

调度算法评测与仿真系统 调度算法仿真系统介绍
电子说
描述
哈啰两轮车调度算法介绍
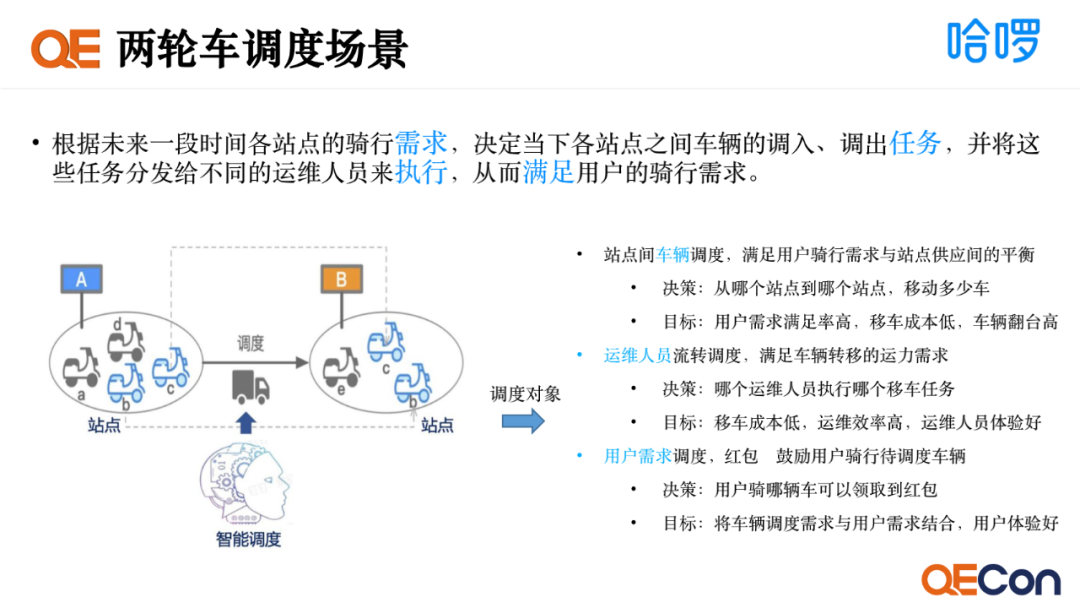
调度是将稀缺资源分配到一定时间内的不同任务上的决策过程,目的是优化一个或多个目标。两轮车调度场景是指通过预测未来用户的骑行需求,决定各站点车辆的调配任务,并将这些任务分配给合适的运维人员来执行,从而满足用户的骑行需求。在这个调度场景里会涉及三个对象,一是车辆,目标是用户需求满足率高,移车成本低,车辆翻台高。二是运维,目标是运维效率高,运维人员体验好。三是用户,目标是用户体验好。
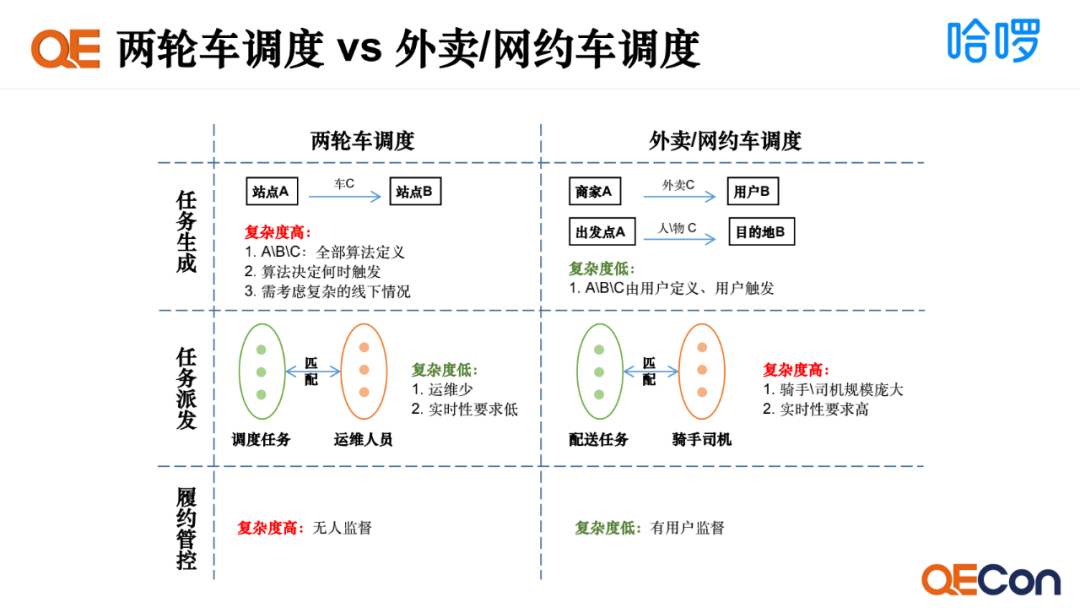
我们将两轮车调度和外卖/网约车调度做对比,调度涉及到任务生成、任务派发和履约管控三个环节。在任务生成环节,两轮车调度的复杂度比外卖/网约车调度高,原因在于调度涉及到三个要素,调度算法触发的时机需要依托算法来决策,同时需要兼顾线下各种复杂的情况,如天气季节因素,竞对或城管干预等。在任务派发环节,两轮车调度的复杂度比外卖/网约车调度低,原因在于需要匹配的对象少,实时性要求低。在履约管控环节,两轮车调度的复杂度比外卖/网约车调度高,原因在于司机运维执行结果难以监管,而外卖/网约车有用户评价体系,监管便捷。
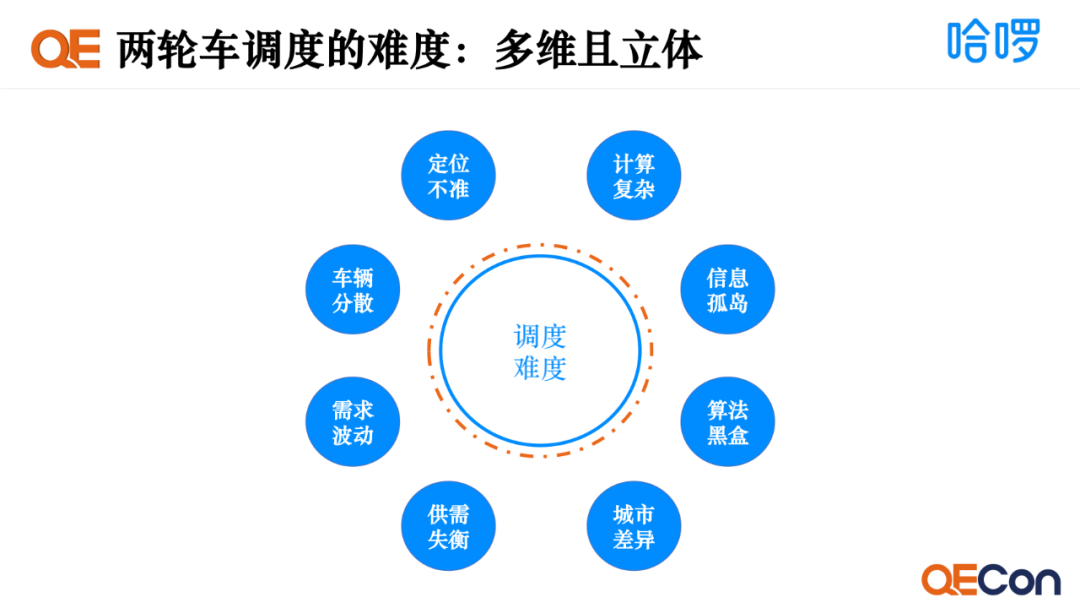
两轮车调度的难度是多维且立体的,一是定位不准,不同车辆型号定位的精准度是有差异的;二是车辆分散,司机需要去收集散落在各地的车辆;三是需求波动,如季节性的波动、早晚高峰的波动;四是供需失衡,实际投放的车辆数量与用户日益增长的需求匹配不上;五是城市差异,由于城市发展阶段和管控政策不同,会导致车辆投放与用户需求的差异;六是算法黑盒,会导致算法效果评估比较模糊;七是信息孤岛,如司机的载具在某个时刻可能会发生变化,但这些信息并不能及时同步到上层用于算法决策;八是计算复杂,一系列复杂的场景会导致算法的计算复杂度大增。

两轮车调度算法的目标总结下来是多快好省。一是多,我们希望算法调度占比高,覆盖的场景多,支持个性化。二是快,能够实时生成、实时派发、实时执行、实时反馈。三是好,我们希望让业务叫好,让司机叫好。四是省,既能省人工成本,又能省机器成本。
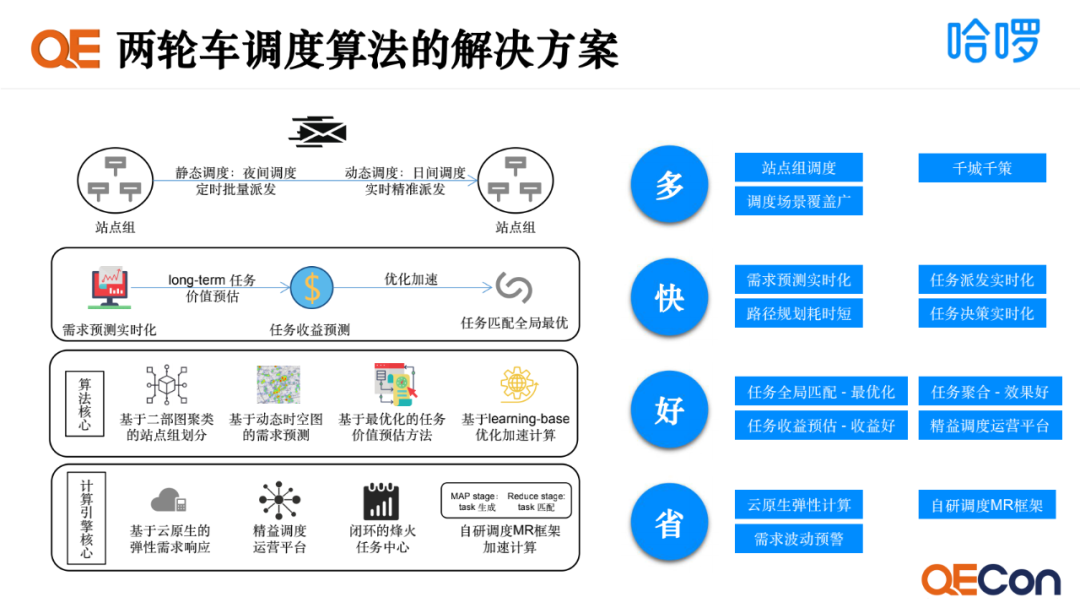
为了达成目标,我们制定了解决方案,左侧是我们解决方案的架构分层图。我们根据多快好省四个分类,推出了对应的解决措施。一是多,我们提供了站点组的调度策略,千城千策,调度场景覆盖广。二是快,我们将需求预测、任务派发与任务决策实时化,并通过路径规划找出最优路线。三是好,我们通过全局匹配来实现最优化,任务聚合来实现效果好,收益预估来提高收益,精益管理来提高管理效率。四是省,我们利用弹性计算、MR调度框架和调度波动预警,提高机器整体的资源利用率。
调度算法在效果评测上的挑战
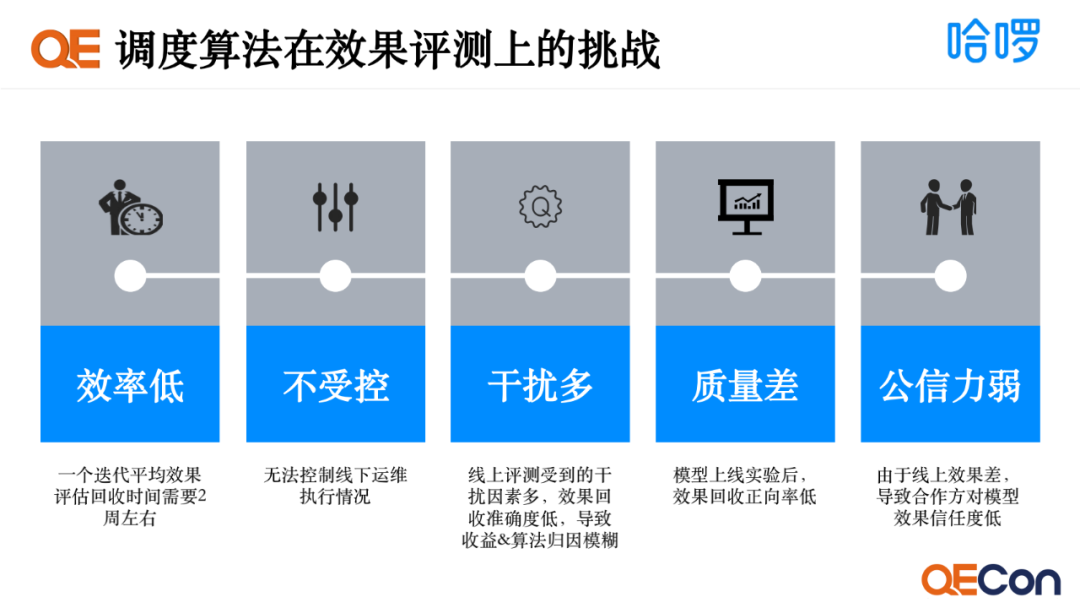
调度算法效果评测上有五个挑战,一是效率低,一个迭代平均效果评估回收时间需要两周左右。二是不受控,我们无法控制线下运维的执行情况。三是干扰多,线下执行受到的干扰因素多,效果回收准确度低,导致收益和算法归因模糊。四是质量差,模型上线试验后,效果回收正向率低。五是公信力弱,由于线上效果差,合作方对模型效果信任度低。
调度算法仿真系统介绍
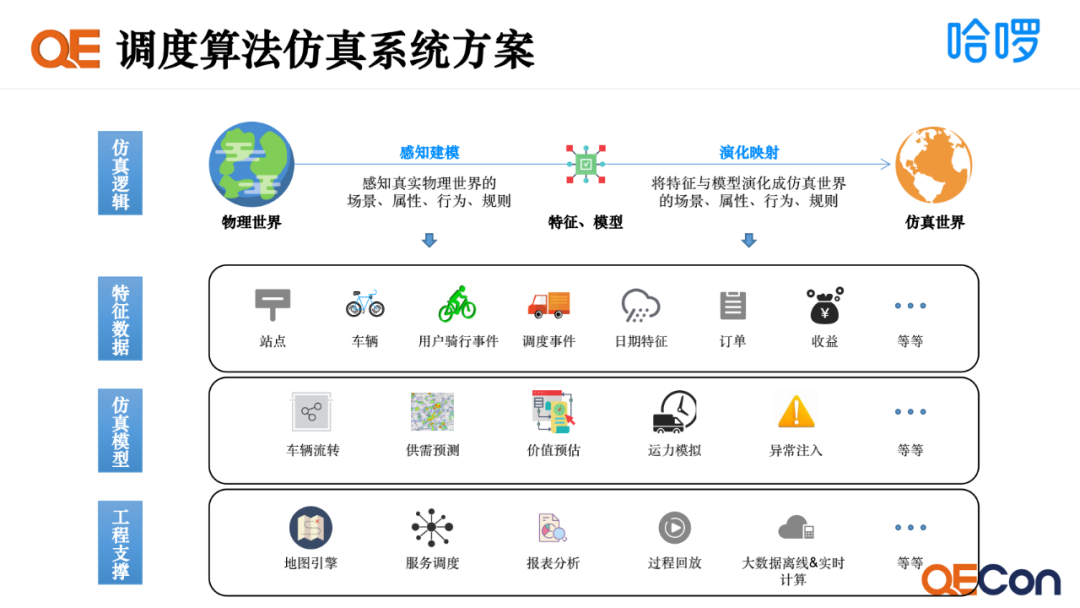
为了解决这个挑战,我们提出了仿真系统,通过对物理世界的仿真,达成调度算法离线验证和预测推演的能力。仿真逻辑如图所示,我们可以通过感知建模,对物理世界里的场景属性及行为,转换成特征和模型,其中特征是用来表达物理世界场景属性的数字化信息,而行为、规则用模型来表达。有了特征和模型后,我们可以使用工程技术手段把它演化成仿真世界里的场景、属性、行为和规则。如何做到仿真世界的实现,我们提出了三个层面,分别是特征数据、仿真模型和工程支撑。 特征数据
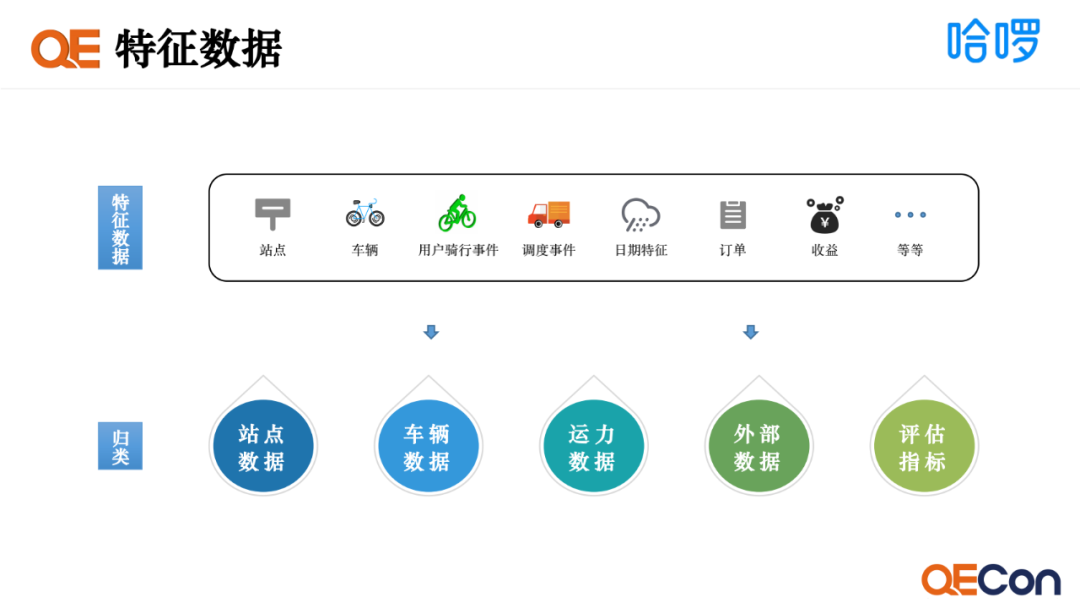
在物理世界中会存在各种各样的信息,如站点信息、车辆信息、用户骑行事件、调度事件、日期天气特征,订单、收益等。我们将其归纳成五个维度,站点数据、车辆数据、运力数据、外部数据和评估指标。 一是站点数据特征,包括站点基础信息、站点间流转订单、站点实时停驻车辆数、站点历史需求量和站点间骑行时间。二是车辆数据,包括车辆基础信息、车辆实时标签状态、车辆实时电量、车辆健康度和用户骑行收益。三是运力数据,包括司机画像、载具画像、载具实时数据、司机实时排班和运力成本。四是外部数据特征,包括节假日数据、天气特征、竞对实时数据、地图数据和城管干预。五是评估指标,如缺车数据、订单数据、调度量、翻台数据和车辆收益。
仿真模型
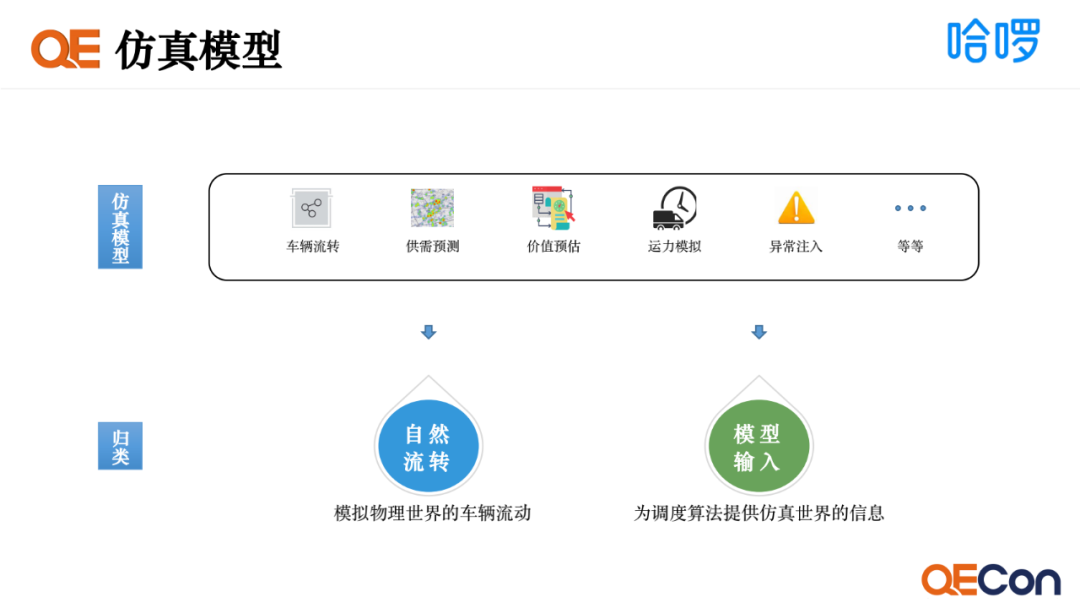
仿真模型是对物理世界行为或规则的模拟,主要会涉及到两部分。一是自然流转,指车辆在物理世界自然流动的情况,我们需要把它模拟出来。二是模型输入,指仿真世界里的一些实时数据,我们需要提供给调度算法去作为输入数据,如供需上需要预测的数据或运力的模拟数据。
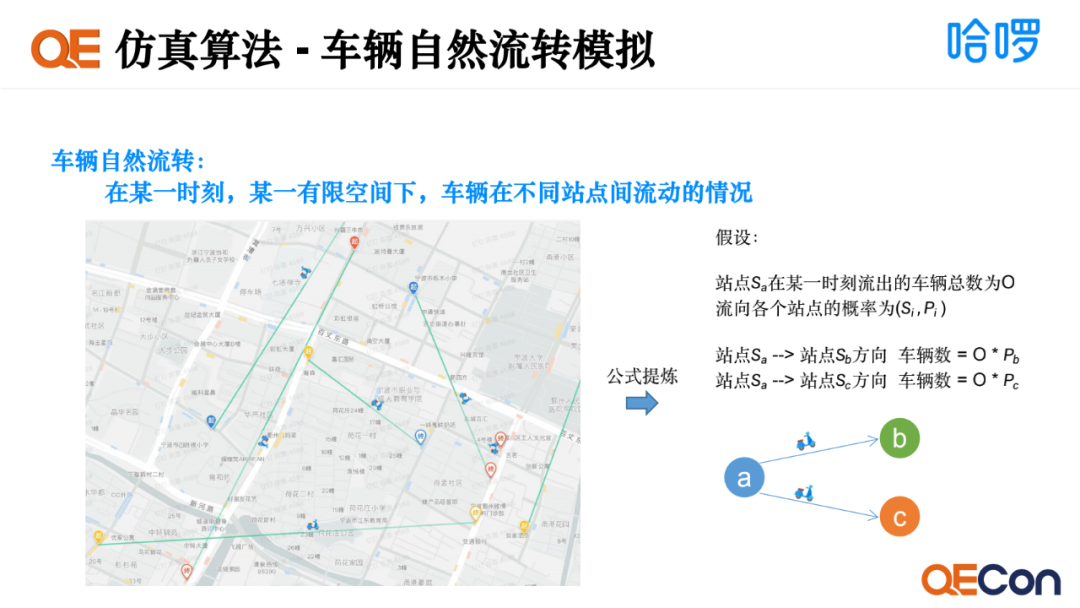
接下来介绍车辆自然流转的仿真实现,车辆自然流转指在某一时刻某一有限空间下,车辆在不同站点之间流动的情况。如图是某一时刻,车辆在不同站点之间流动的轨迹。我们进行公式提炼,假设某个站点Sa在某一时刻流出的车辆总数是O,流向各个站点的概率为(Si,Pi)。我们就可以知道站点Sa流向站点Sb的车辆情况,或者是站点Sa流向站点Sc的车辆情况,通过这个计算公式就可以得出来。
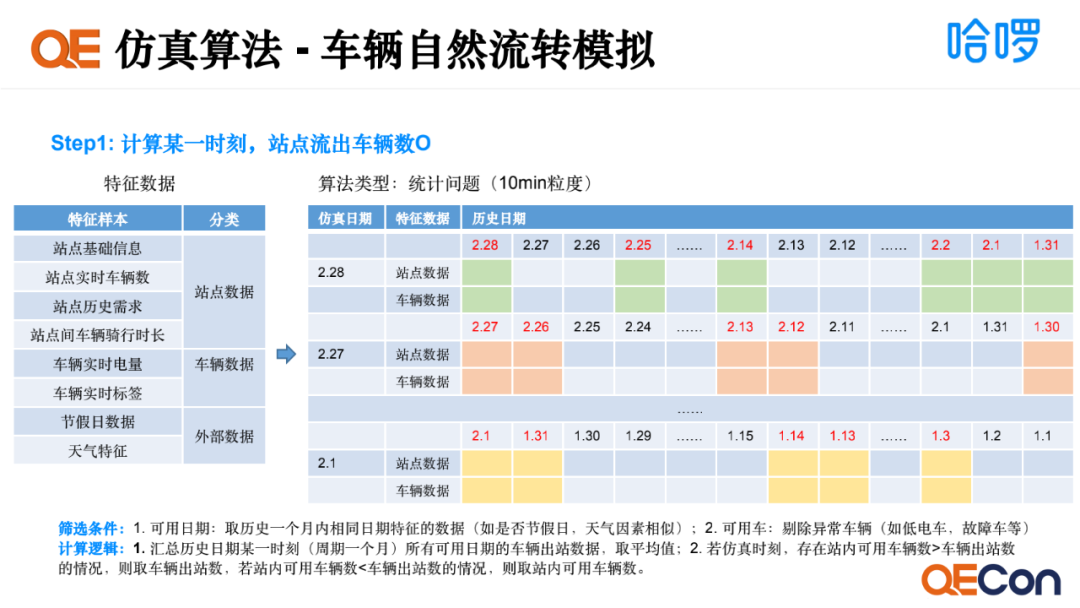
第一步我们要计算某一时刻站点流出的车辆数,会用到三个维度的特征数据,一是站点数据,包括站点基础信息、站点实时车辆数、站点历史需求和站点间车辆骑行时长。二是车辆数据,包括车辆实时电量和车辆实时标签。三是外部数据,包括节假日数据和天气特征。我们的筛选条件有两个,一是可用日期的筛选,我们取历史一个月内相同日期特征的数据,如是否节假日、天气因素相似。二是站点内可用车辆的数据,这里需要剔除异常车辆,如故障车和低电车。举个例子,我们要计算2月28日0点10分的站点车辆流出数据,会获取历史一个月内同样是0点10分的所有站点数据,根据可用日期作为筛选条件,把相同日期特征的站点数据筛选出来,汇总取平均值。有了平均站点车辆数后,我们还要去看站点内的可用车的情况。如果可用车辆数大于计算出来站点的出站数,就取出站数;如果可用车辆数小于出站数,就取站内可用车辆数。
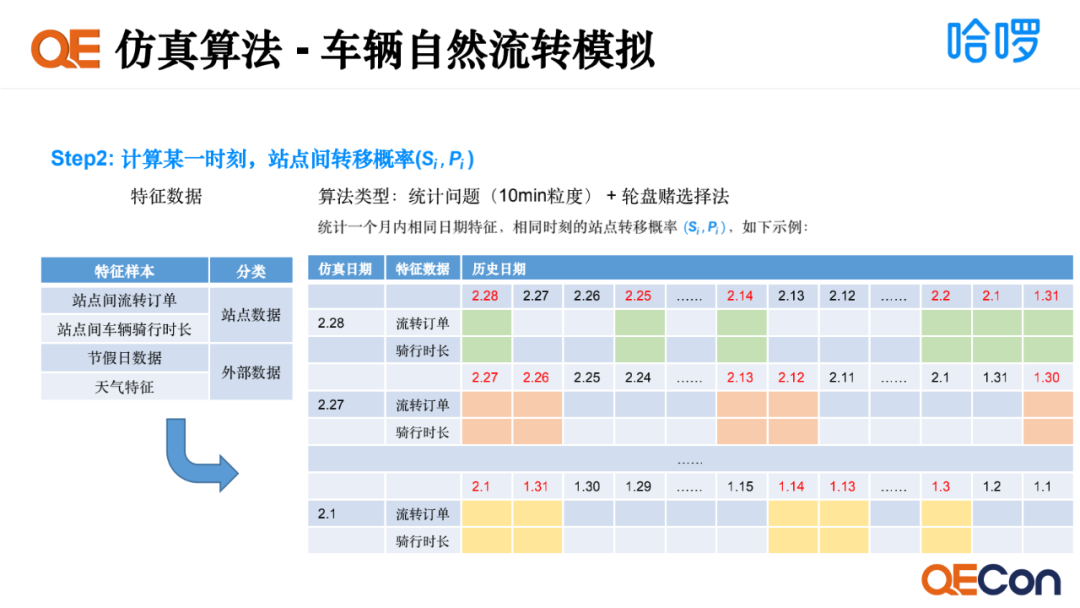
第二步我们要计算某一时刻站点间转移概率,会用到两个维度的特征数据。一是站点数据,包括站点间流转订单、站点间车辆骑行时长。二是外部数据,包括节假日数据和天气特征。它是一个统计问题,又因为物理世界中会存在某种意外概率的事件,为了能够模拟这些意外概率的事件,我们加入轮盘赌选择法,来使我们仿真的结果更贴近于物理世界。统计方式有些类似,都是取一个月内相同日期特征,计算不同站点之间流转概率的平均汇总。
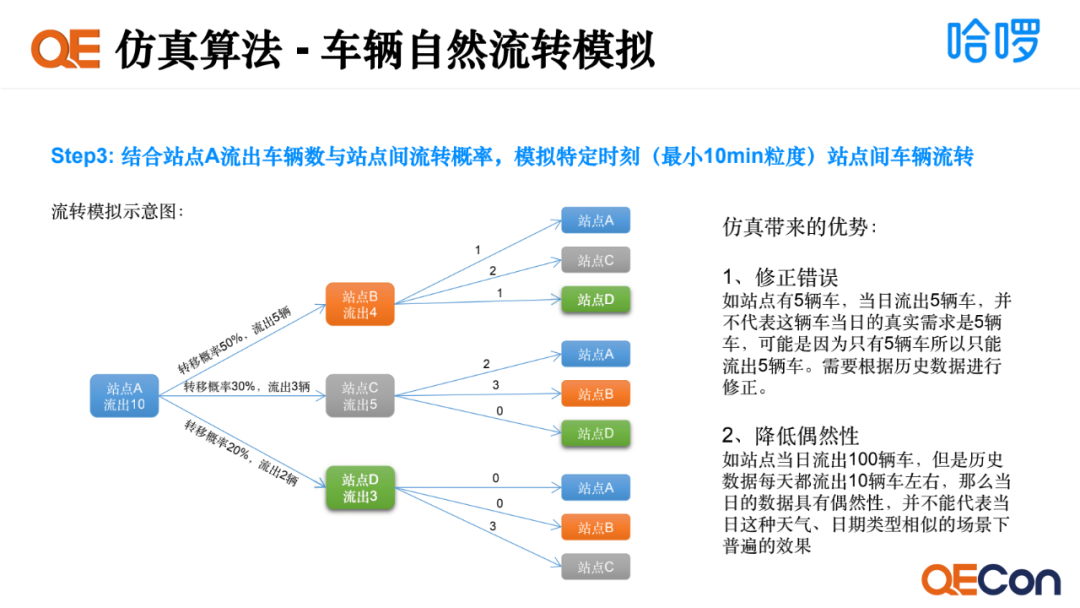
第三步是结合流出车辆数据和站点间流转概率,模拟特定时刻站点间车辆流转情况。如图所示,0点10分站点A流出10辆车,结合流转概率,我们可以得出站点A会往B流出5辆车,站点A会往C流出3辆车,站点A会往D流出2辆车,同样其他站点用类似的计算方式会得出流转方式。 仿真会带来一些优势:
能够修正错误,特定日期可能会有异常,如某个站点当日流出5辆车,并不代表它的真实需求是5辆车,可能是因为这个站点内只有5辆车,所以只能最多流出5辆车。我们有历史数据作为依据,可以修正异常值。
降低偶然性,如某些站点某一时刻会由于热点事件,如台风天气或演唱会举办等事件带来需求的波动,并不代表普遍的效果。

介绍完车辆自然流转模拟,这里有个问题,什么结果是好的仿真结果?于是就有了逼真度的概念。逼真度是用来量化仿真系统的一种途径,在一定程度上能够体现出仿真系统的正确性和可信度。而只有保证仿真系统的正确性和可信度,仿真结果才具有实际应用价值。

第一个维度是数据源和建模,我们假设数据源选取某城市、某日期,计算每个站点在每个时刻的真实流出,计算每个站点在每个时刻的仿真流出。我们会做两个维度的建模,站点维度和时间维度。站点维度建模是指我们按照真实流出和仿真流出两个指标,汇总出每一个站点在所有时刻的总流出并排序,会得到站点维度的真实排序和站点维度的仿真排序。时间维度建模是汇总每个小时在这个城市所有站点的总流出并按时间排序,得出时间维度的真实排序和时间维度的仿真排序。
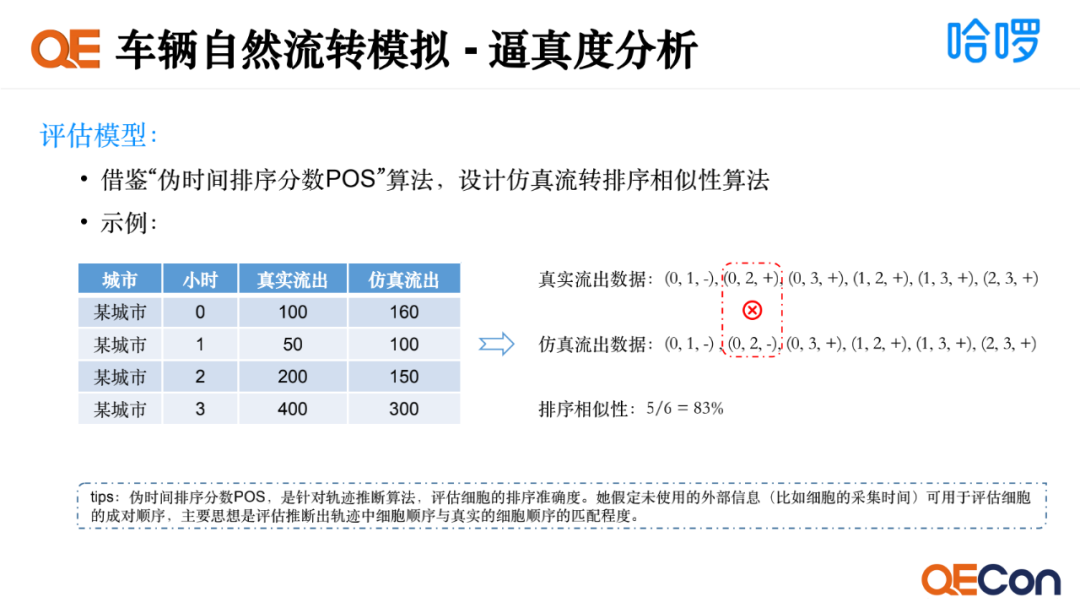
这里我们评估逼真度,借鉴了伪时间排序分数POS算法,设计仿真流转排序相似性算法。举个例子,如图是时间维度的排序,我们看到按照相似性算法,真实流出在0-1时是递减的,所以我们用“-”,0-2时是递增的,所以我们用“+”。仿真流出数据也按照这个逻辑。我们会发现0-2时真实流出和仿真流出不一致,因此我们得出排序相似性是83%。
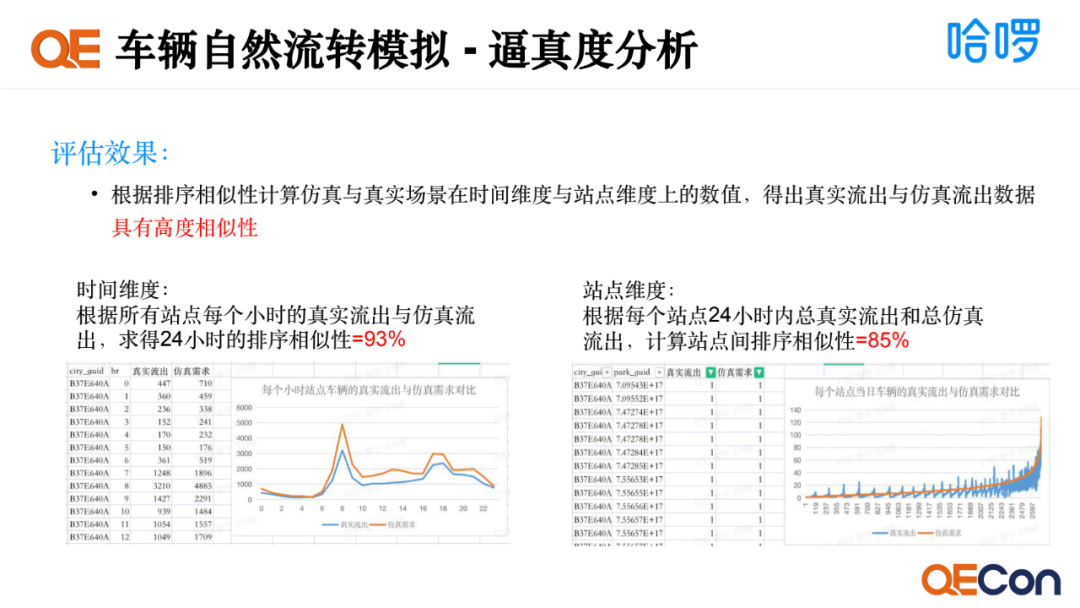
依据这样的计算方式,我们对某个城市某一时刻的数据做逼真度的分析,会得出两个结果。时间维度上站点每小时的真实流出与仿真流出,在24小时的排序相似度达到93%;站点维度上排序相似度达到85%。因此我们得出,真实流出跟仿真流出的数据具有高度的相似性。 工程支撑
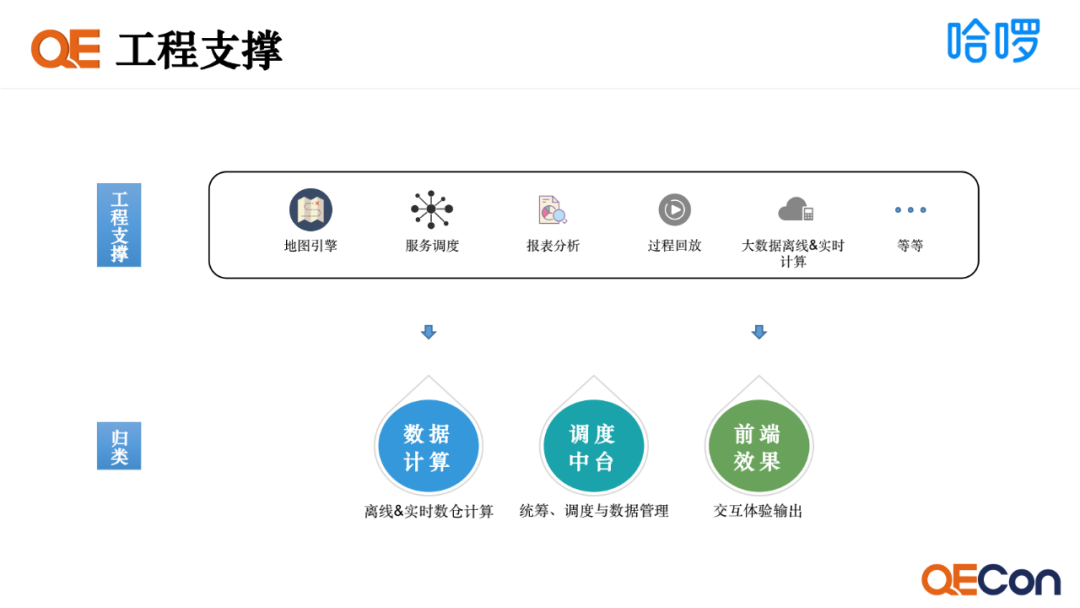
工程支撑主要借助工程的能力,融合特征和模型去实现仿真世界的演化。这里会用到很多的技术能力,如地图引擎、服务调度、报表分析、过程回放和数仓数据计算。我们将其归纳成三个维度,包括数据计算、调度中台和前端效果。
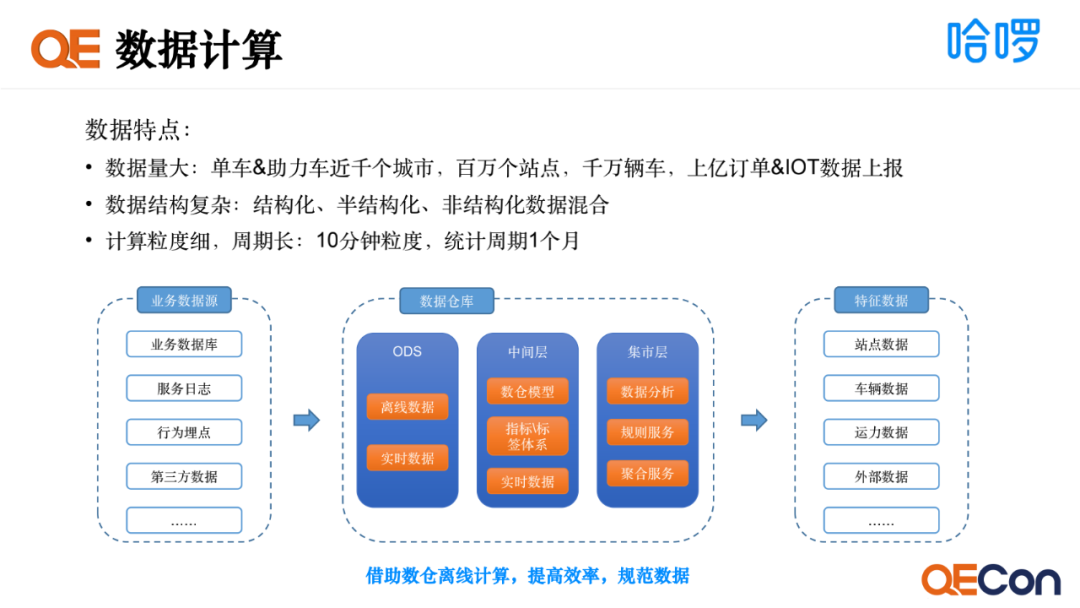
仿真数据具有三大特点:
数据量大,哈啰单车和助力车覆盖近千个城市,近百万站点,近千万辆车,有上亿的订单和IOT数据上报。
数据结构复杂,数据来源多样性,导致结构化数据、非结构化数据、半结构化数据都混合在一起。
计算粒度细、周期长,如果在仿真的时候去临时计算,成本会非常高,因此我们借助了数仓的离线计算能力,提高效率。
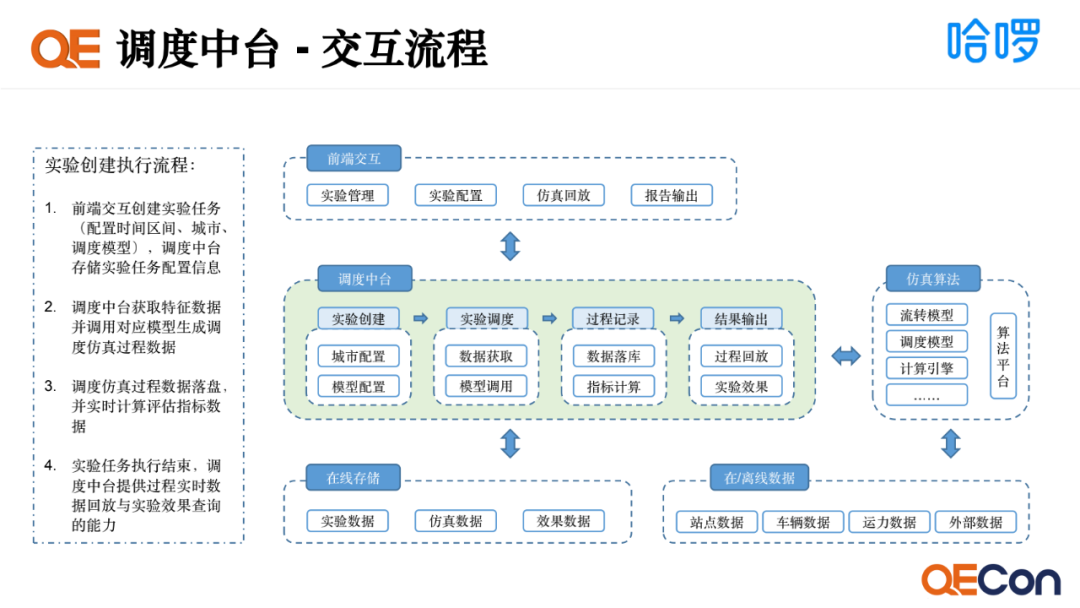
如图是实验创建执行流程,以此介绍调度中台的工作过程。首先是用户在前端创建实验,调度中台通过实验创建环节,会把用户创建实验的配置信息、城市、模型信息存储到在线存储里去。如果用户在前端进行实验执行的操作,调度中台通过实验调度的环节,根据之前配置的信息,整合相关的特征数据的集合,包括实验周期的约束条件,传递给仿真算法,这是异步的过程。数据传递过去后,仿真算法会根据粒度和周期去调用在线和离线数据作为模型入参,执行算法决策。 在周期执行过程中,算法会把过程记录通过消息的方式实时反馈给调度中台,调度中台会把这些数据进行过程指标的计算,并把过程结果和指标结果落库到在线存储里去。前端就可以实时查看实验的过程,对实验的过程进行操作干预。仿真算法执行完成后,调度中台会对整个实验数据做存储和规格化的处理,能够给前端提供过程回放和实验数据的展现,这是整个的实验流程。
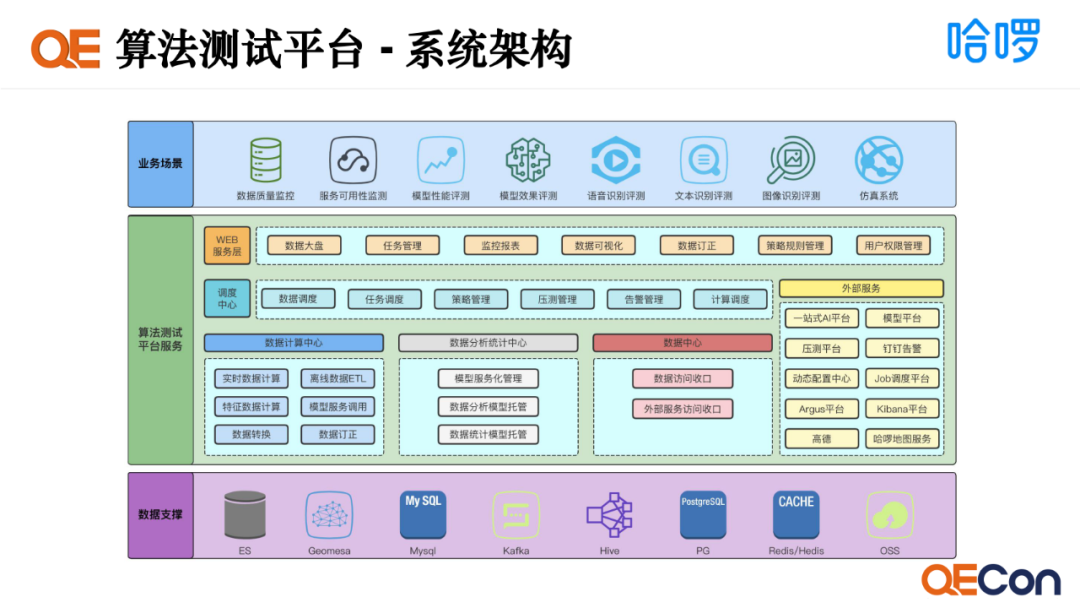
仿真系统是我们算法测试平台的一个子服务,平台还涵盖数据质量监控、服务可用性监测、模型性能评测、模型效果评测、语音识别评测、文本识别评测和图像识别评测。 算法测试平台采用微服务的设计思路,最外层有web服务层,对接所有的上游前端业务,底层可分为四大中心:
调度中心(负责所有管理行为,如数据调度,任务管理,策略管理,告警管理,计算调度等)
数据计算中心(负责所有计算行为,如实时&离线数据计算,数据转换,数据订正等)
数据分析统计中心(负责指标统计类行为,因为指标计算规则变化频繁且灵活多样,因此在该中心下连接多个脚本环境容器,如python,groovy等,通过平台在线编辑能力,允许用户灵活调整,随时变更指标分析与统计脚本)
数据中心(负责所有内外部数据访问收口及三方服务访问收口,并通过提高该服务的应用等级,保障整个系统的稳定性)。
它们各司其职,保证协作的稳定性和迭代开发的效率。
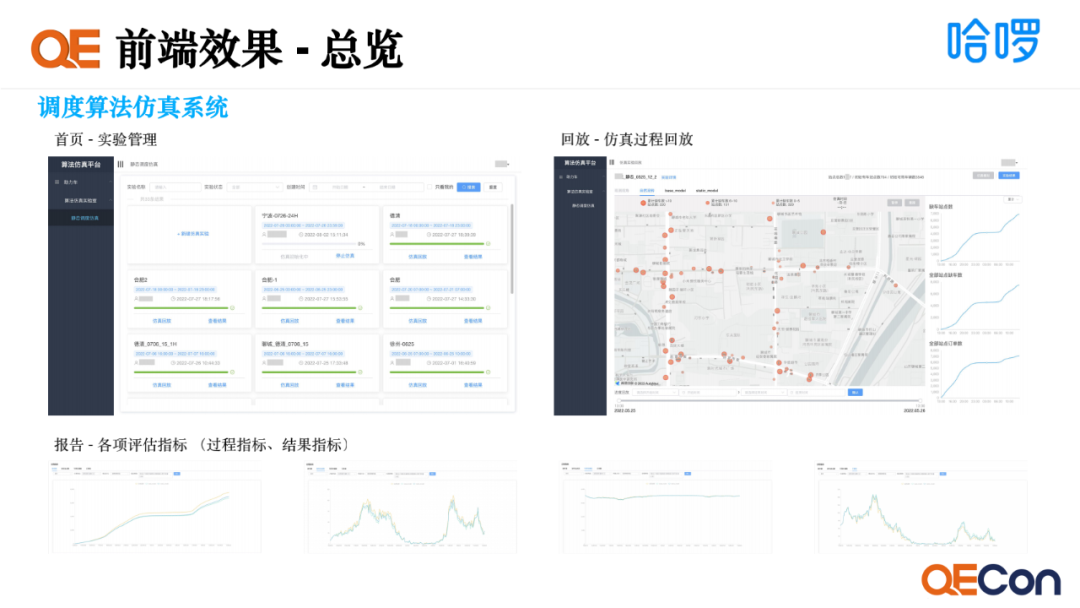
前端效果总览包括实验的管理、仿真过程回放和各项指标评测结果:
仿真实验室,作为仿真系统的入口,提供了实验创建、筛选和实验过程管控。
实验配置,可以去设置实验相关的参数,如仿真区域、时间区间、时间粒度等。
仿真回放,我们嵌入了地图的渲染引擎,提供观测不同模型的车辆流转效果和数据变化过程的能力。
实验报告,提供各项评估指标数据、报表化展示、交叉对比验证的能力。
收益和展望

仿真系统的收益归纳起来有六点:
城市覆盖,原先城市覆盖的数量有限且成本高,仿真系统可以支持全国400多个城市的任意选择。
评估效率,原先评估效率是周级别,仿真系统评估效率是小时级别。
线上质量,原先线上回收正向率低,仿真系统线上回收正向率预计提高两倍。
评估指标,原先评估指标比较简单,回收也相对麻烦,仿真系统可以定制多维度的指标。
干扰因素,原先有很多不可控因素,仿真系统干扰项都是可感知可控制的。
过程分析,原先过程变化是看不到的,仿真系统过程可回放、可分析。
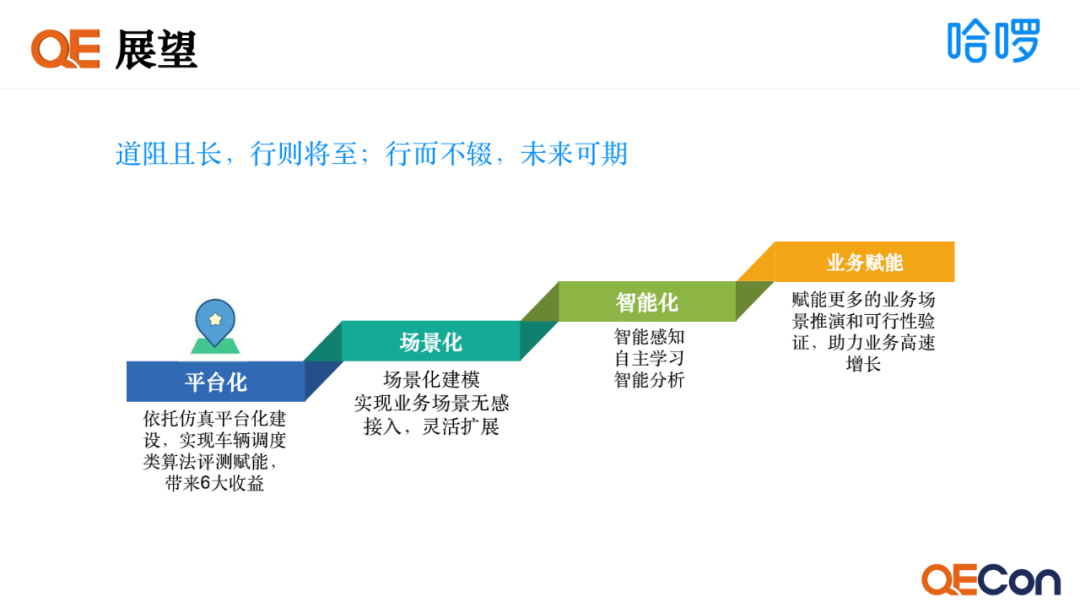
当前我们是在平台化阶段,依托仿真平台化建设,实现车辆调度类算法评测赋能,带来六大收益。后面我们希望能够实现场景化,借助场景化建模,实现业务场景无感接入,灵活扩展。第三个阶段是智能化仿真世界,我们希望能够实现智能感知特征数据、自主学习规则模型、智能分析评测效果。最后是业务赋能,我们希望能够赋能更多的业务场景,去实现线下的推演和可行性的验证,助力业务的高速增长。
编辑:黄飞
-
一种改进的SEDF调度算法2010-04-24 2485
-
详解Kernel2.6调度算法2019-08-07 1331
-
调度算法是什么?车载操作系统内核调度策略应注意哪些问题?2021-05-13 1645
-
嵌入式Linux操作系统调度算法的相关资料分享2021-11-05 892
-
基于DiffServ模型的调度算法2009-04-13 721
-
基于MAPSO算法的水库优化调度与仿真2009-04-20 1981
-
SLOP系统中数据块请求调度算法的研究2009-08-10 522
-
网格任务调度算法研究2009-08-14 600
-
动态调度算法(DSA)2009-03-30 2144
-
基于CANoe总线系统实时调度的仿真2017-01-24 1318
-
动态车间调度问题的改进微粒群算法2017-11-07 898
-
基于改进蜂群算法的多维QoS云计算任务调度算法2017-12-01 985
-
基于云计算遗传算法的多任务调度算法2017-12-07 981
-
异构系统多副本容错调度算法2018-03-13 887
-
linux嵌入式系统算法,嵌入式Linux操作系统调度算法研究2021-11-02 1093
全部0条评论

快来发表一下你的评论吧 !
