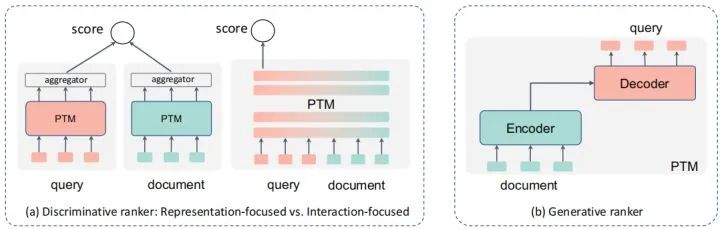
判别式,即直接用类似分类的方式,直接给出query对各个doc的打分,选下图种中间的那个形式。
生成式,假设文档和query中间存在一个生成的过程,通过刻画文档->query或相反的过程来判断两者的相似关系。
判别式排序
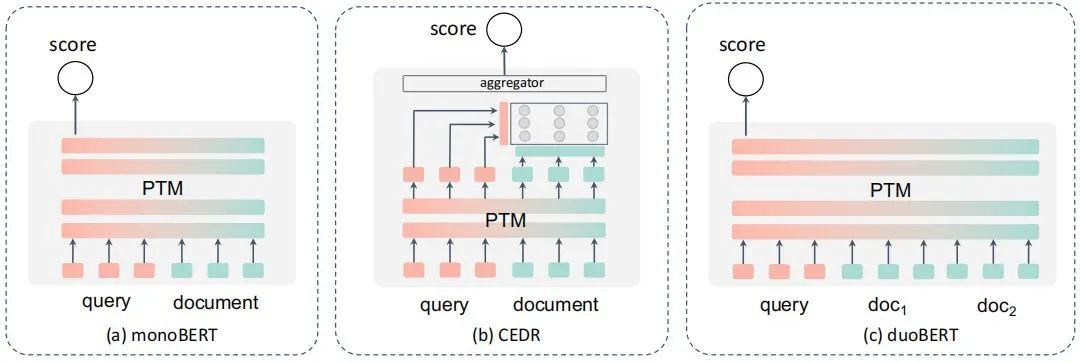
先聊聊前者,这个大家也比较熟悉,说白了就是直接通过分类的方式来计算得分,按照论文的总结,应该就是这几个形式,在NLP里,更多其实可以理解为交互式的语义相似度计算吧,但是由于一对多的存在,所以演化了更多的形式:
而与常规的NLP不同的是,搜索还需要面临这些问题:
长文本问题,虽然query大都还比较短,但是doc很少是短文本了,因此有了一些类似BERT-firstP、BERT-sumP之类选择最优段落等的一些方案和PARADE等的一些用来聚合全文信息再来计算的方案。
性能问题。多个文档和query都要计算匹配度,性能扛不住,所以有了一些类似延迟交互、蒸馏、动态建模的方案。
生成式排序
然后聊聊生成式排序模型,思路上就是这个形式:
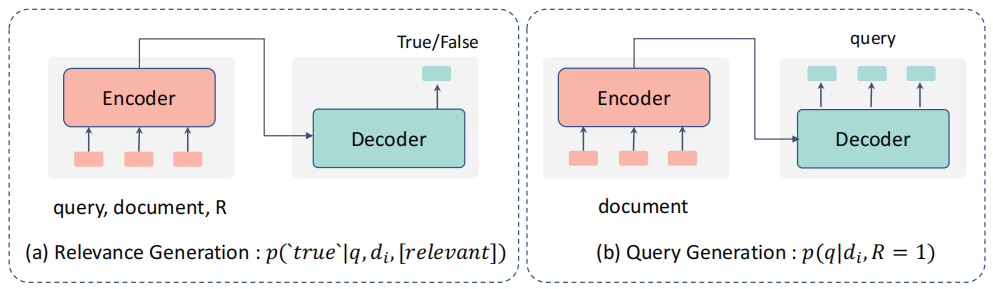
前者是把query和doc都输入文本,生成True/False的结果,个人感觉其实和上面的判别型多少有些类似,只是解释的视角不同吧,后者则是借助Doc生成Query的方式,随后用条件概率来判断两者的相关性。
混合型排序
混合型排序则是混合了上述生成式和判别式方案的特点,例如通过多任务学习等的方案进行,这里不赘述了。
其他检索相关的组件
检索本就是一个系统,内部有大量的组件,而因此,预训练模型也不见得只用在上面的召回和排序阶段,例如query理解,这块我自己是已经用了不少了,例如分类、实体抽取等,当然还有论文里提到的query拓展改写,和其他的特征,这些是query侧的,而物料侧,则有很多类似文本摘要之类的方案,论文里面也有不少,大家可以看看拓展下思路。
检索专用预训练方案
要让预训练方案在特定场景表现更好,肯定离不开对这个场景适配的一些研究,甚至有一些针对对话场景的预训练技术,首先是预训练任务的设计,让预训练模型能更好适配检索任务,例如ICT从论文中随机采样一句话来和剩余句子进行匹配,这些思路的核心其实就是强调预训练模型对query-doc这种信息匹配类任务的理解能力;另一方面,就是一些比较大胆的,对Transformer结构的调整,例如在浅层先隔离q和d之间的关系,后续再来联合的预训练结构,算是一种思路的拓展吧。
自己的一些其他的想法
全文给我的收获其实挺大的,能在论文里看到很多有关预训练模型在搜索中使用的思路和方案,这些也打开了我的思路。但是感觉还有不少问题可能还有待进一步的探索和研究吧,也是自己比较关注和研究的,当然这些也比较实践化,科研视角可能很难关心到。
目前的论文方案似乎都是把整个检索系统割裂来看的,即任务拆解后,逐一优化实现的,小到term-weight问题,达到召回和排序的问题,但是对于一个系统,将预训练模型集成到系统中的时候,有很多问题需要考虑,我举几个例子:
一个系统这么多任务,每个都布一个预训练模型,系统能支撑吗?这时候的性能优化,就不只是优化一个算法一个任务这么简单了,而是一个系统问题。
什么位置上预训练模型对端到端结果收益会更高。
上游计算预训练的中间信息,有没有可能用到下游,产生新的提升,即有没有可能“一肉多吃”。(这个其实论文里有提,具体论文也有看到,感觉是个方向吧)
再者,表面上看这些任务是对应到了检索系统,但是多少还是没有离开预训练所固有的NLP场景,有些搜索的特定特征或者这种信息,并没有考虑引入到模型中,如有点率、点击量等,都没有考虑到融合预训练模型中,说白了,其实还是只是考虑了文档和Query之间语义的相关性而已,没有考虑更多更复杂的信息匹配,而这些信息其实在现实应用中也必不可少,例如“最新消息”之类的query,是和时效性有关的,本身和语义关系真不大,这个例子可能有些极端了,但是在一个相对综合的系统中,确实是个不能忽略的重要问题。
小结
当然了,文章中还有很多内容我没有提到,例如现有数据集和对应的sota,大家可以根据自己的兴趣在论文里看,另外对于自己感兴趣的部分,作者都有列出出处,大家可以进一步深入阅读,很久前就和大家说过读综述的好处就是能快速理解一个方向比较全面的研究现状,也能把握住一些研究热点和前沿,所以非常建议大家精读,我花了一个中秋节假期的事件来看,感觉收获不小,希望也对大家有用吧。
-
大语言模型的预训练2024-07-11 1939
-
预训练模型的基本原理和应用2024-07-03 6076
-
【大语言模型:原理与工程实践】大语言模型的预训练2024-05-07 1572
-
什么是预训练AI模型?2023-05-25 2219
-
什么是预训练 AI 模型?2023-04-04 2719
-
预训练数据大小对于预训练模型的影响2023-03-03 2668
-
利用视觉语言模型对检测器进行预训练2022-08-08 2460
-
如何更高效地使用预训练语言模型2022-07-08 2111
-
一种基于乱序语言模型的预训练模型-PERT2022-05-10 2618
-
Multilingual多语言预训练语言模型的套路2022-05-05 4343
-
如何实现更绿色、经济的NLP预训练模型迁移2022-03-21 3196
-
2021 OPPO开发者大会:NLP预训练大模型2021-10-27 2352
-
小米在预训练模型的探索与优化2020-12-31 4083
-
为什么要使用预训练模型?8种优秀预训练模型大盘点2019-04-04 24686
全部0条评论

快来发表一下你的评论吧 !
