

基于DCNN图像的深度卷积神经网络模型分类
人工智能
描述
重磅干货,第一时间送达
图像分类是计算机视觉基本任务之一。顾名思义,图像分类即给定一幅图像,计算机利用算法找出其所属的类别标签。
图像分类的过程主要包括图像的预处理、图像的特征提取以及使用分类器对图像进行分类,其中图像的特征提取是至关重要的一步。
深度学习作为机器学习的一个分支,将数据的底层特征组合成抽象的高层特征,其在计算机视觉、自然语言处理等人工智能领域发挥了不可替代的作用。
深度卷积神经网络模型
本文根据近年来基于DCNN的图像分类研究发展过程和方向,将深度卷积神经网络模型分为以下4类:
经典的深度卷积神经网络:增加网络深度,提升网络性能为目标;
基于注意力机制的深度卷积神经网络模型:采用注意力机制使网络模型更关注感兴趣的区域;
轻量级深度卷积神经网络模型:过改进模型结构降低网络参 数量以适应嵌入式、移动式设备的需求;
基于神经架构搜索的网络模型:采用神经网络自动设计DCNN 模型结构,与人工设计DCNN相比更省时省力;
经典的深度卷积神经网络模型
从 LeNet 到 GoogLeNet
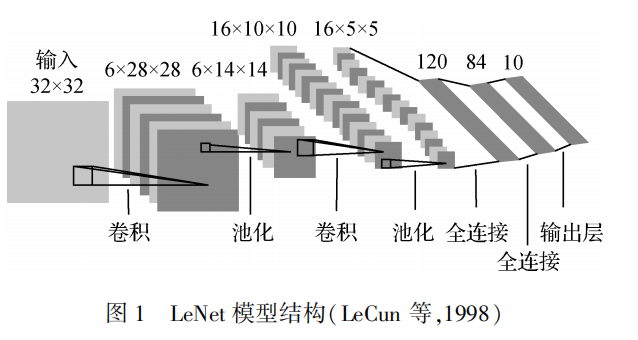
LeNet模型(LeCun 等,1998)是最早提出的卷积神经网络模型,主要用于MNIST数据集中手写数字识别。LeNet包含3个卷积层、2个池化层和2个全连接层,每个卷积层和全连接层均有可训练的参数,为深度卷积神经网络的发展奠定了基础。
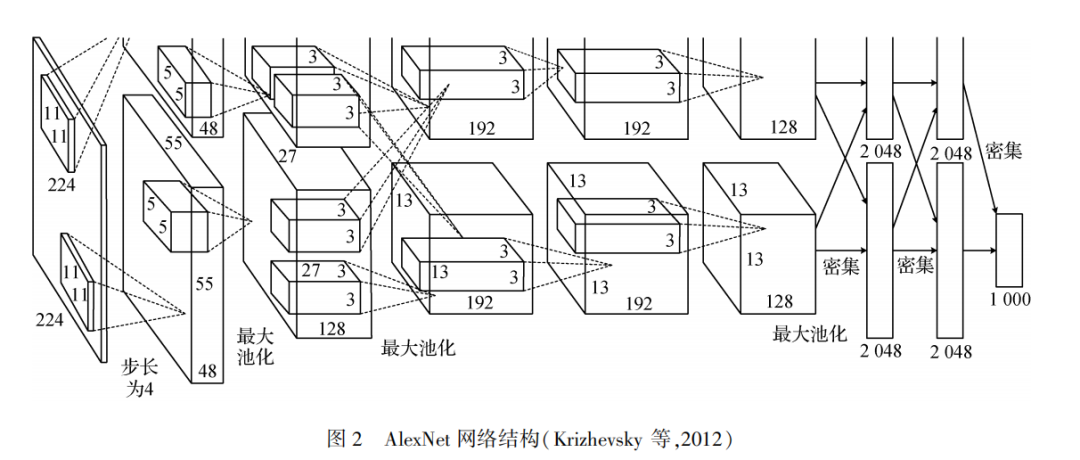
AlexNet网络包含5个卷积层和3个全连接层,输入图像经过卷积操作和全连接层的操作,最后输入具有1000个节点的Softmax分类器完成图像分类。该网络通过使用ReLU作为激活函数,引入局部响应归一化缓解梯度消失问题,使用数据增强和Dropout技术大大缓解了过拟合问题。
提升网络性能最直接的方法是增加网络深度,但随着网络深度的增加,参数量加大,网络更易产生过拟合,同时对计算资源的需求也显著增加。
GoogLeNet采用了Inception-v1模块,该模块采用稀疏连接降低模型参数量的同时,保证了计算资源的使用效率,在深度达到22层的情况下提升了网络的性能。Inception-v1包含4条并行的支路,3×3卷积、5×5卷积之前的1×1卷积和3×3最大池化之后的1×1卷积用来减少参数量。
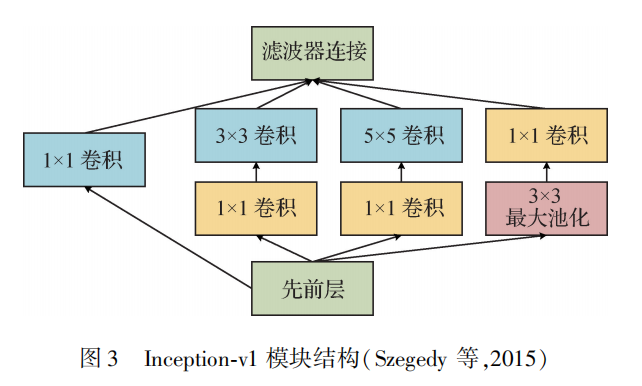
Inception-v2增加了BN层,将5×5卷积分解成两个3×3卷积,从而减少了参数量。Inception-v3在Inception-v2模块基础上进行非对称卷积分解,如将n×n大小的卷积分解成1×n卷积和n×1卷积的串联,且n越大,参数量减少得越多。
ResNet 家族
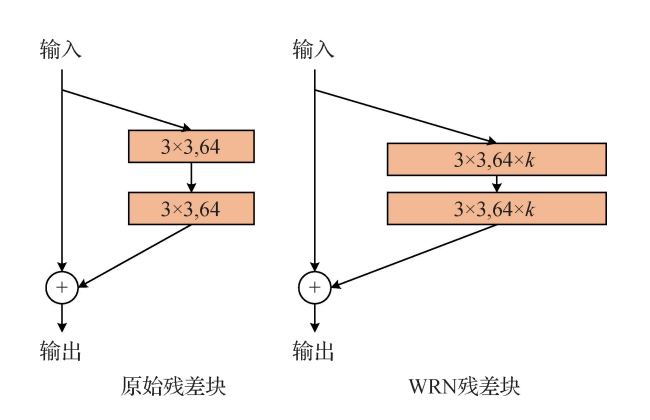
ResNet由堆叠的残差块组成,残差块结构如图所示,残差块除了包含权重层,还通过越层连接将输入x直接连到输出上。
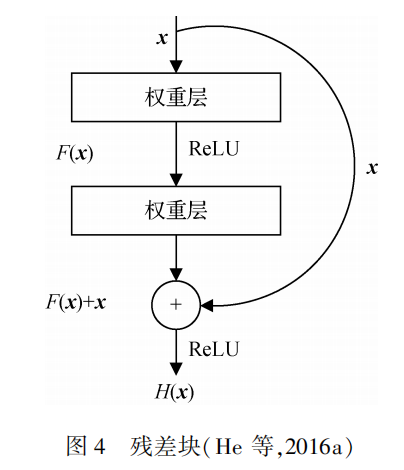
ResNet通过堆叠残差块使网络深度达到152层,残差网络在图像分类任务中获得了较大的成功。ResNet变体可分为4类:
深度残差网络优化
采用新的训练方法
基于增加宽度的变体
采用新维度的变体
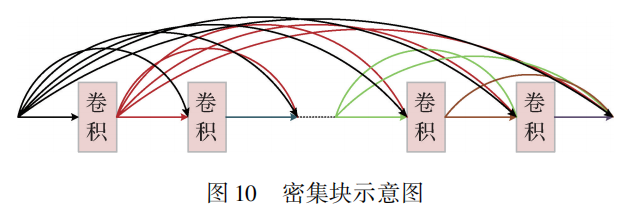
DenseNet 家族
DenseNet由密集块组成,密集块结构如图所示,密集块采用前馈的方式将所有层。DenseNet每一层都从其前部所有层获得输入并将自己的输出特征图传递到后部层,这种方式增强了特征重用。
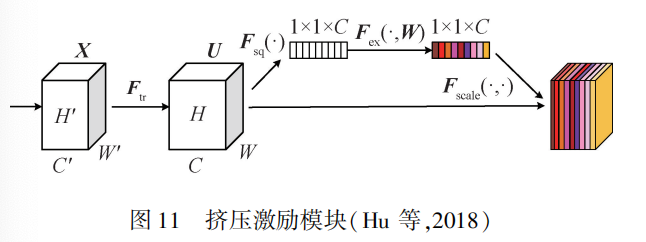
使用注意力机制的网络
人眼观看一幅图像,首先看全局,然后将注意力集中在某个细节,将注意力集中在有价值的部分,忽略价值不大的部分。
SEblock通过显式地建模通道之间的相互依赖性来重新校准通道的特征响应,即选择性地增强有用的通道特征,抑制无用的通道特征。
CBAM模块包括通道注意力模块和空间注意力模块两部分,输入特征图首先输入通道注意力模块,分别使用平均池化和最大池化聚集空间信息生成两个空间内容描述符,随后两个空间内容描述符通过一个共享网络生成通道注意力图。
轻量级网络
轻量级网络是参数量小、计算复杂度低的网络。典型的轻量级网络有SqueezeNet、Xception、MobileNet系列和ShuffleNet系列等。
SqueezeNet网络由fire module组成,分为挤压卷积层和扩展卷积层两部分,前者仅包含1×1卷积,后者包含1×1卷积和3×3卷积操作。
MobileNetV1网络使用了深度可分离卷积,除此之外,还提出了两个超参数———宽度乘数α和决议乘数ρ,使得其可根据应用的不同选择不同的模型大小。
架构搜索的网络模型
NAS方法可分为3类:
基于设计不同搜索空间的NAS方法
基于模型优化的NAS方法
其他改进的NAS方法
图像分类数据集
MNIST数据集
MNIST数据集用来识别手写数字,从NIST数据集的SD-1和SD-3构建的,其中包含手写数字的二进制图像。

NIST数据集将SD-3作为训练集,将SD-1作为测试集,但SD-3比SD-1更易识别,原因在于SD-3来源于人口调查局雇员,SD-1来源于高中生。在LeNet-5实验中,训练集为完整的新训练集,共60000幅图像,测试集为新测试集的子集,共10000幅图像。
ImageNet数据集
ImageNet数据集是具有超过1500万幅带标签的高分辨率图像的数据集,这些图像大约属于22000个类别,这些图像从互联网收集并由人工使用亚马逊的机械土耳其众包工具贴上标签。
深度卷积神经网络模型在ImageNet数据集上进行训练和测试,衡量模型优劣的指标为top-5错误率和top-1错误率。ImageNet通常有1000个类别,训练和测试时,对每幅图像同时预测5个标签类别,若预测的5个类别任意之一为该图像的正确标签。
CIFAR数据集
CIFAR-10数据集有60000幅彩色图像,分辨率大小为32×32像素,共10个类别,每个类别包含6000幅图像。训练集包含50000幅彩色图像,测试集包含10000幅彩色图像。测试集的图像取自10个类别,每个类别分别取1000幅,剩余的图像构成训练集。

CIFAR-100数据集与CIFAR-10数据集类似,不同的是CIFAR-100数据集有100个类别,每个类别包含600幅图像,每个类别有500幅训练图像和100幅测试图像。
SVHN数据集
SVHN数据集用来检测和识别街景图像中的门牌号,从大量街景图像的剪裁门牌号图像中收集,包含超过600000幅小图像,这些图像以两种格式呈现:一种是完整的数字,即原始的、分辨率可变的、彩色的门牌号图像,每个图像包括检测到的数字的转录以及字符级边界框。一种是剪裁数字,图像尺寸被调整为固定的32×32像素。
SVHN数据集分为3个子集,73257幅图像用于训练,26032幅图像用于测试,531131幅难度稍小的图像作为额外的训练数据。
编辑:黄飞
-
卷积神经网络训练的是什么2024-07-03 2004
-
卷积神经网络模型有哪些?卷积神经网络包括哪几层内容?2023-08-21 3192
-
卷积神经网络模型发展及应用2022-08-02 13391
-
基于多孔卷积神经网络的图像深度估计模型2020-09-29 1270
-
基于卷积神经网络的图像标注模型2017-12-07 1549
全部0条评论

快来发表一下你的评论吧 !
