

怎样去减少Confluent Cloud Kafka运营成本呢
描述
流式数据已成为企业构建和运营出色数据产品的必要条件,而 Apache Kafka 已成为实时流式传输的标准。
虽然采用 Kafka 变得至关重要,但在如何部署 Kafka 时,数据团队有多种选择。
Kafka 最初是安装在服务器上的开源软件。复杂且高度可配置的 Kafka 早期使用者亲身感受了管理 Kafka 集群的困难、耗时和昂贵。那些还在使用本地 Kafka 的用户正在采用诸如“数据可观测性平台”之类的解决方案,以赋予他们对环境的自动可见性和控制权。
除此之外,其他公司正在转向云计算,其中有很多选择,每一种都为 Kafka 提供不同级别的VIP服务。为此,我们可以将 Kafka 服务分为两个基本类别:
1.Kafka即服务:用户的 Kafka 集群被提升并转移到托管服务提供商,如 AWS、Cloudera、Red Hat (IBM) 或 Azure,后者处理大部分基础设施管理,包括供应、配置和维护服务器。为了保障安全,每个用户的 Kafka 实例都托管在他们自己的物理服务器上,采用单租户架构。尽管在云中,用户仍然保留对其 Kafka 环境的大部分控制权——这意味着用户仍然有责任对 Kafka 环境进行管理。
2.完全托管的 Kafka:由Confluent Cloud首创。Confluent Cloud 几乎消除了运行 Kafka 的所有操作麻烦,同时提供了开发人员喜欢的即时可扩展性和简单可靠的可靠性。正如Confluent Cloud 发布者 Kai Waehner 自夸的那样:“如果 Kafka 软件是汽车引擎,那么托管 Kafka 或 Kafka-as-a-service 就是汽车,这使得 Confluent Cloud 相当于一辆自动驾驶汽车”。
Confluent Cloud可减少
企业运营Kafka的成本
作为完全托管 Kafka 的标准承载者,Confluent Cloud 确实提供了用户想要的任何风格的 Kafka,包括本地、混合和托管即服务。Confluent Cloud 认识到,许多用户根本没有准备好从一个极端(Kafka 的完全手动控制和可定制性)跳到另一个极端(在无服务器 Confluent Cloud 中对 Kafka 的控制较少,甚至可见性更低)。
Kafka 的成本,除了硬件之外,还包括管理和开发应用程序的成本。因此,对于公司而言,仍有大量机会简化其 Kafka 环境并优化其成本提高性价比。
在Kafka-as-a-single-tenant-service(Kafka单租户服务)的情况下,用户的操作复杂性仍然很高。尽管托管服务提供商会自动执行任务,例如引入新的 Kafka 集群,但仍需要监控很多仪表板、做出部署决策、优化数据瓶颈、修复数据错误以及进行存储管理等。为了减轻运营负担并提高动态 Kafka 环境的性价比,本地和混合用户的连续数据可观测性可以使托管的 Kafka 用户从中获益。
完全托管的 Kafka 用户是否面临相同的运营成本?Confluent Cloud 回复说:“并不会。Confluent Cloud 的后端规模经济、近乎零的管理要求、即时和自动的用户弹性可以帮助用户节省巨额的总拥有成本 (TCO) 转化为巨大的总拥有成本 (TCO) 。从Forrester TEI 的2022报告可知,相较于自我管理和部署Kafka,使用Confluent Cloud可帮助企业在三年内节省 260 万美元。

Confluent Cloud Kafka
用户面临的成本问题
Confluent的承诺也反映了 Snowflake的—承诺其三年的投资回报率为2100万美元。低运维、高度可扩展的云数据仓库已被开发人员和数据驱动的公司所采纳。由于云数据仓具有敏捷性特征,可以大大加快企业产品上市时间,用户将“低运维”误认为是“无运维”。这是因为他们忽略了价值工程和云计算运营的基本原则,也忽略了运营监督,例如监控成本、设置成本护栏等。
在Snowflake 使用中有一个著名的案例,该案例错误地配置了一个长达 7 小时的代码测试,导致Snowflake收取用户 72,000 美元的费用。同时,其他 Snowflake 用户发现成本优化不是自动的,仍然需要他们付出大量的努力和监督成本。
基于此,Snowflake 用户被迫尝试各种解决方案,从 Snowflake 的内置资源监视器到可视化的第三方仪表板和报告以及许多其他工具。然而,即使将这些工具拼凑在一起,也无法为用户提供持续的可见性、预测性和成本控制功能,更不用说数据可靠性和数据性能等其他应用了。
同样,在 Confluent Cloud 的“动态即用即付”收费模式中优化成本既不简单,也不会自动进行。流数据量可以瞬间飙升至每秒10 GB。要想监控和防止这种潜在的成本超支,非常不容易。虽然 Confluent Cloud Console 可以实时显示初步使用情况,但实际上,用户的成本将滞后6到24小时。
虽然 Confluent Cloud 使用户能够围绕数据性能问题创建实时触发器和警报,且不会造成成本超支。但如果开发人员忘记关闭大容量测试流数据管道,或者采取保守的归档策略导致存储费用增加,这可能是Confluent Cloud将面临的问题。同时,Confluent Cloud 用户在支付每月使用费前,不会注意到这个问题。
数据可观测性如何帮助用户减少
Confluent Cloud Kafka运营成本
对于想要认真监控和管理其 Confluent Cloud 环境的用户,Confluent建议他们寻找第三方提供商,而像HK-Acceldata这样的企业数据可观测性平台就可以为其服务。
HK-Acceldata 通过 Confluent Cloud 的 API 获取成本和性能指标,通过自己的监控生成额外的分析,然后将两者结合起来以创建进一步的见解、警报和建议。下面介绍一下HK-Acceldata 帮助用户防止成本超支并优化成本的五种方式:
1)为 Confluent Cloud 数据管道的性能和使用情况提供持续可见性和警报。在实时数据流下,处理、发送和存储的事件量会急剧增加,尤其是在 Confluent Cloud 的即时、多 GB 可扩展的情况下。HK-Acceldata的计算可观察性有助于监控可能造成的数据瓶颈以及导致进程崩溃的数据峰值。HK-Acceldata 还提供实时视图,帮助用户选择正确数量的分区和主题,以优化用户的性价比。
2)生产者-主题-沿袭可见性。HK-Acceldata 的Kapxy工具可让 Confluent Cloud 用户进一步了解 Kafka 的三个关键组件——生产者、主题和消费者。因此,用户可以从端到端更精细地跟踪数据。通过深入了解数据的实际流动方式,用户可以准确计算管道、应用程序或企业各部门的使用情况和成本,不仅可以实现准确的成本退款、ROI 计算,还可以支持数据管道重用和其他价值工程工作。

使用 HK-Acceldata 跟踪 Confluent Cloud 中的数据路径
3)监控和防止消费者滞后。Kafka中最大的潜在问题之一是摄取的数据与下游应用程序或使用者接收的数据存在差距。如果差距过大,那么存储在Kafka代理中的数据可能会在传输成功之前就自动过期。HK-Acceldata 提供高级别的可见性,可在用户的整个Confluent Cloud数据管道中查找潜在问题,例如找到离线和复制不足的分区、最大和最偏斜的主题、不同步的副本数量是否在增长以及滞后最多的消费者组等。用户也可以深入了解消费者组或查看单个事件,所有这些可见性都可以帮助用户防止成本滞后,不需要用户通过昂贵的计算或存储来解决这个问题。
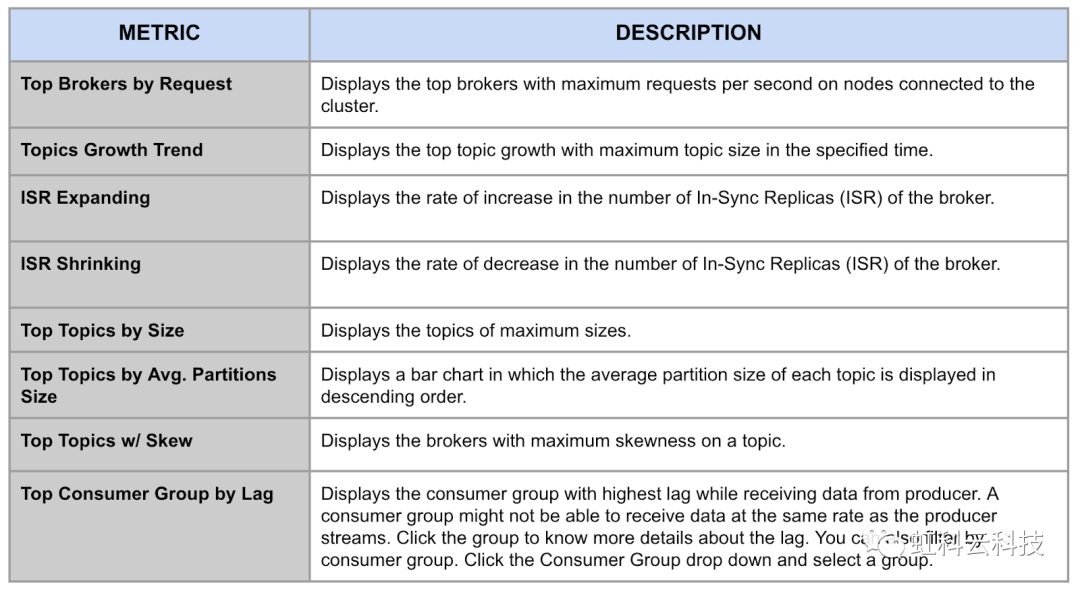
HK-Acceldata 的 Kafka 仪表板图表有助于防止代价高的消费者滞后
4) 防止数据丢失。如上所述,Consumer Lag和其他瓶颈不仅会直接增加用户的处理成本,还会导致数据丢失。这是因为用户可以控制 Kafka Brokers(服务器)存储数据的时间长度。如果数据瓶颈或延迟持续时间过长,则代理可能会在数据成功传输到消费者应用程序之前清除数据。HK-Acceldata 的监控仪表板可帮助用户诊断数据丢失的原因,而Kapxy等工具可以精确定位丢失的数据及其的位置。
5) 清理、验证和转换流数据。将HK-Acceldata与Kafka和Confluent Cloud 管道一起使用,可以实时摄取、验证和转换事件以提高用户的数据质量和可靠性。同时,还减少了搜索和修复数据错误的时间,用户也不需要对有问题的数据管道和应用程序进行故障排除,这大大降低了企业的运营成本,投资回报率显著提升。
总结
上述企业数据可观测性平台HK-Acceldata 5个优势也有助于简化旧 Kafka 环境到 Confluent Cloud 的迁移过程。因为Confluent Cloud与本地或托管的单租户Kafka集群有很大不同,任何迁移对用户的环境而言都是从头开始,而不是简单的提升和转移。HK-Acceldata 的自动化数据准备和监控可以使迁移变得轻松且顺利,同时也可以调整资源以匹配工作区和 SLA 要求,从而平衡性能与成本。
总之,如果使用完全托管的 Confluent Cloud ,公司仍然需要对运营成本进行监督,而HK-Acceldata Data Observability for Kafka 解决方案可以很好的解决这一问题。Confluent Cloud 的用户可以使用HK-Acceldata等连续数据可观测性平台为其提供的额外可见性和监控,从而降低用户的总拥有成本(TCO)。
审核编辑:刘清
-
基于闪存存储的Apache Kafka性能提升方法2019-07-24 1297
-
怎样去设置数值元件的格式呢2021-09-26 1555
-
怎样去获取Android的电池电压呢2021-10-09 4095
-
怎样去使用springboot呢2021-10-25 1163
-
怎样去使用HSE/HSI去配置RCC的时钟呢2021-11-10 1531
-
怎样去快捷的操作AT指令呢2021-12-07 1818
-
socket通信该怎样去实现呢2022-01-20 2345
-
怎样去配置Android的SDIO部分呢2022-02-10 1676
-
Ubuntu固件的编译该怎样去使用呢2022-02-15 1764
-
怎样去写回调函数呢?怎样去使用回调函数呢2022-02-23 1706
-
Confluent宣布修改其平台部分组件的开源许可2018-12-19 3422
-
Kafka的概念及Kafka的宕机2021-08-27 3300
-
使用数据可观测性减少Confluent Cloud Kafka 运营成本的五种方式2022-09-27 1497
-
怎样去解决Kafka消息重复的问题呢?2023-02-12 2014
-
在Boost电源中该怎样去选择电容的型号和电容容量呢?2023-08-14 5067
全部0条评论

快来发表一下你的评论吧 !
