

NLP的经典任务——句法(Syntactic)分析
嵌入式技术
描述
句法(Syntactic)分析是NLP的经典任务
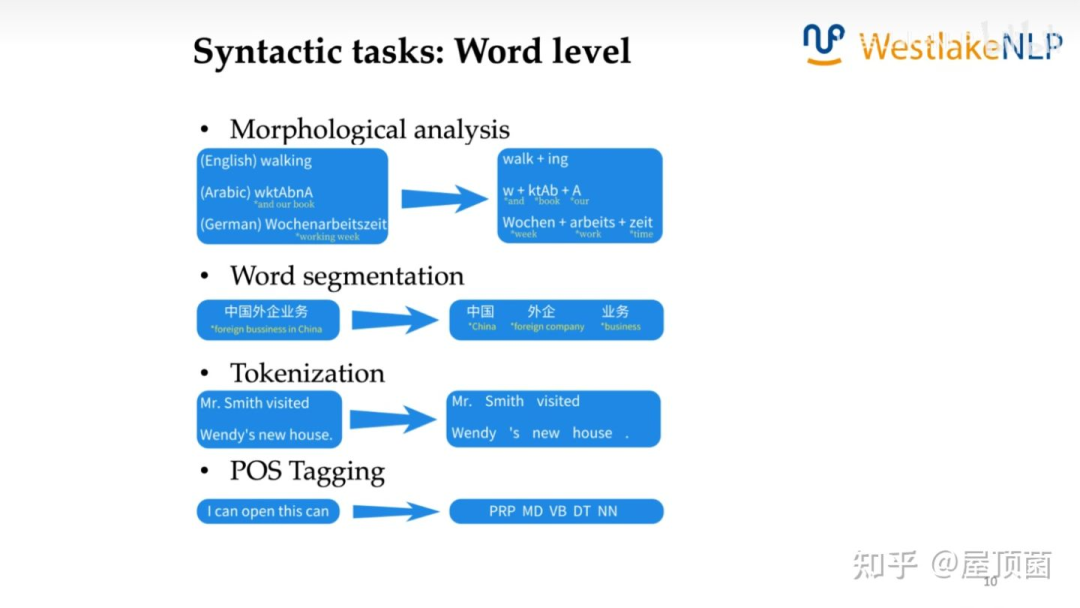
Syntactic tasks: Word level
Word level的句法分析任务有:形态分析、分词、序列标注
形态分析:Morphological analysis,指将一个词的词根(stem)和词缀(prefix & suffix)提取出来的任务
分词:Word segmentation or Tokenization,不同的语言分词方法不一样。对于中文、日文等语言,语句由字符的序列组成,因此词的形态化比较简单,分词一般指将文本中的字的序列分割成词的序列。此外,中文分词的歧义性较强。而对于英文,没有所谓的“分词”,对应的任务叫做Tokenization,指将文本序列切成由token组成的序列,如Wendy's -> Wendy + 's。Tokenization可以概括为按照特定需求,把文本切分成一个字符串序列(其元素一般称为token,或者叫词语)。
根据不同的需求,tokenization有不同的分割粒度:
字粒度:I have a apple -> I / h / a / v / e / a / a / p / p / l / e
词粒度:I have a apple -> I / have / a / apple
subword粒度:I have a new GPU. -> ['i', 'have', 'a', 'new', 'gp', '##u', '.']
词性标注:Part-of-speech(POS),将词在句子中扮演的角色进行标注,如动词、名词等。因为一词多义的存在,这个过程也存在歧义性。具体的tag可以参考:Universal POS tags,更细粒度的tag(Spacy)
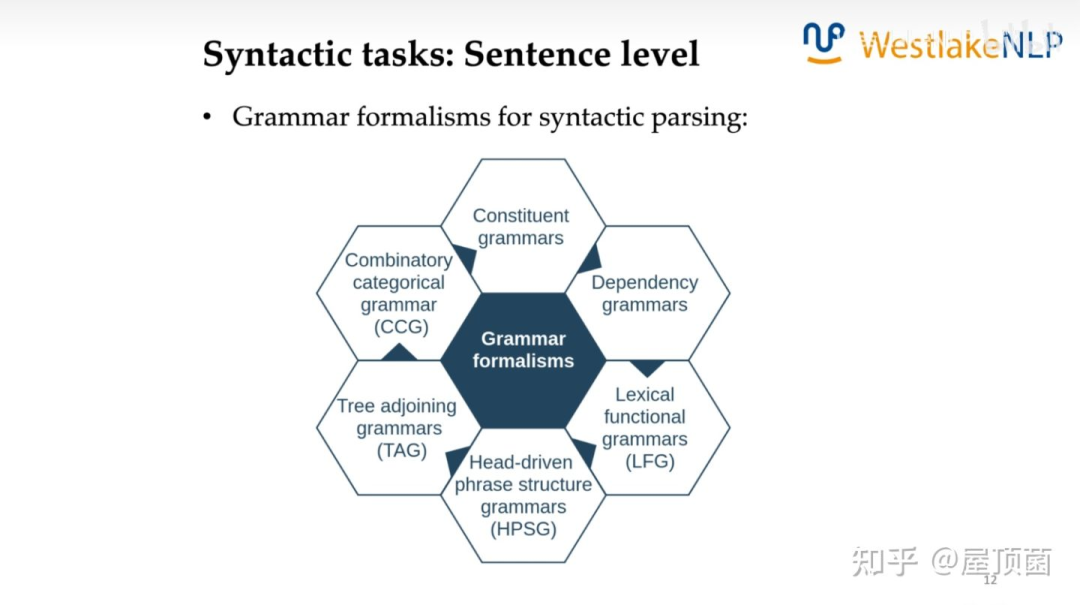
Syntactic tasks: Sentence level任务很多,其中Dependency parsing 和 Constituent parsing 比较常见。
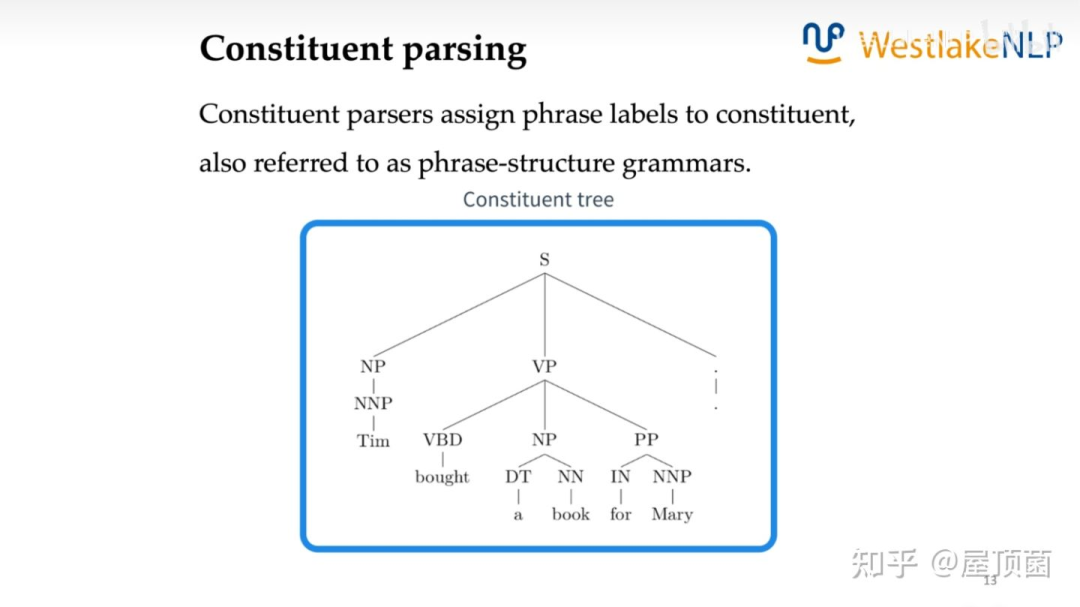
成分句法分析:Constituent parsing,找到一句话中的层次短语结构
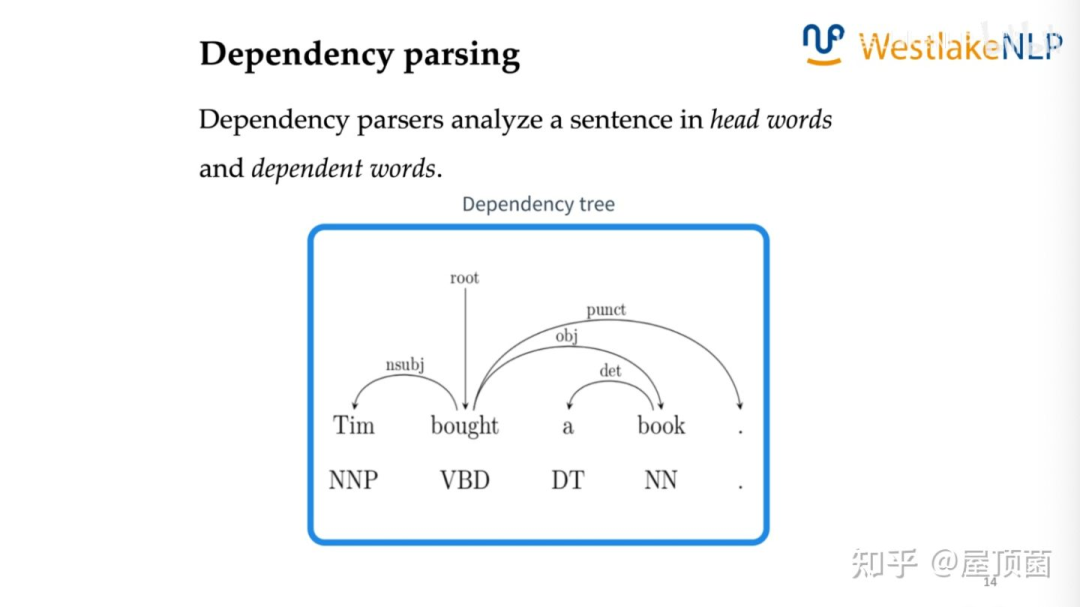
依存句法分析:Dependency parsing,这种句法结构通过词之间的两两关系组成一句话的结构。这些关系包含:主语、宾语、修饰语等等,每个词修饰一句话中的另一个唯一的词(除了root节点,如下图中的bought)。
CCG parsing,组合范畴句法分析,形式为一种高度词汇化的句法

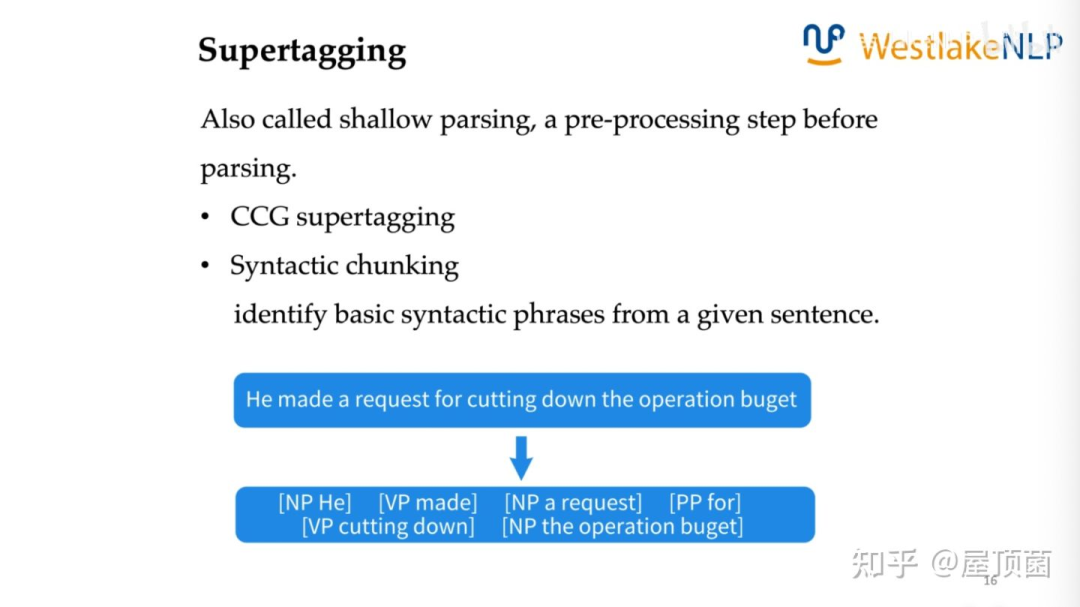
CCG supertagging:在组合句法分析中,给每个词打标签
Syntactic chunking:把一个句子,切成比较大的短语块
编辑:黄飞
- 相关推荐
- 热点推荐
- nlp
-
依存句法分析器的简单实现2018-10-17 2993
-
pyhanlp两种依存句法分类器2018-12-21 3487
-
基于本体和句法分析的领域分词的实现2009-04-09 407
-
NLP多任务学习案例分享:一种层次增长的神经网络结构2018-01-05 6400
-
OpenAI介绍可扩展的,与任务无关的的自然语言处理(NLP)系统2018-06-17 4751
-
如何使用中文信息MMT模型进行句法自动分析资料免费下载2018-12-19 1325
-
自然语言处理中极其重要的句法分析2019-04-09 14237
-
如何利用机器学习思想,更好地去解决NLP分类任务2020-08-28 3130
-
金融市场中的NLP 情感分析2020-11-02 2766
-
什么是句法分析2020-11-24 9620
-
关于NLP任务的所有GNN相关技术介绍2021-06-23 4588
-
多语言任务在内的多种NLP任务实现2022-10-13 1084
-
NLP领域的语言偏置问题分析2024-01-03 1245
-
nlp自然语言处理的主要任务及技术方法2024-07-09 3635
全部0条评论

快来发表一下你的评论吧 !
