

如何通过多模态对比学习增强句子特征学习
描述
论文:MCSE: Multimodal Contrastive Learning of Sentence Embeddings
链接:https://aclanthology.org/2022.naacl-main.436.pdf
代码:https://github.com/uds-lsv/MCSE

视觉作为人类感知体验的核心部分,已被证明在建立语言模型和提高各种NLP任务的性能方面是有效的。作者认为视觉作为辅助语义信息可以进一步促进句子表征学习。在这篇论文中,为了同时利用视觉信息和文本信息,作者采用了sota句子嵌入框架SimCSE,并将其扩展为多模态对比目标。作者发现,除了文本语料库之外,使用少量多模态数据可以显著提高STS任务的性能。在论文的最后,作者也对该方法所存在的局限性进行了分析
虽然这篇论文的框架非常简单,但是我觉得对于实验和作者的局限性分析还是有值得思考的地方
方法
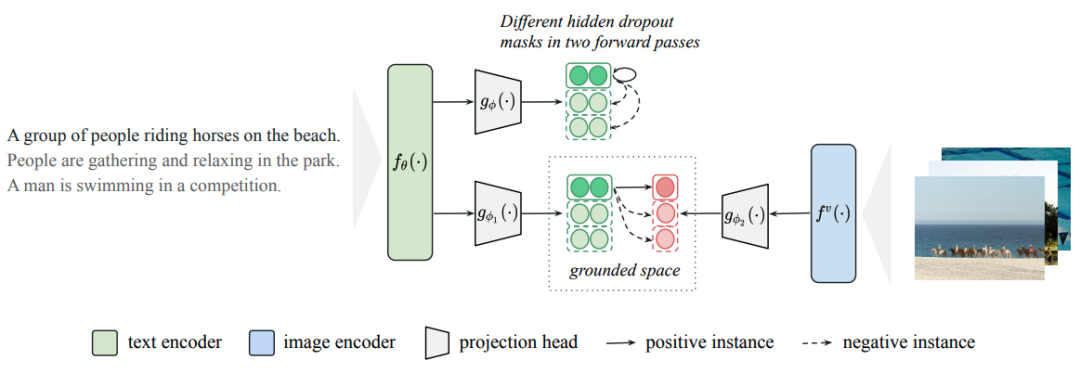
MCSE模型
SimCSE:
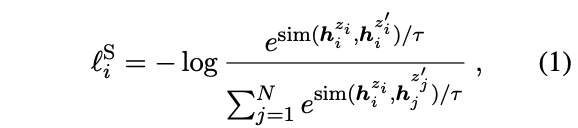
就是通过dropout+编码两次构建正样本对,进行对比学习
给定一个图像句子对,把他们映射到一个共同的嵌入空间中
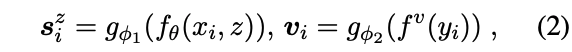
f()为预训练的语言编码器和预训练的图像编码器,g()为映射头
接下来就是多模态对比学习:
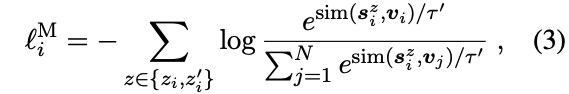
最终的损失函数为 SimCSE的损失+多模态对比损失:
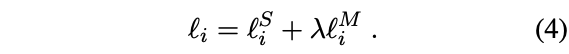
Experiments
作者使用Flickr30k(包含29, 783个训练图像)和MS-COCO(包含82, 783个训练图像)作为多模态数据集,使用Wiki1M(个句子)作为文本语料库
SimCSE和MCSE的差别就是,MCSE利用了图像-句子对,引入了多模态对比损失。即使多模态数据量相对较小,可获得辅助视觉信息的MCSE模型也能进一步取得显著的改进。在STS16上,Bert+MCSE的性能较差,作者解释为域差异,其中一些接近训练分布的子集比其他子集更能从视觉基础中获益。
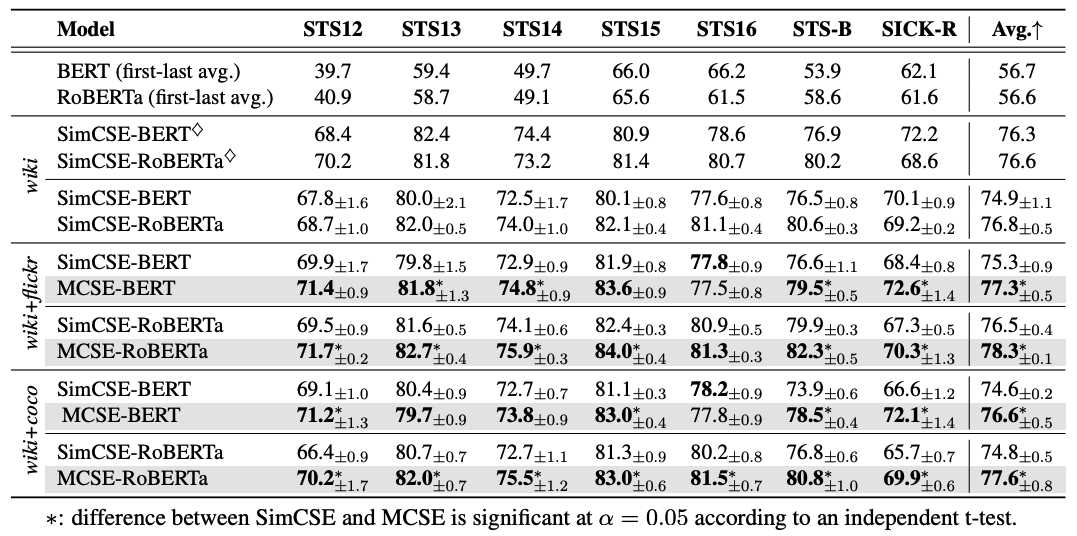
表1
为了进一步研究不同数据集的影响,作者只在多模态数据上训练模型,并在表2中报告结果。我们观察到,在没有大型纯文本语料库的情况下,性能比表1中的结果下降了很多,但是依然可以超过SimCSE。此外,作者将成对的图像替换为打乱的图像进行训练,模型下降了0.8-5.0个点,进一步验证了视觉语义的有效性。
这点其实我不太理解,是将图像句子对的匹配关系给打乱了么,如果是这样的话,感觉好像没什么意义呀
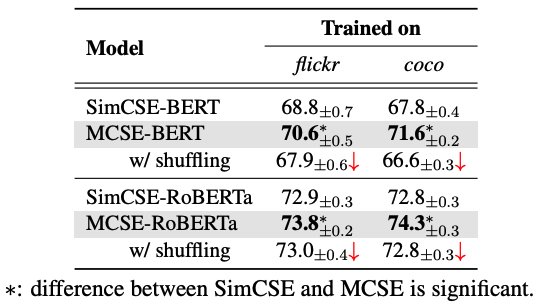
表2
作者使用bert-base model只在多模态数据上进行了训练,来研究数据规模大小对性能的影响,在数量有限的样本上,SimCSE取得了更好的性能,随着数据量的增加,MCSE的性能更好,作者推测,这一现象可以归因于多模态映射投权重的渐进训练。
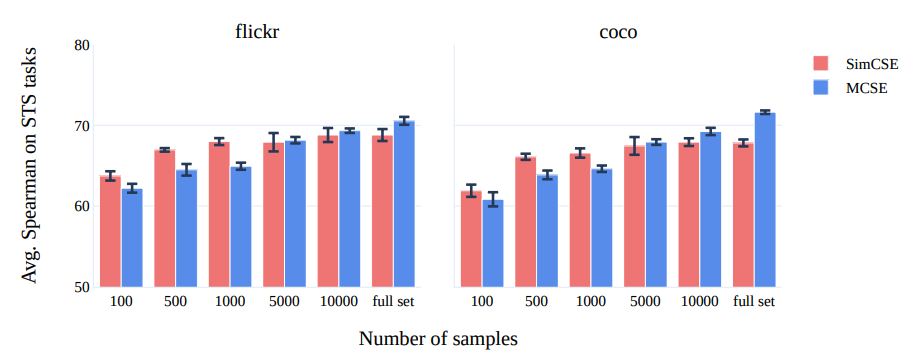
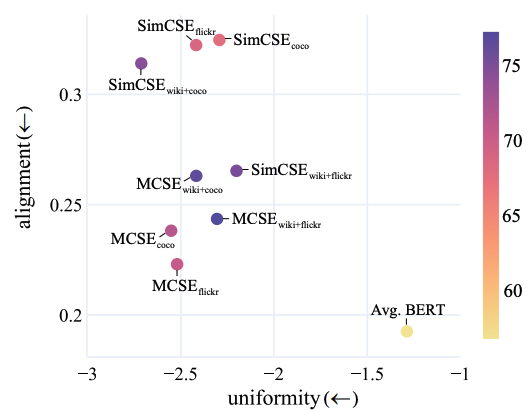
作者报告了alignment and uniformity两个量化指标,结果表明,与SimCSE模型相比,MCSE模型在保持一致性的同时获得了更好的对齐得分。这一分析进一步支持了视觉基础可以通过改善文本嵌入空间的对齐特性来增强句子特征学习。
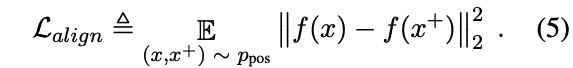
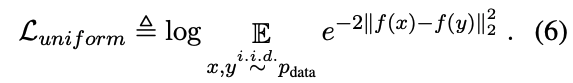
Limitations
作者还指出了该方法所存在的局限性,多模态数据收集标注困难,如果可以合理的利用噪声图像-句子对,或者摆脱显式的图像文本对齐关系,将会有很大的实用价值。此外,我们发现只有来自相关领域的子集可以获得显著的改进,而其他子集则受到域偏移的影响。对于学习通用的句子嵌入来说,减小域偏移是至关重要的。此外,“语义相似度”的定义是高度任务依赖的。除了STS基准之外,值得探讨的是纯文本模型和多模态模型在其他基准上的性能差距,这些基准也可以评估句子特征的质量。
编辑:黄飞
- 相关推荐
- 热点推荐
- nlp
-
适用于任意数据模态的自监督学习数据增强技术2023-09-04 2016
-
《多模态大模型 前沿算法与实战应用 第一季》精品课程简介2026-05-01 186
-
基于增强学习算法的PID参数调整方法研究2009-08-07 1111
-
通过对比深度学习各大框架的优缺点寻找最优2017-11-15 23421
-
基于多模态特征数据的多标记迁移学习方法的早期阿尔茨海默病诊断2017-12-14 1049
-
多文化场景下的多模态情感识别2017-12-18 1278
-
基于语义耦合相关的判别式跨模态哈希特征表示学习算法2021-03-31 1021
-
可提高跨模态行人重识别算法精度的特征学习框架2021-05-10 1077
-
特征选择和机器学习的软件缺陷跟踪系统对比2021-06-10 817
-
基于耦合字典学习与图像正则化的跨模态检索2021-06-27 902
-
对比学习的关键技术和基本应用分析2022-03-09 6171
-
结合句子间差异的无监督句子嵌入对比学习方法-DiffCSE2022-05-05 2150
-
通过对比学习的角度来解决细粒度分类的特征质量问题2022-05-13 4064
-
CMU最新《多模态机器学习的基础和最新趋势》综述2022-12-07 2178
-
通过强化学习策略进行特征选择2024-06-05 1308
全部0条评论

快来发表一下你的评论吧 !
