

基于将 CLIP 用于下游few-shot图像分类的方案
描述
一.研究背景
对比性图像语言预训练模型(CLIP)在近期展现出了强大的视觉领域迁移能力,可以在一个全新的下游数据集上进行 zero-shot 图像识别。为了进一步提升 CLIP 的迁移性能,现有方法使用了 few-shot 的设置,例如 CoOp 和 CLIP-Adapter,即提供了少量下游数据集的训练数据,使得 CLIP 能够更好的针对不同的视觉场景做出调整。但是,这种额外的训练步骤会带来不小的时间和空间资源开销,一定程度上影响了 CLIP 固有的快速知识迁移能力。因此,我们提出了 Tip-Adapter,一种不需要额外下游训练并且能很大程度提升 CLIP 准确率的 few-shot 图像分类方法。基于此,我们又提出了一种仅需要少量微调就能达到 state-of-the-art 性能的方案:Tip-Adapter-F,实现了效率和性能的最佳折中。如下表 1 所示,Tip-Adapter 不需要任何训练时间,即可以将 CLIP 在 ImageNet 数据集提升 + 1.7% 准确率(Accuracy),而 Tip-Adapter-F 仅需要之前方案十分之一的训练时间(Epochs,Time),就可以实现现有最佳的分类性能。
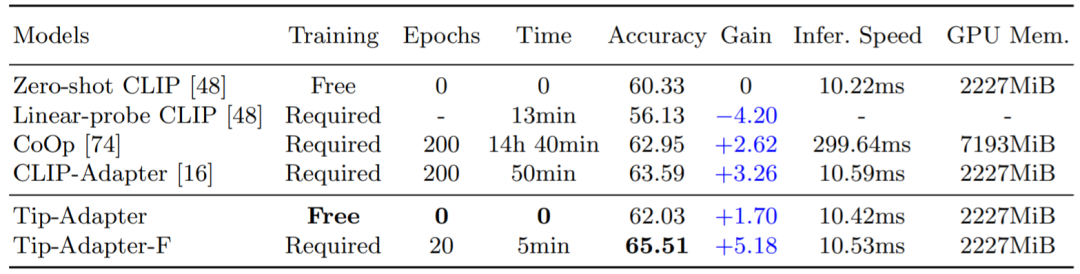
表 1:不同方案在 ImageNet 数据集上 16-shot 的图像分类准确率和训练时间的比较
二.研究方法
1.Tip-Adapter
Tip-Adapter 的整体网络结构如下图 1 所示,对于给定的 few-shot 训练数据集和标签,我们借助 CLIP 通过一个非训练的方案来构建一个缓存模型(Cache Model),它存储了来自下游训练数据的分类知识;在测试时,Tip-Adapter 通过将 Cache Model 的预测和原始 CLIP 的预测进行线性加和,来得到更强的最终分类结果。
详细的来说,我们使用 CLIP 预训练好的视觉编码器(Visual Encoder)来提取 few-shot 训练集所有图片的特征,作为 Cache Model 的 Keys;并且将对应的图片标签转化为 one-hot 编码的形式,作为 Cache Model 的 Values。这种 Key-Value Cache Model 的构建方法由于使用的是已经预训练好的 Visual Encoder,所以不需要任何训练开销;并且考虑到 few-shot 训练集中,每一个类别只含有少量的图片(1~16 shots),Cache Model 也几乎不会占用额外的显存开销,参考表一中的 GPU Mem. 指标。
对于一张测试图片,我们首先会利用 CLIP 的 Visual Encoder 来得到它的特征,再将该特征视为 Query 去 Cache Model 中进行下游 few-shot 数据的知识检索。由于 Keys 也是由 CLIP 的 Visual Encoder 提取得倒,因此和测试图片特征 Query 同源,我们可以直接计算它们之间的余弦相似度得倒一个 Key-Query 的邻接矩阵,此矩阵可以看作是每一个对应 Value 的权重。因此,我们可以计算 Values 的加权和来得到该测试图像通过检索 Cache Model 得到的分类预测。除此之外,我们还可以通过将测试图片特征和 CLIP 的 Textual Encoder 文本特征进行匹配,来得到 CLIP 的 zero-shot 预测。通过将两者进行线性加权求和,我们得到了最终的分类预测,该预测既蕴含了 CLIP 预训练的图像语言对比性知识,也结合了下游新数据集的 few-shot 知识,因此可以实现更强的图像分类准确率。
基于 Tip-Adapter 的网络结构,我们可以进一步将 Cache Model 中的 Keys 部分变为学习参数,即可以通过训练来进行更新,该方案为 Tip-Adapter-F。借助已经构建好的 Cache Model,Tip-Adapter-F 仅需要现有 CLIP-Adapter 十分之一的训练回合数和时间,就可以实现更高的性能,如表一所示。
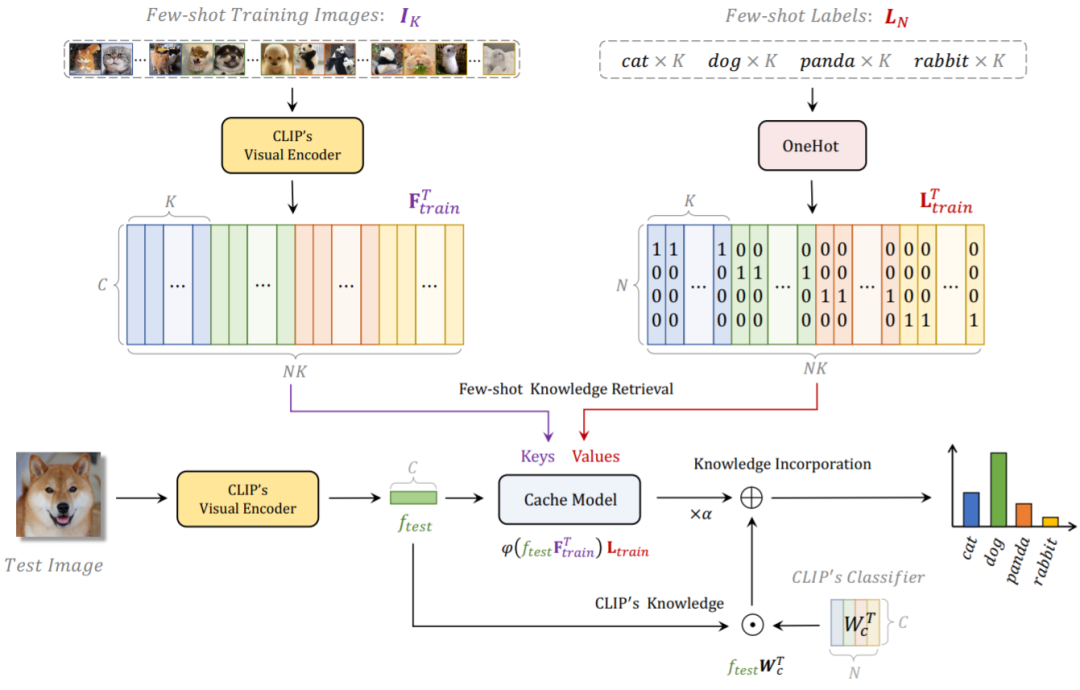
图 1:Tip-Adapter 和 Tip-Adapter-F 的网络流程图
2.Tip-Adapter 和现有方案的区别与联系
对比 CLIP-Adapter,如图 2 所示,Tip-Adapter 存储的 Keys 和 Values 其实可以分别对应于 CLIP-Adapter 中 adapter 结构的两个线性层,只不过前者是不需要训练来构建的,后者是随机初始化,然后需要训练来学习最佳的参数。
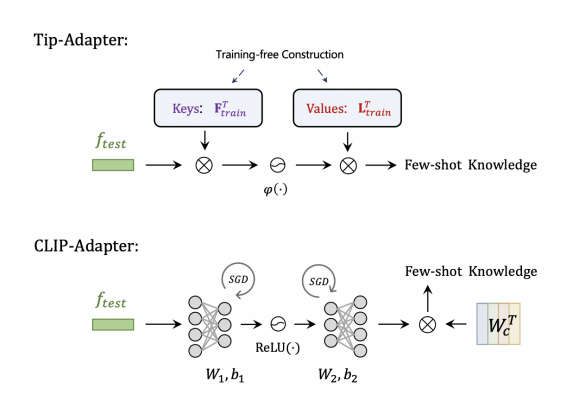
图 2:Tip-Adapter 相比于 CLIP-Adapter
对比现有的其他构建 Cache Model 的方案,如图 3 所示,Tip-Adapter 的 Cache Model 可以看作是一种多模态的视觉语言 Cache。因为 CLIP 的 Textual Encoder 输出的特征可以看作是文本的 Key-Value,即相当于测试图片特征作为 Query,分别在视觉和文本的 Cache 中检索知识,相对于现有的仅含视觉 Cache 的方案,Tip-Adapter 能够利用多模态知识得到更强的识别性能。
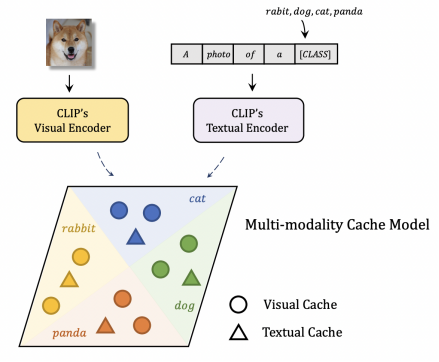
图 3:Tip-Adapter 相比于其他构建 Cache Model 的方案
三.实验结果
1. 在 ImageNet 的分类准确率
图 4 和表 2 比较了 Tip-Adapter、Tip-Adapter-F 和现有各个方案在 1、2、4、8、16 shots 的 few-shot 图像分类准确率;表 3 比较了 16-shot ImageNet 数据集上使用不同 CLIP 的 Visual Encoder 的准确率比较。可见,我们的两种方案都在资源开销很小的情况下,达到了非常卓越的性能。
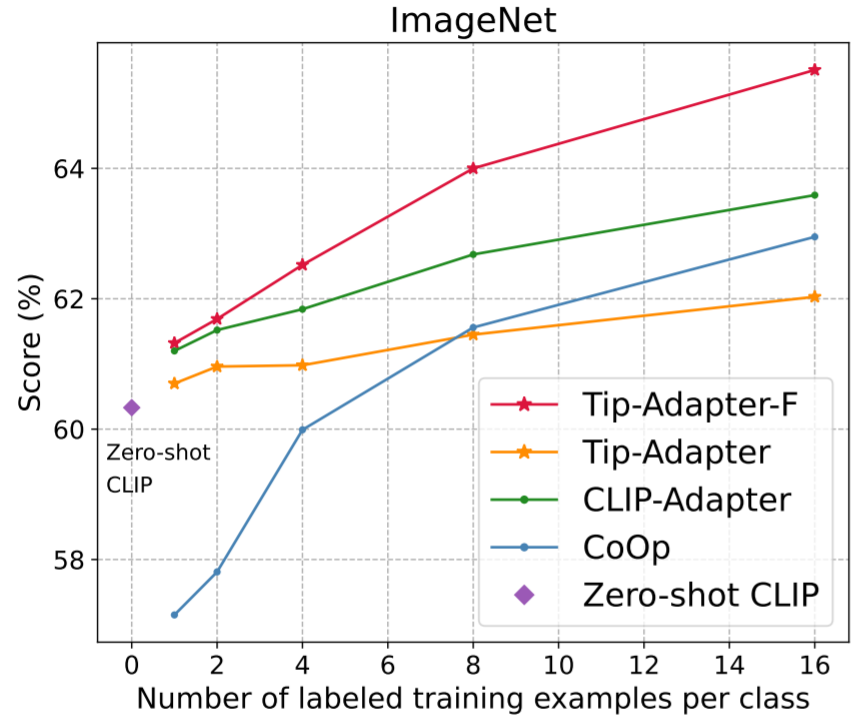
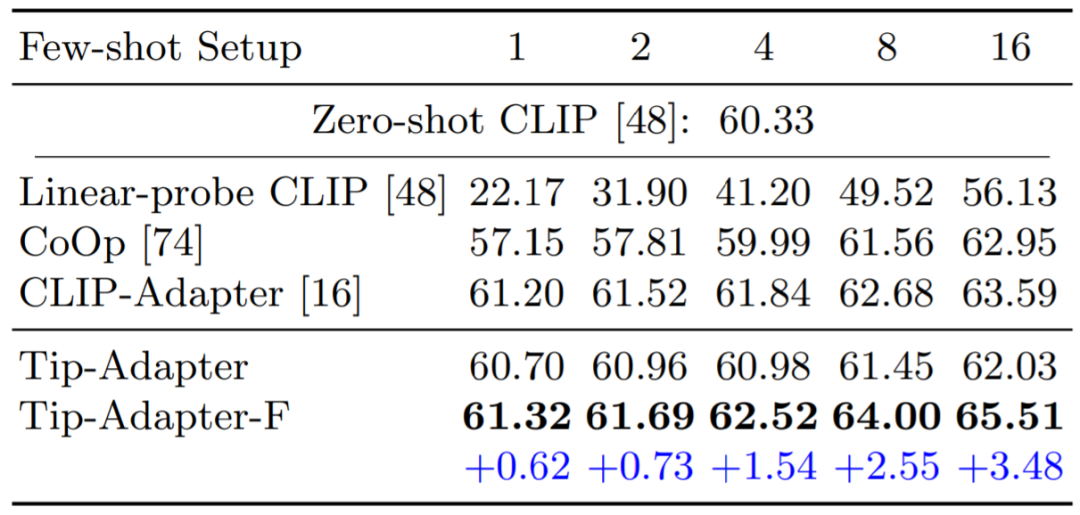
图 4 和表 2:ImageNet 数据集上不同方法的 1~16-shot 图像分类准确率比较
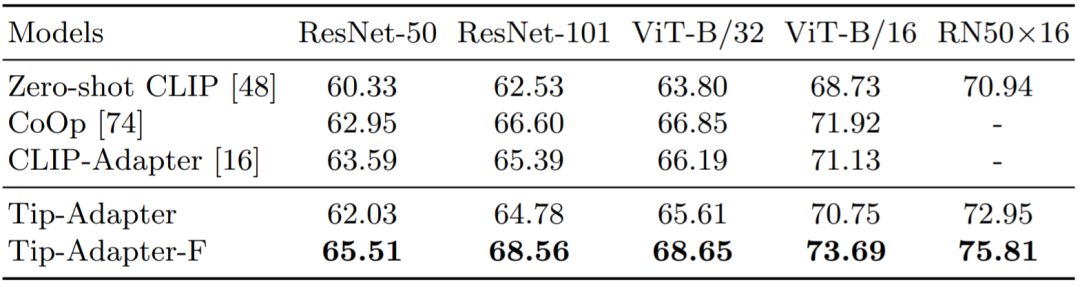
表 5:16-shot ImageNet 上不同 CLIP 的 Visual Encoder 的图像分类准确率比较
2. 在另外 10 个图像分类数据集
如图 5 所示,我们提供了另外 10 个图像分类数据集的准确率比较结果,分别是 StandfordCars,UCF101,Caltech101,Flowers102,SUN397,DTD,EuroSAT,FGVCAircraft,OxfordPets 和 Food101。如图所示,我们的 Tip-Adapter-F 均取得了最高的识别准确率。
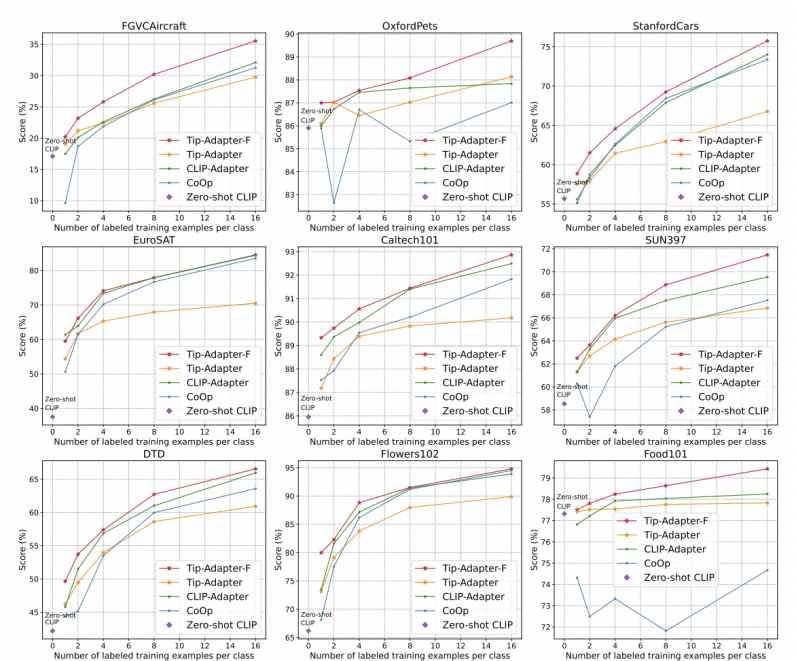
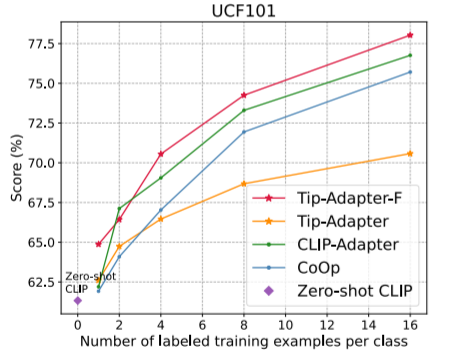
图 5:另外 10 个数据集上不同方法的 1~16-shot 图像分类准确率比较
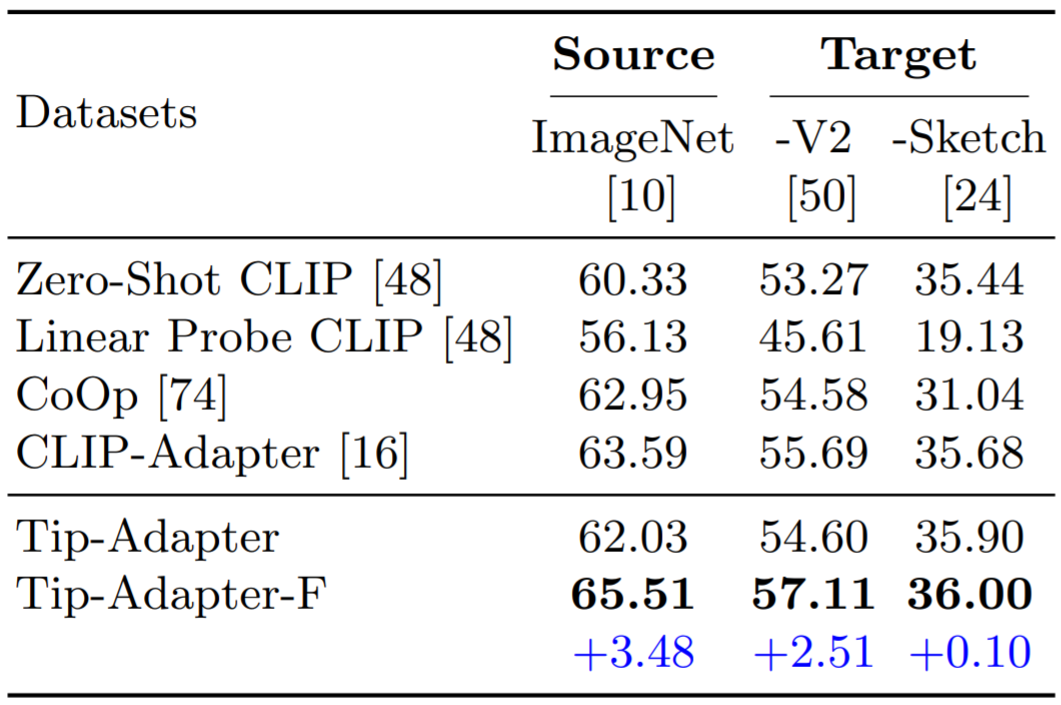
3. 领域泛化能力的测评
我们也测试了 Tip-Adapter 和 Tip-Adapter-F 在领域泛化(Domain Generalization)方面的表现。如表 6 所示,我们的两种方案都表现出了很强的鲁棒性以及特征迁移能力。
四.结论
本文提出了 Tip-Adapter,一种可以免于训练的将 CLIP 用于下游 few-shot 图像分类的方案。Tip-Adapter 通过构建一个 Key-Value Cache Model,来作为测试图片 Query 的知识检索库,并通过融合 Cache Model 的预测和 CLIP 的 zero-shot 预测,来得到更强的识别性能。我们期望 Tip-Adapter 可以启发更多预训练模型高效迁移的后续工作。
-
基于显式证据推理的few-shot关系抽取CoT2023-11-20 2118
-
基于AX650N+CLIP的以文搜图展示2023-11-01 2998
-
如何利用CLIP 的2D 图像-文本预习知识进行3D场景理解2023-10-29 3190
-
APE:对CLIP进行特征提纯能够提升Few-shot性能2023-07-19 2998
-
语言模型性能评估必备下游数据集:ZeroCLUE/FewCLUE与Chinese_WPLC数据集2023-03-27 3133
-
介绍一个基于CLIP的zero-shot实例分割方法2022-10-13 6557
-
介绍两个few-shot NER中的challenge2022-08-24 1621
-
胶囊网络在小样本做文本分类中的应用(下)2021-09-27 3166
-
深度学习:小样本学习下的多标签分类问题初探2021-01-07 8633
全部0条评论

快来发表一下你的评论吧 !
