

视觉语言导航领域任务、方法和未来方向的综述
描述
视觉语言导航(VLN)是一个新兴的研究领域,旨在构建一种可以用自然语言与人类交流并在真实的3D环境中导航的具身代理,与计算机视觉、自然语言处理和机器人等研究领域紧密关联。视觉语言导航任务要求构建的具身代理能够根据语言指令推理出导航路径,然而,稀疏的语言指令数据集限制着导航模型的性能,研究者们又提出了一些能够根据导航路径输出接近于人类标注质量的语言指令的模型。
本次DISC小编将分享ACL2022和CVPR2022的三篇论文,第一篇论文是一篇综述,第二篇论文提出了一种监督把控当前导航进程的方法,第三篇文章提出了一套根据导航路径自动生成描述这条路径的语言指令的方法。
文章概览
1.视觉语言导航:任务、方法和未来方向的综述(Vision-and-Language Navigation: A Survey of Tasks, Methods, and Future Directions)
本文从任务、评价指标、方法等方面回顾了当前视觉语言导航研究的进展,并介绍了当前VLN研究的局限性和未来工作的机会。视觉语言导航有很多任务集,难度和任务设定各异,视觉语言导航也涉及许多机器学习相关的模型方法,本文对当前的一些VLN数据集和经典方法作了分类介绍。通过阅读本文,可以对视觉语言导航领域有一个总体的了解。
2.一次一步:拥有里程碑的长视界视觉语言导航(One Step at a Time: Long-Horizon Vision-and-Language Navigation with Milestones)
当面对长视界视觉语言导航任务时,代理很容易忽视部分指令或者困在一个长指令的中间部分。为了解决上述问题,本文设计了一个模型无关的基于里程碑(milestone)的任务跟踪器(milestone-based task tracker,M-TRACK)来指引代理并模拟其进程。任务跟踪器包含里程碑生成器(milestone builder)和里程碑检查器(milestone tracker)。在ALFRED数据集上,本文的M-TRACK方法应用在两个经典模型上分别提升了33%和52%的未知环境中成功率。
3.少即是多:从地标生成对齐的语言指令(Less is More: Generating Grounded Navigation Instructions from Landmarks)
本文研究了从360°室内全景图自动生成导航指令。现存的语言指令生成器往往拥有较差的视觉对齐,这导致了生成指令的过程主要依赖于语言先验和虚幻的物体。本文提出的MARKY-MT5系统利用视线中的地标来解决这个问题,该系统包含地标检测器和指令生成器两个部分。在R2R数据集上,人类寻路员根据人类标注指令寻找导航路径的成功率为75%,而根据MARKY-MT5生成的指令寻找导航路径的成功率仍然有71%,且该指标远高于根据其它生成器生成的指令寻找导航路径的成功率。
动机
近年来,视觉语言导航领域飞速发展,越来越多的导航数据集涌现,针对不同设定的任务数据集,研究者们也设计了许多评测指标,不同的研究社区也在VLN领域提出多种多样的模型方法。本文希望对当前现有的一些任务数据集和VLN方法进行总结分类,为未来VLN研究方向提出一些建议,希望能够为VLN研究社区提供一个详尽的参考。
任务和数据集
导航代理解释自然语言指令的能力使得VLN有别于视觉导航。本文根据交流复杂度和任务目标难度两个维度来对现有的VLN数据集分类,如表1所示。
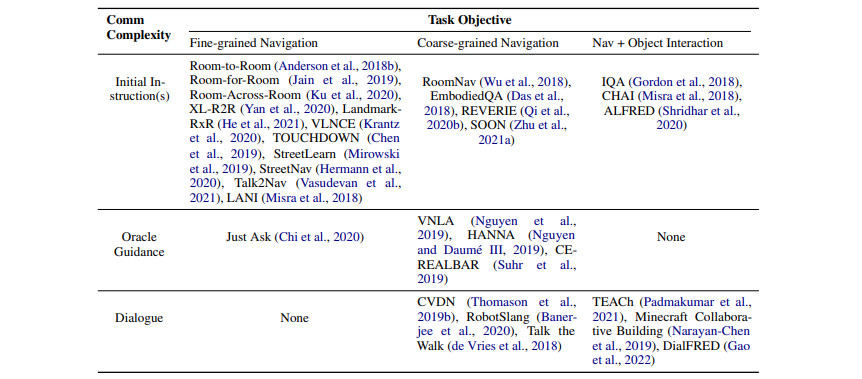
表1:根据交流复杂度和任务目标划分的视觉语言导航基准。
交流复杂度定义了代理与oracle对话的级别,本文划分了三个复杂程度递增的级别:①代理只需要在导航开始前理解一个初始指标;②代理在不确定时可以发送一个信号请求帮助,继而根据oracle的指引完成任务;③拥有对话能力的代理在导航期间可以通过自然语言的形式询问问题并理解oracle的答复。
任务目标定义代理如何根据来自oracle的初始指令实现其目标,本文划分了三个难度递增的级别:①细粒度导航,代理可以根据一条详细的逐步的路径描述来找到目标;②粗粒度导航,代理需要根据一条粗略的路径描述来找到一个距离遥远的目标,代理可能需要得到oracle的一些帮助;③导航和物体交互,代理除了推理出一条行进路径,也需要操作环境中的物体。
评测指标
面向目标的指标主要关注代理和目标的接近程度。其中最自然的指标是成功率(Success Rate),它衡量代理成功完成任务的频率,距离目标一定范围内即算成功。目标进程(Goal Progress)衡量距离目标剩余距离的减少。路径长度(Path Length)衡量导航路径的总长度。最短路径距离(Shortest-Path Distance)衡量代理的最终位置与目标之间的平均距离。路径加权成功率(Success weighted by Path Length)同时考虑成功率和路径长度,因为过长路径的成功导航是不被期望的。Oracle导航误差(Oracle Navigation Error)衡量路径上最接近目标的点到目标的距离。Oracle成功率(Oracle Success Rate)衡量路径上最接近目标的点到目标的距离是否在一个阈值内。
路径精确度的指标评估一个代理在多大程度上遵循期望的路径。有些任务要求代理不仅要找到目标位置,还要遵循特定的路径。精确性的衡量的是专家演示中的动作序列与智能体轨迹中的动作序列之间的匹配程度。长度分数加权的覆盖(Coverage weighted by LS)由路径覆盖(Path Coverage)和长度分数(Length Score)相乘得到,其衡量代理路径和参考路径的接近程度。归一化动态时间规整(Normalized Dynamic Time Warping)惩罚偏离参考路径的偏差,以计算两条路径之间的匹配。归一化动态时间规则加权的成功(Success weighted by normalized Dynamic Time Warping)则进一步将nDTW限制为仅成功的片段,以同时衡量成功和精确度。
VLN方法
如图1所示,本文将现存的VLN方法大致分类为表示学习、动作决策学习、数据中心学习、提前探索等。表示学习主要帮助代理理解多模态的输入(视觉、语言、动作)及其之间的关系。由于导航依赖累积的动作序列,动作决策学习可以帮助代理做出更好的决策。另外,VLN任务的数据集仍然不够大,收集VLN训练数据是昂贵且耗时的。因此,数据中心方法利用现有数据集,创造更多尽可能高质量的训练数据,提升模型表现。提前探索可以帮助代理适应事先未见过的环境,提升代理泛化能力,降低代理在已知环境和未知环境中的表现差距。
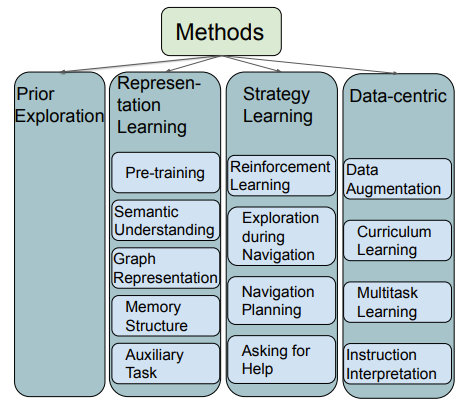
图1:VLN方法分类。各方法间可能有交集。
表示学习
视觉语言预训练模型可以提供好的文本和视觉联合表示,使得代理更好地兼顾理解语言指令和环境观察。研究者也探索专属于VLN领域的预训练,采用VLN领域特定的大规模预训练数据和针对VLN任务设计的特定预训练任务,如PREVALENT、Airbert等。
语义理解可以获取VLN任务中重要特征的知识,同时高层语义表示也能提升代理在未知环境中的表现。语义理解包括模态内和模态间的语义理解。
图表示可以抽取获得语言指令和环境观察中的结构化知识,这为导航提供了显式的语义关系。图可以编码文本和视觉之间的关系,记录导航过程中的位置信息等。
记忆结构可以帮助代理高效地利用逐渐累积的导航历史信息。有些方法利用记忆单元,如LSTM、循环的信息状态等;有些方法建立一个独立的记忆模型来存储相关信息。
辅助任务在不需要额外标签的情况下帮助代理更好地理解环境和其自身所处的状态,这往往需要引进额外的损失函数。一般的辅助任务有解释其先前的动作、预测未来决策的信息、预测当前任务的完成状态和视觉文本的匹配程度等。
动作决策学习
VLN是一个动作序列决策问题并且可以被建模成一个马尔科夫决策过程。所以强化学习方法可以使代理学得更好的策略。一个应用强化学习的难点在于很难知道一个动作对最终任务完成的贡献程度,因此无法决定奖励或惩罚。对此,人们提出了RCM模型和利用指令和关键地标之间的局部对齐作为奖励等方法。
边导航边探索可以使代理对状态空间有一个更好的了解。探索和开发之间存在一个权衡,随着更多的探索,代理以更长的路径和更长的导航时间为代价获得了更好的表现,因此代理需要决定探索的时间和深度。
导航规划会带来更好的行动策略,从视觉角度来看,预测路径点、下一个状态和奖励、生成未来的观察结果和整合邻居视图都已经被证明是有效的。
代理在不确定下一个动作时可以询问帮助,可以利用动作概率分布或者独立训练的模型来决定是否询问,询问方式可以是发送一个信号或者使用自然语言。
数据中心学习
VLN领域的数据增强主要包含路径指令对增强和环境增强。扩增的路径指令对可以直接作为额外的训练样本。生成更多的环境数据不仅帮助扩增路径样本,还可以避免在已知环境中的过拟合问题,生成额外环境数据一般采用随机遮盖不同视点的相同视觉特征。
课程学习的大致思想是在训练过程中逐渐增大任务的难度,即先用低难度的样本训练代理。
多任务学习引入不同的VLN任务进行训练,促进跨任务知识转移。
对一条语言指令进行多次不同的指令解释可以使代理更好地理解其目标。
提前探索
提前探索方法允许代理去观察和适应未知环境,从而缩小已知和未知环境中的表现差距。一些经典方法有利用测试环境来取样和扩增路径样本来适应未知环境、利用图结构来提前建立未知环境的信息概况等。
未来方向
鉴于现在的任务设定在环境中都只有一个代理,未来可以关注多代理协作的视觉语言导航任务;其次,希望未来的任务研究更贴合现实情况,比如环境中可能会有人类在改变环境的状态,而不是只有导航代理的存在;另外,希望视觉语言导航任务的研究能关注到数据隐私和道德的问题;最后,由于当前的训练数据集基本来自于欧美国家,训练多文化的代理也是重要的。

动机
近些年,许多VLN模型取得了巨大的成功,尤其是在短视界(short-horizon)问题上。但当面对到拥有很长动作序列的长视界(long-horizon)问题时,许多模型的表现仍然让人不够满意。具体来说,本文作者观察到在一些实验中,代理会跳过部分子任务不做或者在一个已完成的子任务内原地徘徊而无法去执行下一个子任务,这些都说明代理在处理长序列任务时,缺乏对其所处进程的认识。本文尝试构建里程碑(milestone)来模拟任务进程进度,设计了任务跟踪器M-TRACK。
M-TRACK方法
本文设计任务跟踪器(M-TRACK),它在子任务中跟踪任务进度,只有代理达到一个子任务的里程碑时才能进入下一个子任务。M-TRACK包含里程碑生成器(milestone builder)和里程碑检查器(milestone checker)。里程碑生成器将指令划分为导航(Navigation)里程碑和交互(Interaction)里程碑,代理需要一步步完成这些里程碑。里程碑检查器系统地检查代理在当前里程碑中的进度,并确定何时继续到下一个里程碑。
下图展示了一个ALFRED任务,其由一个整体目标和六个子任务组成。每张图中的蓝色/红色文本框就是该方法从各子任务中抽取出的导航/交互里程碑。一个代理在处理下一个子任务之前需要达到当前所处子任务的里程碑条件。

图2:M-TRACK方法的示意。
对于长视界(long-horizon)VLN任务,代理往往需要按照一个特定的顺序完成多个子任务从而完成一个完整任务。更具体地,完整任务的语言指令中的每一句指令可以视作一个子任务的语言指令。
里程碑生成器(milestone builder)使用命名实体识别技术为每一个子任务从其语言指令中提取出里程碑作为指导。里程碑由一个形如的元组表示。举个例子,对于指令"Turn to the left and face the toilet",里程碑生成器将输出标签,而对于指令"Pick the soap up from the back of the toilet",里程碑生成器将输出标签。如果一个子任务拥有多个要求交互的物体,生成器输出的标签需要包含所有。本文采用BERT-CRF模型实现里程碑生成器,并用ALFRED模拟器的元数据组成训练数据。
里程碑检查器(milestone checker)确认代理是否达到一个里程碑。一个导航里程碑的达成条件是目标物体在视野内且代理可以触碰到,一个交互里程碑的达成条件是目标物体在代理可以触碰到的视野内并且代理完成了与该目标物体的交互。
另外,M-TRACK方法在代理执行预测动作前,主动应用里程碑检查器进行检查。这可以避免代理与一个错误的物体交互后进行额外的纠正错误步骤。
如图3所示,里程碑检查器在每一步动作执行完毕后检查当前里程碑是否达成,一旦达成则向代理输入下一个子任务的语言指令;同时,检查器在交互动作执行之前,确认交互物体目标是否为交互里程碑中涉及的物体目标,若不是则不执行动作并挑选下一个概率最高的动作执行。
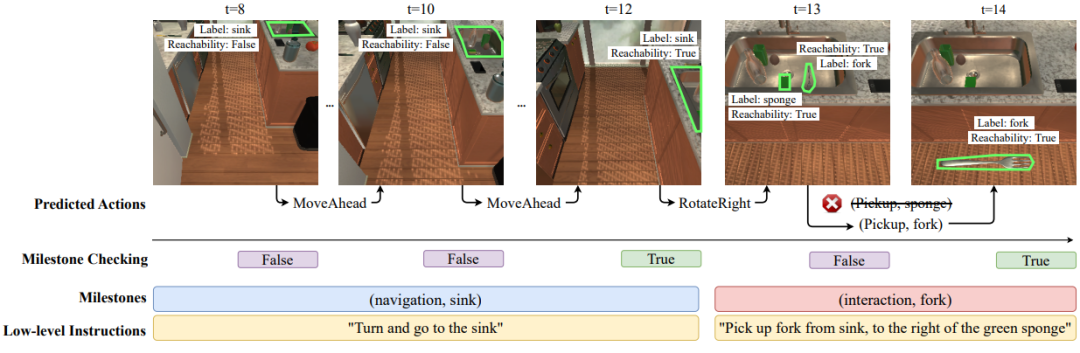
图3:里程碑检查过程的示意图。
值得一提的是,M-TRACK方法只需要用到语言指令、视觉输入和代理动作,因此该方法是与模型无关的,即可以应用到任何VLN模型上。
实验结果
本文在ALFRED数据集上验证M-TRACK方法。ALFRED数据集收集了8055条完成家务任务的专家路径,其带有25743条标注的语言指令。验证集和测试集会被进一步划分为1)在训练过程中能看到的环境Seen和2)新的环境Unseen。
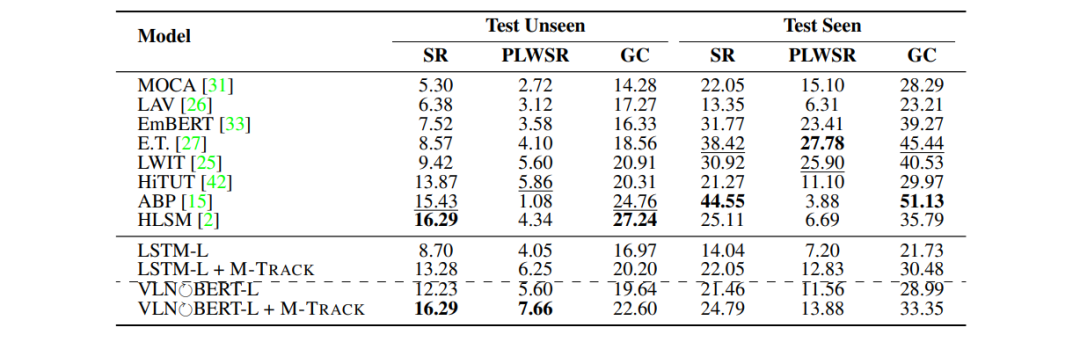
表2:ALFRED测试集上的表现。
如表2所示,M-TRACK方法分别应用在LSTM模型和VLN-BERT模型上后,均显著提高了两模型的各指标表现,使得两模型的性能优于其它大多数模型。另外,使用M-TRACK方法的VLN-BERT模型在Unseen环境中的SR和PLWSR指标上达到了最好表现。

动机
训练数据稀疏一直是视觉语言导航领域的一个问题,研究自动生成高质量的语言指令的模型方法十分重要。自动生成语言指令的一个经典模型是Speaker-Follower模型,但其表现仍然不够令人满意。本文观察到人类标注员在写语言指令时仅参考了一小部分他们看到的物体,这使得学习视觉输入和文本输出之间的精确映射变得更加困难。换一句话说,输入中涉及过多的视觉信息可能反而导致更差的性能,因为模型会学到很多虚假的相关性。另外,本文还注意到地标说明是语言指令中的重要组成部分。综上,本文提出了一套仅利用地标和动作序列等较少信息就生成语言指令的流程方法。
制作地标数据集
MARKY-MT5第一阶段识别视觉地标作为第二阶段指令生成器的输入,这需要一个地标识别器,而地标识别器的训练需要制作地标数据集,如图4所示。

图4:从RxR数据集制作的地标数据集。
第一步是从语言指令中抽取地标词组,如图5所示。第二步是将地标词组匹配到对应的视觉图像,对于一条语言指令为了匹配地标词组和图像序列,建模矩阵,其中表示词组和图像的匹配度。
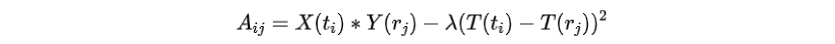
其中计算MURAL文本表征,计算MURAL图像表征,返回时间戳。第三步是将图像中的地标居中,以更好地与地标词组对齐。

图5:地标数据集制作过程。
地标检测
本文采用CenterNet模型作为地标检测器,输入形式为360°全景图的序列,同时每个全景图上标注了入口和出口方向,如图6所示,输出即为检测出的系列地标。
在训练时,使用之前从RxR数据集制作的地标数据集。在推理时,聚集每一个视点全景图的分数最高的3个地标,最终返回T个分数最高的地标,T为路径长度。
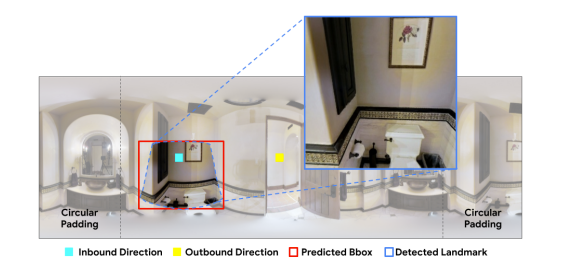
图6:地标检测器的全景输入形式。
指令生成
本文通过将选定地标的视觉表示插入到一个模板式的英文文本序列中,以描述每个地标的方向和穿越路线所需的动作,从而形成模型的输入。如图7所示,对于每张有检测出地标的视点全景图,用地标方向和当前视点采用的前进方向,配合地标和当前视点的出口视图,交织成一句语言指令,以此类推,直至描述完所有符合要求的视点全景图。
本文采用的指令生成模型基于mT5模型,这是T5模型的多语言变体。
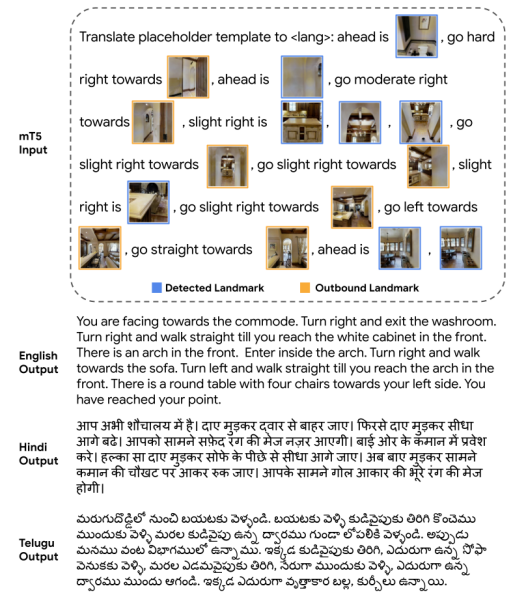
图7:输入模板和指令生成器的多语言输出。
实验结果
MARKY-MT5模型在RxR数据集上训练,分别在RxR和R2R数据集上评测。评测方法是让人类去分别根据人类标注和模型生成的语言指令,在虚拟环境中操作完成导航,完成导航的成功率越高,说明语言指令的质量越高。

表3:人类寻路员在R2R未知验证集上的表现。

表4:人类寻路员在RxR未知验证集上的表现。
综上, 可以发现在较简单的R2R数据集上,MARKY-MT5系统的表现十分接近于人类标注的语言指令,同时又远高于其它系统模型生成的语言指令质量。而在较复杂的RxR数据集上,MARKY-MT5模型和人类标注的语言指令质量存在一定的差距。
总结
本次 Fudan DISC 小编分享的三篇论文从不同的角度研究了视觉语言导航领域。第一篇工作主要是综述前人的工作,希望对视觉语言导航的目前进展做出一个归纳整理,无论是对刚入门的人,还是对在这个领域略有心得的人,都是一个不错的参考启发资料。第二篇工作主要是意识到了导航代理在把握任务进程方面的难处,并提出了一种可行的进程监督方式。第三篇工作在语言指令生成方面做出了突破性进展,通过精简视觉输入的信息,仅利用关键性地标和方向动作来生成语言指令,实验结果达到了SOTA结果。
-
一种在视觉语言导航任务中提出的新方法,来探索未知环境2019-03-05 5463
-
【大语言模型:原理与工程实践】核心技术综述2024-05-05 1182
-
学习C语言未来的发展方向是怎样的?2021-11-11 3178
-
桥接视觉与语言的研究综述2019-08-09 3584
-
自然语言处理是人工智能领域中的一个重要方向2020-12-17 5405
-
视觉问答与对话任务研究综述2021-04-08 1225
-
基于视觉/惯导的无人机组合导航算法综述2021-06-23 1117
-
ACL2021的跨视觉语言模态论文之跨视觉语言模态任务与方法2021-10-13 3613
-
利用视觉+语言数据增强视觉特征2023-02-13 1851
-
多维度剖析视觉-语言训练的技术路线2023-02-23 2235
-
小样本学习领域的未来发展方向2023-06-14 2066
-
ICCV 2023 | 面向视觉-语言导航的实体-标志物对齐自适应预训练方法2023-10-23 2330
-
基于视觉语言模型的导航框架VLMnav2024-11-22 1886
-
Aux-Think打破视觉语言导航任务的常规推理范式2025-07-08 826
-
面向视觉语言导航的任务驱动式地图学习框架MapDream介绍2026-03-02 748
全部0条评论

快来发表一下你的评论吧 !
