

基于卷积多层感知器(MLP)的图像分割网络unext
电子说
描述
1. 摘要
UNet及其最新的扩展如TransUNet是近年来领先的医学图像分割方法。然而,由于这些网络参数多、计算复杂、使用速度慢,因此不能有效地用于即时应用中的快速图像分割。为此,我们提出了一种基于卷积多层感知器(MLP)的图像分割网络unext。我们设计了一种有效的UNeXt方法,即在前期采用卷积阶段和在后期采用MLP阶段。我们提出了一个标记化的MLP块,在该块中,我们有效地标记和投射卷积特征,并使用MLP来建模表示。
为了进一步提高性能,我们建议在输入mlp时shift输入的channel,以便专注于学习局部依赖性。在潜在空间中使用标记化的mlp减少了参数的数量和计算复杂度,同时能够产生更好的表示,以帮助分割。该网络还包括各级编码器和解码器之间的跳跃连接。测试结果表明,与目前最先进的医学图像分割架构相比,UNeXt的参数数量减少了72x,计算复杂度降低了68x,推理速度提高了10x,同时也获得了更好的分割性能。
2. 网络结构
2.1 网络设计:
UNeXt是一个编码器-解码器体系结构,有两个阶段:
1) 卷积阶段
2) tokenized MLP阶段。
输入图像通过编码器,其中前3个块是卷积,下2个是tokenized MLP块。解码器有2个tokenized MLP块,后面跟着3个卷积块。每个编码器块减少特征分辨率2倍,每个解码器块增加特征分辨率2。跳跃连接也被应用在了编码器和解码器之间
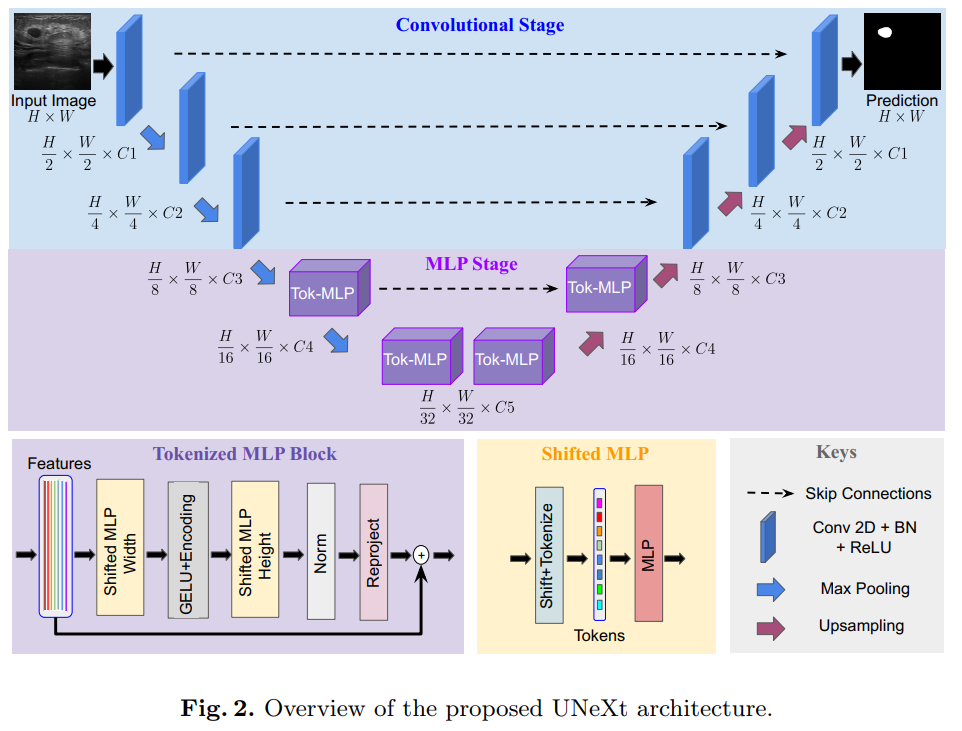
作者减少了每个stage的通道数。
每个stage的通道数,对比标准的Unet:
UNeXt:32 64 128 160 256
UNet:64 128 256 512 1024
在这里面就减少了很多的参数量
2.2 卷积阶段
有三个conv block,每个block都有一个卷积层(传统Unet是两个)、批量归一化层和ReLU激活。我们使用的内核大小为3×3, stride为1,padding为1。编码器的conv块使用带有池窗口2×2的max-pooling层,而解码器的conv块使用双线性插值层对特征图进行上采样。我们使用双线性插值而不是转置卷积,因为转置卷积基本上是可学习的上采样,会导致产生更多可学习的参数
2.3 Shifted MLP
在shifted MLP中,在tokenize之前,我们首先移动conv features通道的轴线。这有助于MLP只关注conv特征的某些位置,从而诱导块的位置。这里的直觉与Swin transformer类似,在swin中引入基于窗口的注意,以向完全全局的模型添加更多的局域性。由于Tokenized MLP块有2个mlp,我们在一个块中跨越宽度移动特征,在另一个块中跨越高度移动特征,就像轴向注意力中一样。我们对这些特征做了h个划分,并根据指定的轴通过j个位置移动它们。这有助于我们创建随机窗口,引入沿轴线的局部性。
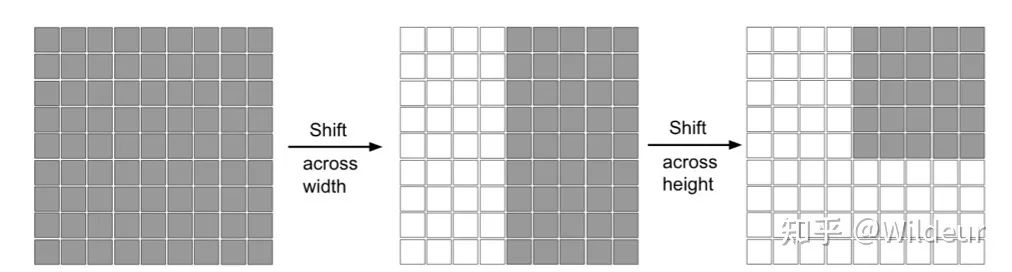 Shift操作
Shift操作
图中灰色是特征块的位置,白色是移动之后的padding。
2.4 Tokenized MLP阶段
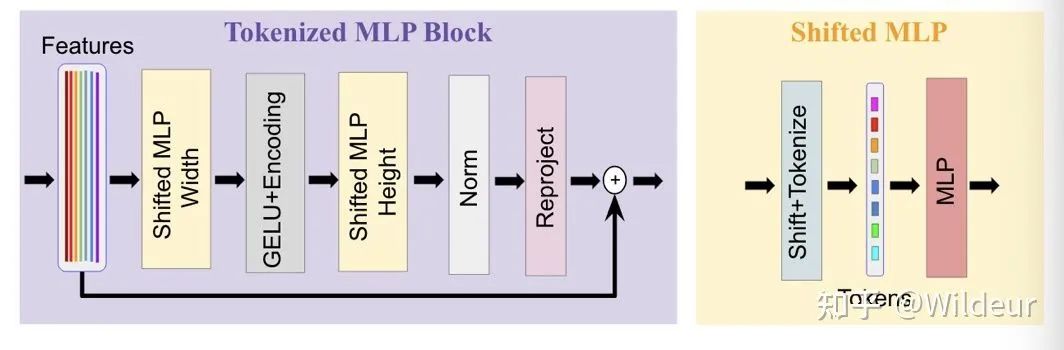 image-20220402001733482
image-20220402001733482
在Tokenized MLP块中,我们首先shift features并将它们投射到token中。为了进行token化,我们首先使用3x3conv把特征投射到E维,其中E是embadding维度(token的数量),它是一个超参数。然后我们将这些token传递给一个shifted MLP(跨越width)。接下来,特征通过 DW-Conv传递。然后我们使用GELU激活层。然后,我们通过另一个shifted MLP(跨越height)传递特征,该mlp把特征的尺寸从H转换为了O。我们在这里使用一个残差连接,并将原始标记添加为残差。然后我们利用layer norm(LN),并将输出特征传递到下一个块。LN比BN更可取,因为它更有意义的是沿着token进行规范化,而不是在Tokenized MLP块的整个批处理中进行规范化。
我们在这个块中使用DWConv有两个原因:
1)它有助于编码MLP特征的位置信息。从中可以看出,在一个MLP块中Conv层已经足够对位置信息进行编码,并且实际性能优于标准的位置编码技术。当测试或者训练分辨率不相同时,像ViT中的位置编码技术需要插值,这通常会导致性能下降。
2)DWConv使用更少的参数,因此提高了效率。
Tokenized block的计算流程
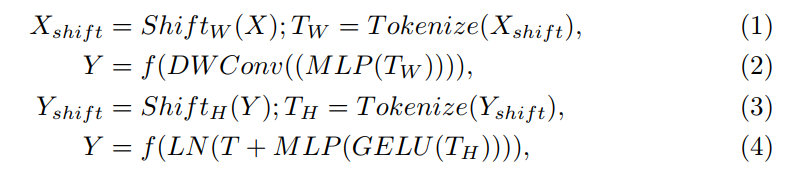
所有这些计算都是在嵌入维数h上执行的,这个维数明显小于特征的维数 (H/N)×(H/N) ,N是关于降维的2的因子。在我们的实验中,除非另有说明,否则我们使用768。这种设计tokenized MLP block的方法有助于编码有意义的特征信息,而不会对计算或参数贡献太多。
3.实验结果
在ISIC和BUSI数据集进行了实验
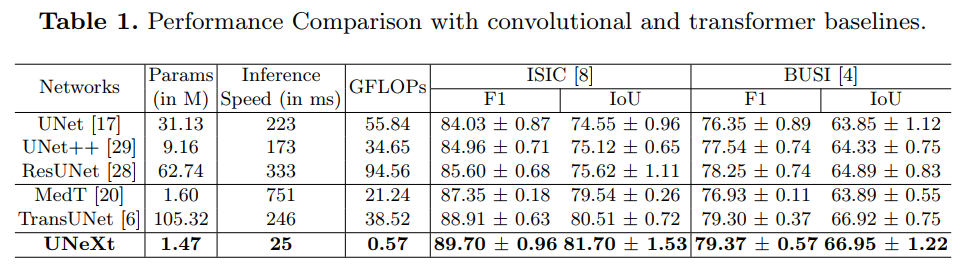
在ISIC数据集的对比
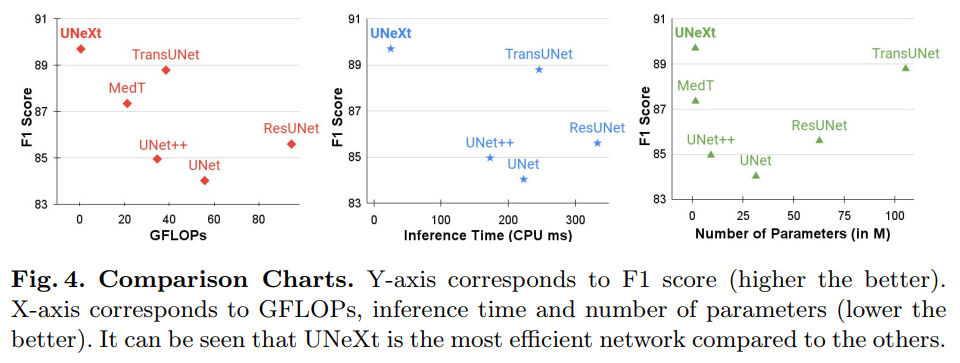

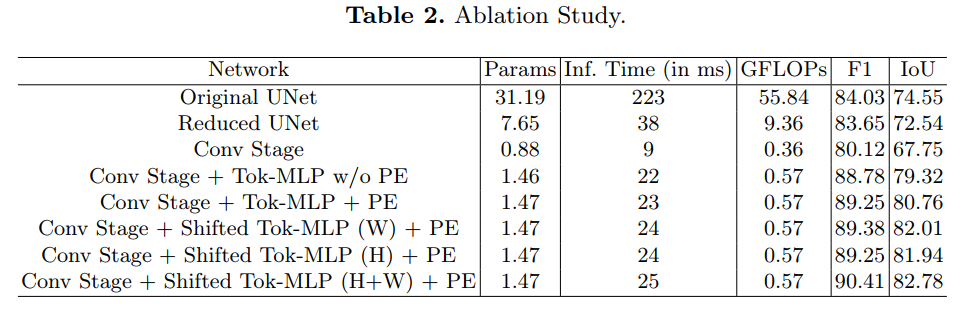
4. 个人感悟
首先每个convolutional阶段只有一个卷积层,极大的减少了运算量,是答主第一次见了。
其次是把MLP的模块引入了Unet,算是很新颖了。
在Tokenized MLP block中使用DW- CONV,让人眼前一亮。
-
使用全卷积网络模型实现图像分割2019-05-28 2457
-
如何使用Keras框架搭建一个小型的神经网络多层感知器2021-11-22 1264
-
基于MLP的快速医学图像分割网络UNeXt相关资料分享2022-09-23 4412
-
人工神经网络在金相图像分割中的应用研究2013-03-12 876
-
人工智能–多层感知器基础知识解读2018-07-05 6846
-
聚焦语义分割任务,如何用卷积神经网络处理语义图像分割?2018-09-17 1037
-
全卷积网络FCN进行图像分割2018-09-26 1102
-
多层感知机(MLP)的设计与实现2023-03-14 9298
-
PyTorch教程5.2之多层感知器的实现2023-06-05 842
-
使用多层感知器进行机器学习2023-06-24 1451
-
卷积神经网络算法有哪些?2023-08-21 2768
-
深度神经网络模型有哪些2024-07-02 3704
-
多层感知器、全连接网络和深度神经网络介绍2024-07-11 10128
-
多层感知器的基本原理2024-07-19 2597
全部0条评论

快来发表一下你的评论吧 !
