

请问一下怎样去使用HLS创建IP呢
描述
目前我们已经单独使用 HLS 创建了IP(见上一节)。在本实践中,我们将实际实现 HLS 组件作为 FPGA 设计的一部分。首先我们将学习如何做到这一点,然后我们将创建硬件来解决一些实际问题。
首先使用上一节的文件创建一个新的 HLS 项目:
重新综合一下
每次我们更改硬件时,我们都需要告诉 HLS 将其导出为硬件描述语言并生成 Vivado 需要的所有各种源数据。
选择Solution → Export RTL → 选择 "Vivado IP for System Generator" → 单击确定
接下来我们需要告诉 Vivado 我们的新 IP 在哪里
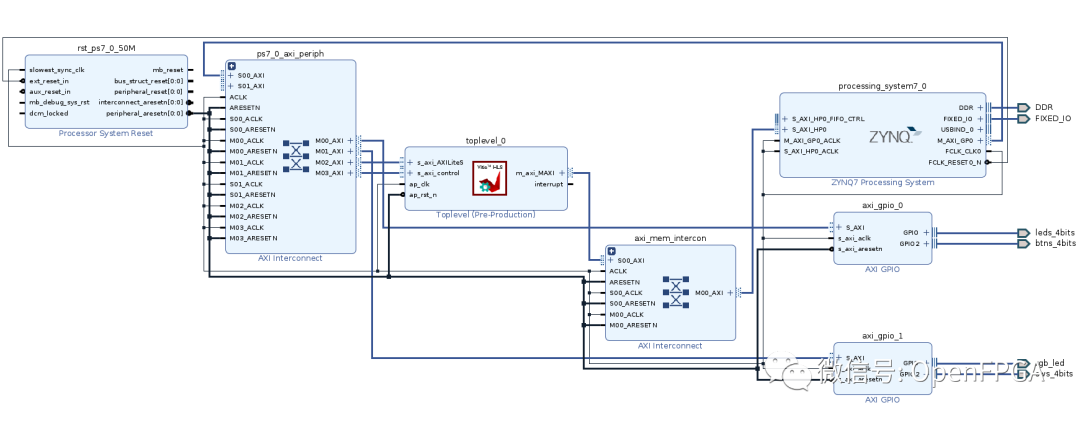
回到 Vivado,打开 Block Design。单击Window -> IP Catalog以打开 IP 目录。单击左侧 Flow Navigator 中的设置。选择 IP,然后选择存储库。按加号图标。从文件浏览器中选择 HLS 项目目录,然后单击选择。Vivado 将扫描 HLS 项目,并弹出一个框,显示 IP 已添加到项目中。单击确定。
回到 Block Design,单击图表左侧的 Add IP 按钮。IP 核将被称为之前创建IP时输入的显示名称,或者 Toplevel 。双击 IP 进行添加。
要允许 IP 内核访问 DDR 存储器,需要在 Zynq 处理系统上启用 AXI 从接口。双击 Zynq IP ,选择“PS-PL Configuration”,展开“HP Slave AXI Interface”,勾选 S AXI HP0 interface. 单击确定,应该会看到 Zynq 模块上出现一个新端口。
现在可以使用连接自动化来完成连接。运行连接自动化并检查 S_AXI_HP0. 应该建议连接到 m_axi IP 核上的端口。
同样在连接自动化检查 s_axi_AXILiteS和s_axi_control. 应该连接到M_AXI_GP0 处理系统上。单击确定。
现在,IP将通过其从接口连接到processing_system7_0_AXI_periph,并通过其主接口连接到AXI_mem_intercon。
现在可以保存模块设计、生成比特流并再次导出硬件。覆盖现有的硬件规范(XSA 文件)。
连接自动化问题
如果对使用连接自动化生成的 AXI 总线有问题(即,如果它们与上述结构不同),请尝试删除所有AXI 互连模块并再次运行它。
一般原则是, Zynq 模块的 M_AXI 应该可追溯至 IP 内核上的所有 S_AXI,而 IP 内核的 M_AXI 应可追溯至 Zynq 模块上的 S_AXI_HP0。
在 Vitis 中使用 IP
当 HLS 导出我们的 IP 时,它帮助我们自动生成了一个软件驱动程序。但是我们需要告诉 Vitis 在哪里可以找到这个驱动程序。
在 Vitis 中,选择 Xilinx → Repositories。在 Local Repositories 下,单击 New 并选择 HLS 项目的文件夹。单击重新扫描存储库,然后单击确定。
右键单击design_1_wrapper 平台并单击“Update Hardware Specification”以更新我们已更改硬件的问题。
我们现在应该能够看到新 IP 及其驱动程序。
在 Board Support Package 设置下的platform.spr 文件中,应该能够看到列出的 IP,以及它使用驱动程序.
现在可以与IP进行交互了,如下例所示。
#include#include "platform.h" #include "xil_printf.h" #include "xparameters.h" #include "xtoplevel.h" #include "xil_cache.h" u32 shared[1000]; int main() { int i; XToplevel hls; init_platform(); Xil_DCacheDisable(); print(" HLS test "); for(i = 0; i < 100; i++) { shared[i] = i; } shared[0] = 8000; XToplevel_Initialize(&hls, XPAR_TOPLEVEL_0_DEVICE_ID); XToplevel_Set_ram(&hls, (u32) shared); XToplevel_Start(&hls); while(!XToplevel_IsDone(&hls)); printf("arg2 = %lu arg3 = %lu ", XToplevel_Get_arg2(&hls), XToplevel_Get_arg3(&hls)); cleanup_platform(); return 0; }
对 FPGA 进行编程并启动此代码,应该会看到以下内容:
HLS test arg2 = 12950 arg3 = 3050
如您所见,目前组件可以使用XToplevel_Start启动,xtopleevel_IsDone会告诉你何时完成。XToplevel_Set_ram告诉HLS组件共享内存在主内存中的位置。允许HLS读写,就像RAM从0开始一样,但实际上它将指向我们的共享内存。不要忘记设置RAM偏移量,否则HLS组件将写入随机内存位!
当更改 HLS 时
当更改 HLS 代码时,请执行以下步骤以确保的最终文件已更新。
重新运行综合。
重新导出 IP 核。
在 Vivado 中,应该已经识别到了变化,并且会出现一条消息说“IP Catalog is out-of-date”。
如果没有,请单击 IP Status,然后单击重新运行报告
单击刷新 IP 目录
在“Generate Output Products”对话框中,单击“Generate”。
单击生成比特流。
导出硬件(包括比特流)。
在 Vitis 中重新编程 FPGA 并运行软件。
如果更改了硬件接口,可能需要重新生成系统并将应用程序项目移入其中。
测量执行时间
下面将举例使用 ARM 处理系统中的计时器来测量执行一段代码需要多长时间,然后演示可以在硬件中更快地执行相同的操作。我们要测量的代码实现了对Collatz(柯拉兹) 猜想的测试。该猜想指出:
柯拉兹猜想
取任何 正整数n(其中n不为0)。如果 n 是偶数,则除以 2 得到 n / 2。如果 n 是奇数,则将其乘以 3 并加 1 得到 3 n + 1。无限重复该过程。猜想是,无论你从哪个数字开始,你最终总会达到 1。
创建一个 HLS 组件来测试前 1000 个整数,以验证如果执行上述步骤,它们最终都会收敛到 1。将在共享数组中输出每个数字达到 1 所需的步数。
下面的代码是使用的ARM软件:
#include#include "platform.h" #include "xil_printf.h" #include "xparameters.h" #include "xtoplevel.h" #include "xil_cache.h" int shared[1000]; XToplevel hls; unsigned int collatz(unsigned int n) { int count = 0; while(n != 1) { if(n % 2 == 0) { n /= 2; } else { n = (3 * n) + 1; } count++; } return count; } void software() { int i; for(i = 0; i < 1000; i++) { shared[i] = collatz(i + 1); } } void hardware() { //Start the hardware IP core XToplevel_Start(&hls); //Wait until it is done while(!XToplevel_IsDone(&hls)); } void print_shared() { int i; for(i = 0; i < 1000; i++) { xil_printf("%d ", shared[i]); } xil_printf(" "); } void setup_shared() { int i; for(i = 0; i < 1000; i++) { shared[i] = i+1; //(we use i+1 because collatz of 0 is an infinite loop) } } int main() { init_platform(); Xil_DCacheDisable(); //Initialise the HLS driver XToplevel_Initialize(&hls, XPAR_TOPLEVEL_0_DEVICE_ID); XToplevel_Set_ram(&hls, (int) shared); xil_printf(" Start "); setup_shared(); software(); print_shared(); setup_shared(); hardware(); print_shared(); cleanup_platform(); return 0; }
检查此代码。该函数software()是前 1000 个整数的 Collatz 迭代阶段的软件实现,将迭代计数放在全局数组shared中。该main函数设置 shared为 1 到 1001 的整数,运行software(),然后将结果打印出来。然后它重置共享并运行hardware()并打印结果。
在 HLS 中实现一个硬件组件来计算前 1000 个整数的 Collatz 计数(就像 ARM 软件一样)。从以下顶级结构开始:
#include// Required for memcpy() uint32 workingmem[1000]; uint32 toplevel(uint32 *ram, uint32 *arg1, uint32 *arg2, uint32 *arg3, uint32 *arg4) { #pragma HLS INTERFACE m_axi port=ram offset=slave bundle=MAXI #pragma HLS INTERFACE s_axilite port=arg1 bundle=AXILiteS #pragma HLS INTERFACE s_axilite port=arg2 bundle=AXILiteS #pragma HLS INTERFACE s_axilite port=arg3 bundle=AXILiteS #pragma HLS INTERFACE s_axilite port=arg4 bundle=AXILiteS #pragma HLS INTERFACE s_axilite port=return bundle=AXILiteS //Read in starting values memcpy(workingmem, ram, 4000); //Calculate the Collatz results. //workingmem[x] = collatz(workingmem[x]); //...your code here... //Burst copy workingmem to main memory memcpy(ram, workingmem, 4000); return 0; }
因为 Collatz 循环是无界的,所以 HLS 将只有问号而不是时间估计。
然后将 IP 核放入设计中并运行 IP 核以测试它是否输出正确的答案。以上main.c应该可以驱动 IP 内核。
那么,硬件或软件更快?
审核编辑:刘清
-
如何使用AMD Vitis HLS创建HLS IP2025-06-13 2499
-
请问一下怎样使用cubeide去生成一些代码呢?2022-12-08 499
-
使用Vitis HLS创建属于自己的IP相关资料分享2022-09-09 5598
-
请问一下怎样去移植官方SDK呢2022-03-01 864
-
请问一下怎样去使用Buildroot编译madplay呢2021-12-27 997
-
请问一下基于stm32f1的FreeRTOS该怎样去移植呢2021-12-16 1105
-
请问一下怎样使用串口去下载stm32程序呢2021-12-06 1647
-
请问一下怎样去使用STM32 KEIL下的printf函数呢2021-11-30 975
-
请问一下怎样去使用STM32L152芯片的基本定时器呢2021-11-24 1877
-
请问一下怎样去使用STM32的USART呢2021-11-18 862
-
请问一下怎样去设计一种基于stm32f103的数字示波器呢2021-11-12 1630
-
请问一下怎样去搭建一种Arduino IDE环境呢2021-10-25 1693
-
使用教程分享:在Zynq AP SoC设计中高效使用HLS IP(一)2017-02-07 4393
全部0条评论

快来发表一下你的评论吧 !
