

逻辑复制的概念与原理
电子说
描述
在数字化时代的今天,我们都认同数据会创造价值。为了最大化数据的价值,我们不停的建立着数据迁移的管道,从同构到异构,从关系型到非关系型,从云下到云上,从数仓到数据湖,试图在各种场景挖掘数据的价值。而在这纵横交错的数据网络中,逻辑复制扮演着极其重要的角色。
让我们将视角从复杂的网络拉回其中的一个端点,从PostgreSQL出发,对其逻辑复制的原理进行解密。
概念与原理
逻辑复制,是基于复制标识复制数据及其变化的一种方法。区别于物理复制对页面操作的描述,逻辑复制是对事务及数据元组的一种描述。
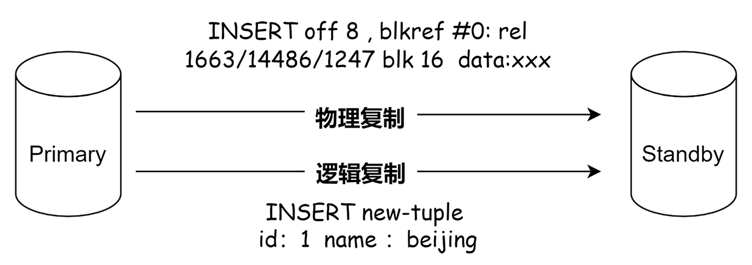
图-WAL数据流示例
如图所示,物理复制的数据流是对tablespace/database/filenode文件的块进行操作,而逻辑复制的内容是对元组进行描述。
接下来我们来看逻辑复制中的几个概念:
* 复制槽
复制槽是记录复制状态的一组信息。由于WAL(预写式日志)文件在数据真正落盘后会删除,复制槽会防止过早清理逻辑复制解析所需的WAL日志。在逻辑复制中,每个插槽从单个数据库流式传输一系列更改,创建复制槽需要指定其使用的输出插件,同时创建复制槽时会提供一个快照。
* 输出插件
输出插件负责将WAL日志解码为可读的格式,常用的插件用test_decoding(多用来测试),pgoutput(默认使用),wal2json(输出为json)。PostgreSQL定义了一系列回调函数,我们除了使用上述插件,可以通过回调函数编写自己的输出插件。
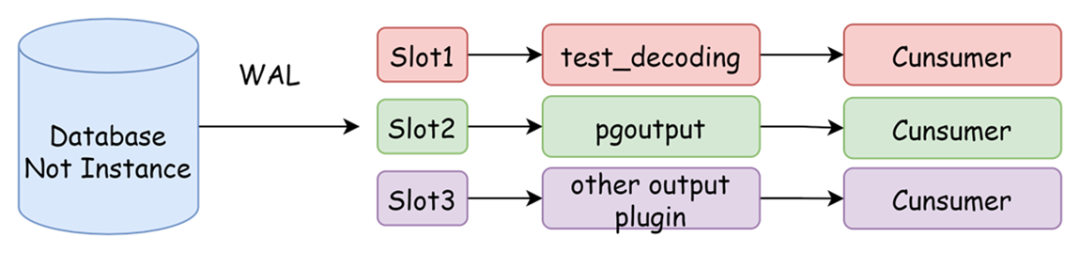
图-复制槽数据流
* 复制协议与消息
通过复制协议,我们可以从源端获取WAL数据流。例如通过PSQL工具建议复制连接
psql "dbname=postgres replication=database"
开启流式传输WAL
START_REPLICATION[ SLOT slot_name] [ PHYSICAL] XXX/XXX[ TIMELINE tli]
无论是物理复制,还是逻辑复制,使用PostgreSQL的发布订阅或者pg_basebackup搭建流复制,都是通过复制协议与定义的消息进行交互(物理复制和逻辑复制数据流内容不同)

图- WAL数据流消息类型
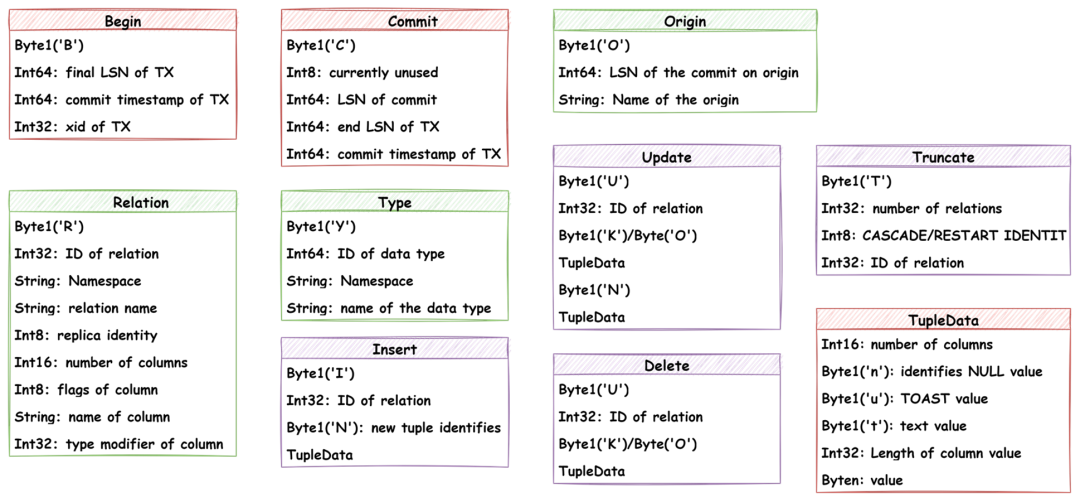
图-逻辑复制中的XLogData消息
* 工作流程
当我们了解了概念之后,来看一下整个解析的工作流程。由于WAL文件里一个事务的内容并不一定是连续的,所以需要通过Reorder后放在buffer中,根据事务ID组织成一条消息,COMMIT后发送给输出插件,输出插件解析后将消息流发送给目标端。
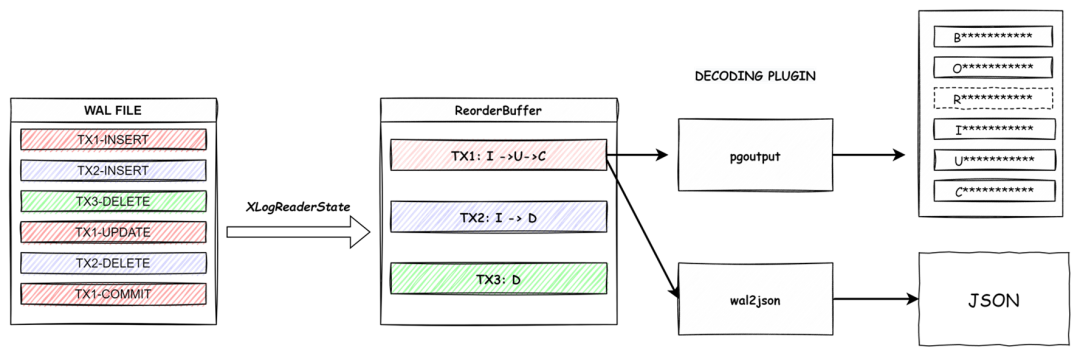
图-逻辑解析工作流程
问题与演进
当我们掌握了逻辑复制的原理,计划使用其构建我们的数据迁移应用之前,我们还有一些问题并没有解决。让我们来一起看看是什么亟待解决的问题,以及我们如何进行处理。
* 问题一:Failover slot
为了高可用性,数据库至少会存在一主一备的架构,当主库故障进行高可用切换时,备库却没有相应的复制槽信息,也就是缺少failover slot。这是由于保存slot信息的物理文件,未同步至备库。那么我们如何手动创建一个faliover slot呢?
1. 主库创建复制槽,检查备库wal文件是否连续
2. 复制包含slot信息的物理文件至备库,在pg_repslot目录下
3. 备库重启,重启后才可以看到复制槽信息,原因是读取slot物理文件的函数StartupReplicationSlots只会在postmaster进程启动时调用。
4. 定期查询主库slot状态,使用pg_replication_slot_advance函数推进备库复制槽
自此,我们在备库上也有了相应的信息,手动实现了failover slot。PostgreSQL生态中著名的高可用软件Patroni也是以这种方式进行了实现,区别只是在Patroni查询主库slot状态时将信息写入了DCS中,备库拿到DCS中的位点信息进行推进。
* 问题二:DDL同步
原生的逻辑复制不支持解析DDL语句,我们可以使用事件触发器来进行处理。
1. 使用事件触发器感知表结构变更,记录到DDL_RECORD表中,并将该表通过逻辑复制进行发布。
2. 接收端获取到该表的数据变更,即可处理为相应DDL语句进行执行。
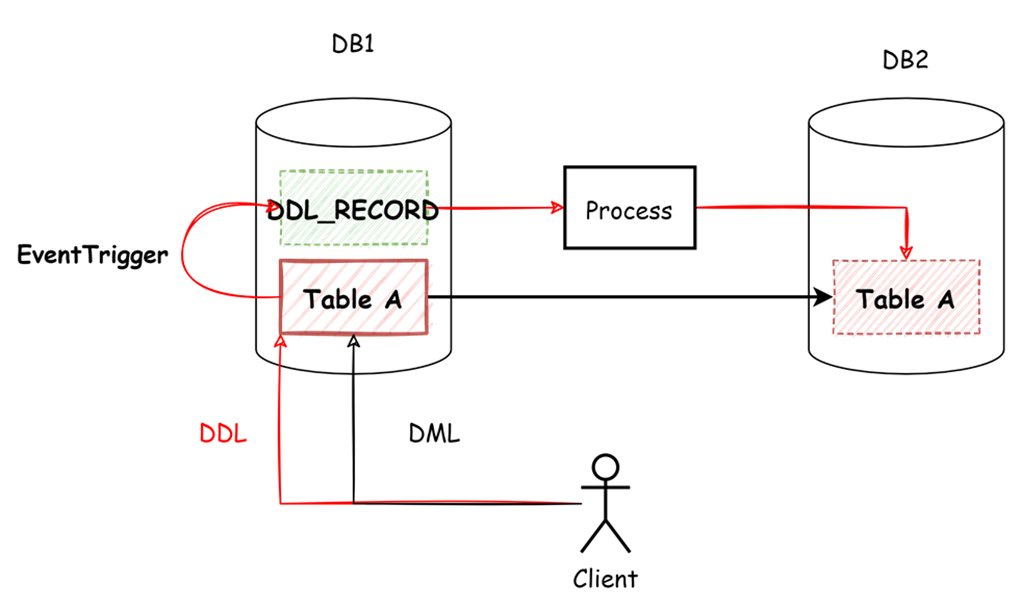
图-事件触发器实现DDL同步
* 问题三:双向同步
当数据迁移涉及双向同步的管道时,例如想实现双主双写,对数据库同一对象进行操作,就会出现WAL循环。

图-相同表双向同步导致数据循环
部分DTS应用为了解决这个问题会创建辅助表,在事务中先对辅助表进行操作,通过解析到对辅助表的操作而得知该记录是有DTS应用插入,从而过滤该事务,不再循环解析。PostgreSQL对事务提供了Origin记录,无须辅助表,通过pg_replication_origin_session_setup函数或者发布订阅中的replorigin_create即可指定Origin ID。
指定Origin ID后,我们除了可以解析后通过DTS应用进行过滤,还也可以通过解析插件中的FilterByOriginCB回调函数在解析过程中过滤,这种方式减少了数据传输,效率更高。
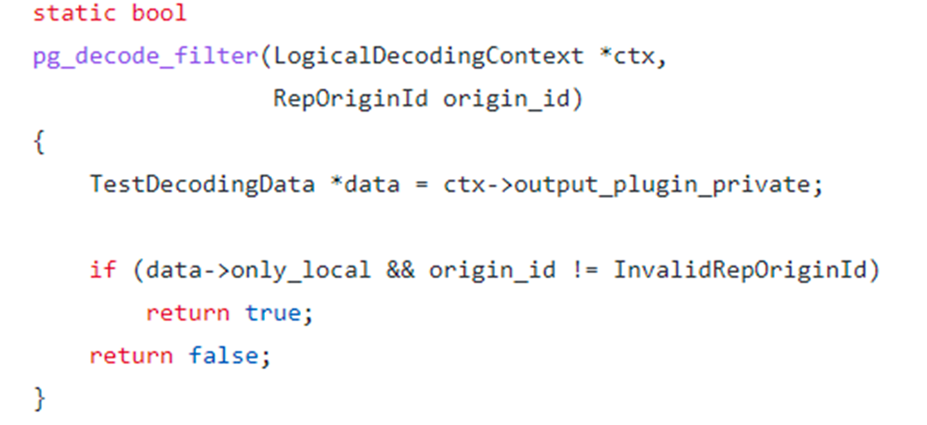
图-test_decoding中OriginFilter函数DEMO
* 其他问题
除了以上三个问题,还有一些使用的问题或限制。这里列出了一些,不再展开,仅简要说明。
Toast处理:对于toast值(消息格式中可以判断),我们在处理时一般使用占位符进行处理,接收端接收到占位符就不对这一列进行处理,虽然有些麻烦,但这也是在和传输toast值的方案中权衡的结果。
心跳表:由于复制槽记录的XMIN是全局的,当我们发布的表一直没有更新时,XMIN没有推进导致WAL积压,我们可以创建一张心跳表,周期性写入数据并发布,使XMIN进行推进。
大事务延迟:根据前文提到的工作流程我们可以知道默认事务在COMMIT后才会进行解析,这对于大事务来说势必会导致延迟,PG14版本提供了streamin模式进行解析,即事务进行中进行解析并发送至接收端。
应用与实践
前两节我们从原理及问题的角度对PostgreSQL进行了解密,接下来我们看如何通过我们掌握的逻辑复制原理,进行数据迁移的应用与实践。
* 全量与增量同步
在真实的数据迁移场景中,大部分都是全量和增量都要同步的场景,并且我们打通了数据传输的通道后,也对这条通道的安全,效率,以及功能的扩展,例如清洗,脱敏等ETL能力提出了新的要求。我们先来看一下如何实现全量与增量的同步。
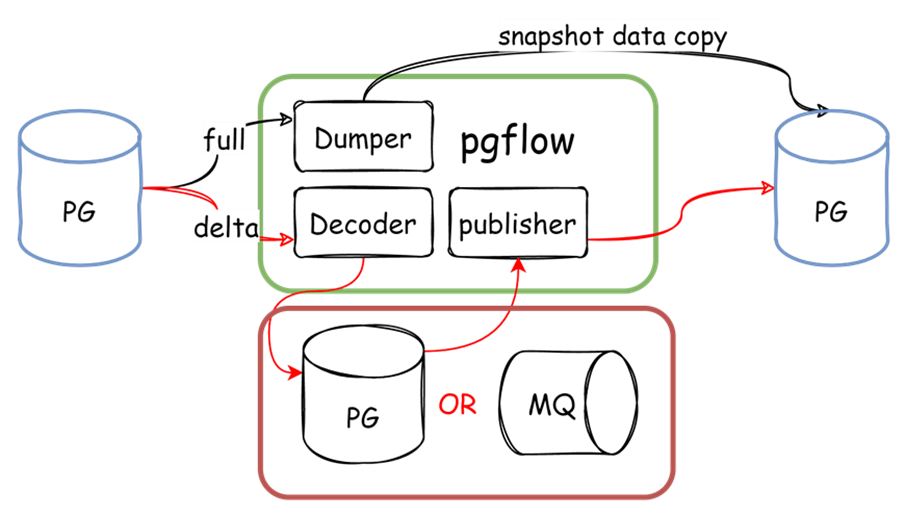
图-数据流向示意图
主要流程包括:
1. 创建复制槽并导出快照
2. 根据快照进行全量数据迁移
3. 根据复制槽进行增量数据的迁移
我们使用了PG数据库或者消息队列MQ作为数据代理,全量与增量解析可以同时进行,当全量数据处理完毕后,状态机通知增量处理程序进行增量发布。而对于代理中的数据,可以在解析后进行预处理。
* 自建实例迁移上云实践
最后和大家分享一个自建实例迁移上云的实践,该案例是将自建的PG10版本实例迁移至京东云上的RDS PG 11版本,通过对增量数据的回流以及数据校验保证了数据安全与业务平稳切换。
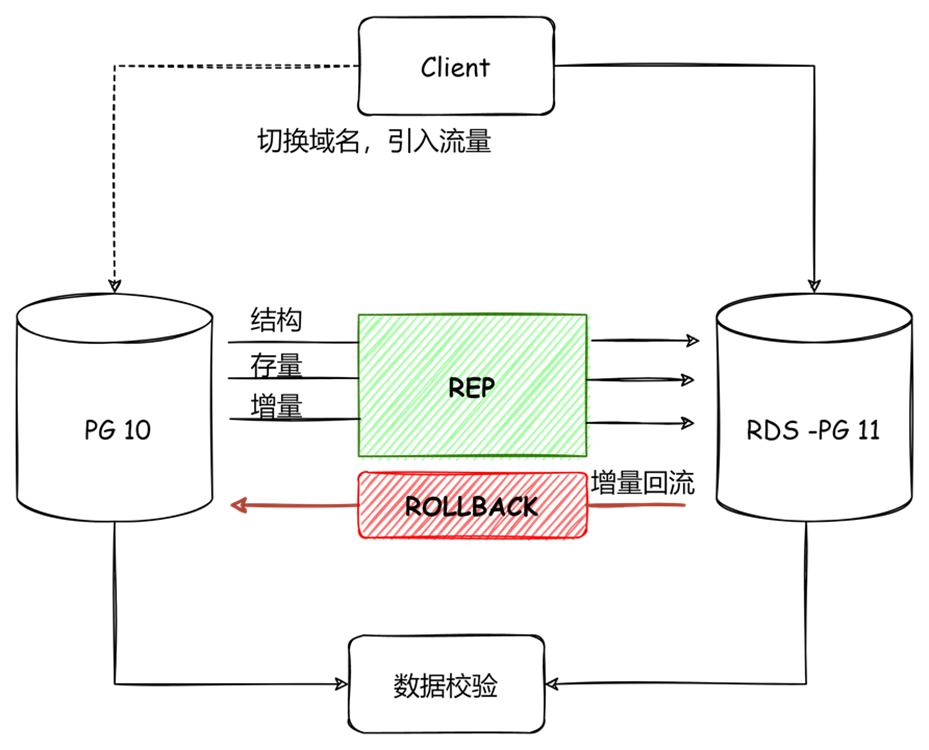
图-数据迁移上云
DTS应用主要分为如下几个阶段:
1. 数据检查阶段:检查主键,权限,配置
2. 数据迁移阶段:结构,存量,增量数据迁移,监控迁移状态
3. 应用迁移阶段:切换域名,引入流量
4. 回滚阶段:增量数据回流,若出现问题可快速回滚。
-
时序逻辑电路的基本概念、组成、分类及设计方法2024-08-28 6549
-
组合逻辑控制器的基本概念、实现原理及设计方法2024-06-30 4689
-
mysql主从复制的原理2023-11-16 1313
-
逻辑门电路基本概念介绍2023-10-10 6166
-
逻辑门电路有关概念2023-09-15 4658
-
逻辑门电路相关概念2023-04-26 3447
-
FPGA设计中逻辑复制的使用2022-09-29 1427
-
解释一下有关逻辑电平的一些概念2021-07-28 2110
-
逻辑电平的一些基本概念详细说明2021-01-06 2332
-
常见逻辑电平介绍和基本概念2021-01-02 26816
-
数据库概念结构和逻辑与物理结构如何进行设计2018-10-23 4370
-
PCB概念上涨的逻辑是什么_龙头股有哪些?2018-07-23 17426
-
FPGA实战演练逻辑篇46:逻辑复制与资源共享2015-07-05 3294
-
线与逻辑、锁存器、缓冲器、建立时间、缓冲时间的基本概念2007-08-21 1750
全部0条评论

快来发表一下你的评论吧 !
