

语义分割模型 SegNeXt方法概述
电子说
描述
语义分割是对图像中的每个像素进行识别的一种算法,可以对图像进行像素级别的理解。作为计算机视觉中的基础任务之一,其不仅仅在学术界广受关注,也在无人驾驶、工业检测、辅助诊断等领域有着广泛的应用。
近期,计图团队与南开大学程明明教授团队、非十科技刘政宁博士等合作,提出了一种全新的语义分割模型 SegNeXt,该方法大幅提高了当前语义分割方法的性能,并在Pascal VOC 分割排行榜上名列第一。该论文已被 NeurIPS 2022 接收。
Part 1
语义分割模型SegNeXt
研究背景 自2015年FCN[2] 被提出以来,语义分割开始逐渐走向深度学习算法,其常用架构为编码-解码器结构(Encoder-Decoder)。在 vision transformer 被提出之前,人们通常采用卷积神经网络(如 ResNet、VGGNet、GoogleNet 等) 作为其编码器部分;最近,由于vision transformer 在视觉领域的成功,语义分割编码器部分开始逐渐被换成基于vision transformer的模型(如 ViT、SegFormer、HRFormer等)。但是,基于 vision transformer编码器的方法真的比基于卷积神经网络的方法更好么?为了回答这个问题,Jittor团队重新思考了语义分割任务对神经网络的要求,并针对语义分割的任务专门设计了一个基于卷积神经网络的编码器MSCAN 和一个语义分割模型 SegNeXt。
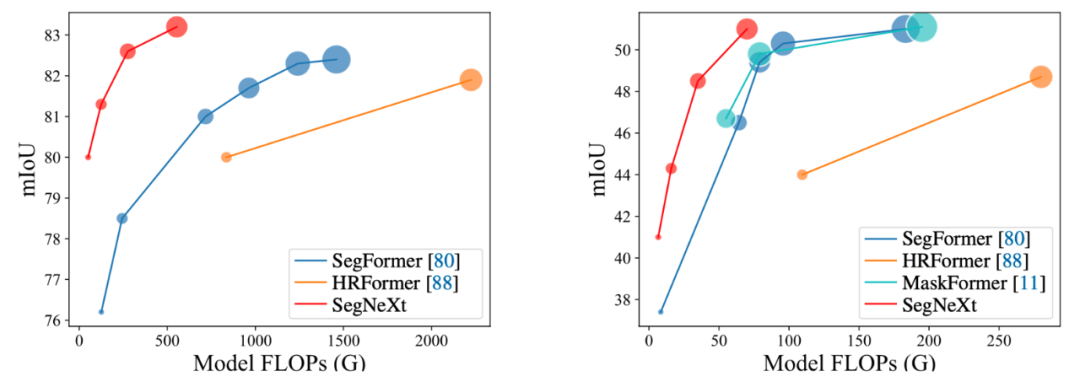
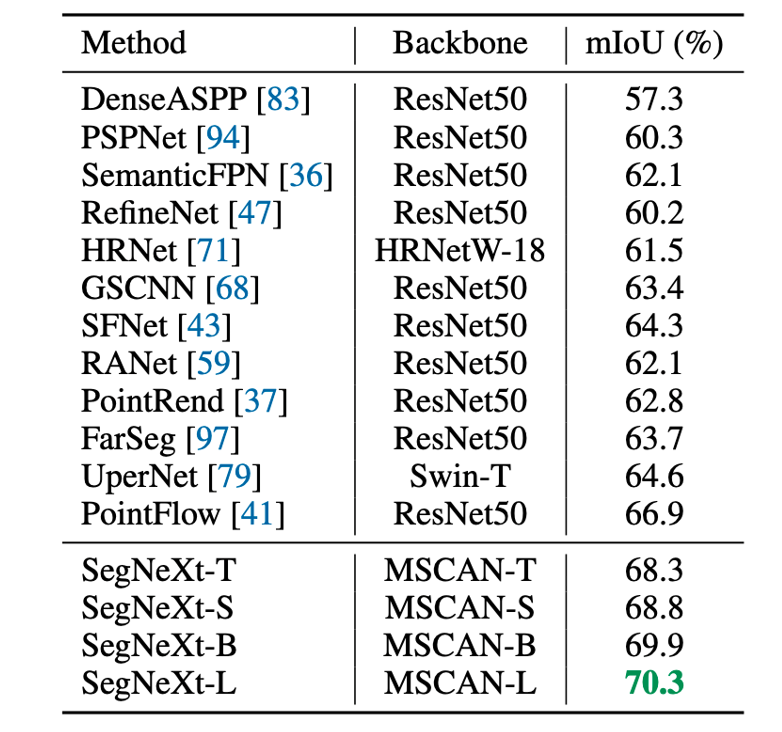
图1. SegNeXt 和其他语义分割方法的性能对比,其中红色为SegNeXt
方法概述
论文首先分析了语义分割任务本身以及之前的相关工作,总结出四点语义分割任务所需的关键因素。1)强大的骨干网络作为编码器。与之前基于 CNN 的模型相比,基于Transformer 的模型的性能提升主要来自更强大的骨干网络。2)多尺度信息交互。与主要识别单个对象的图像分类任务不同,语义分割是一项密集的预测任务,因此需要在单个图像中处理不同大小的对象,这就使得针对语义分割任务的网络需要多尺度信息的交互。3)注意力机制:注意力可以使得模型关注到重点的部分,并且可以使得网络获得自适应性。4)低计算复杂度:这对于常常处理高分辨率图像的语义分割任务来说至关重要。
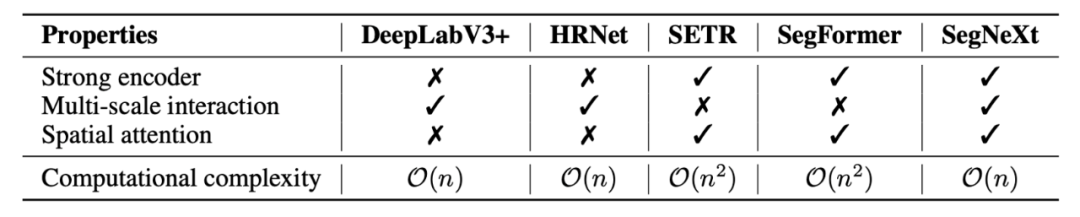
表 1 不同方法所具有的的属性对比
为了满足上述四点要求,作者设计了一种简单的多尺度卷积注意力机制 (MSCA)。如图 2 所示,MSCA 主要是采用大卷积核分解、多分支并行架构以及类似VAN[3]的注意力机制。这使得 MSCA 可以获得大感受野、多尺度信息以及自适应性等有益属性。基于 MSCA,该论文搭建了一种层次化神经网络 MSCAN 作为SegNeXt 的编码器部分。除此之外,作者采用了 UNet 架构,并选择了HamNet[4] 作为 SegNeXt 的解码器部分。分析和实验证明,MSCAN和 Ham 优势互补,两者相互配合,使得 SegNeXt 实现了优异的性能。
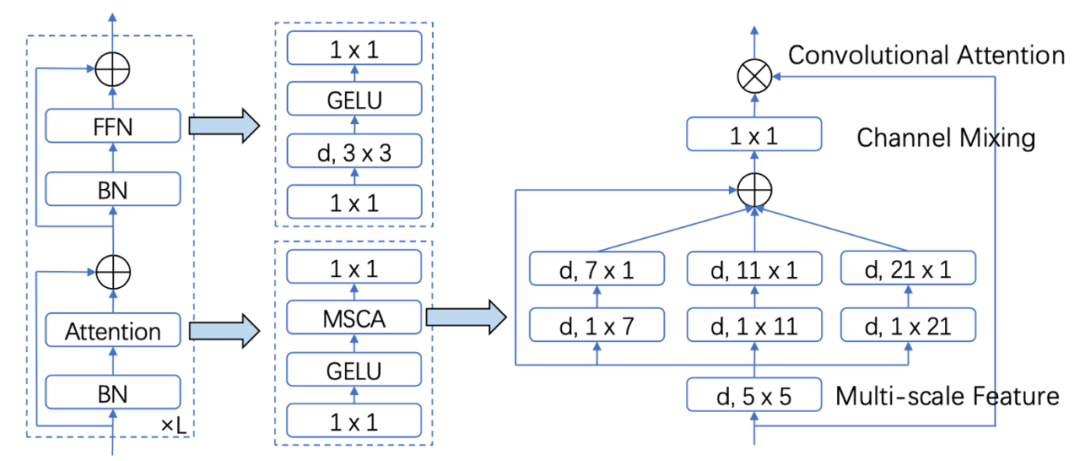
图 2:多尺度卷积注意力(MSCA) 示意图 实验结果 本文在五个常见分割数据集上 ADE20K, Cityscapes,COCO-Stuff, Pascal VOC, Pascal Context 和一个遥感分割数据集 iSAID做了测评,SegNeXt均超过了之前的方法。限于篇幅,我们仅展示部分结果。
表2:在 ADE20K、Cityscapes, COCO-Stuff 上的实验结果
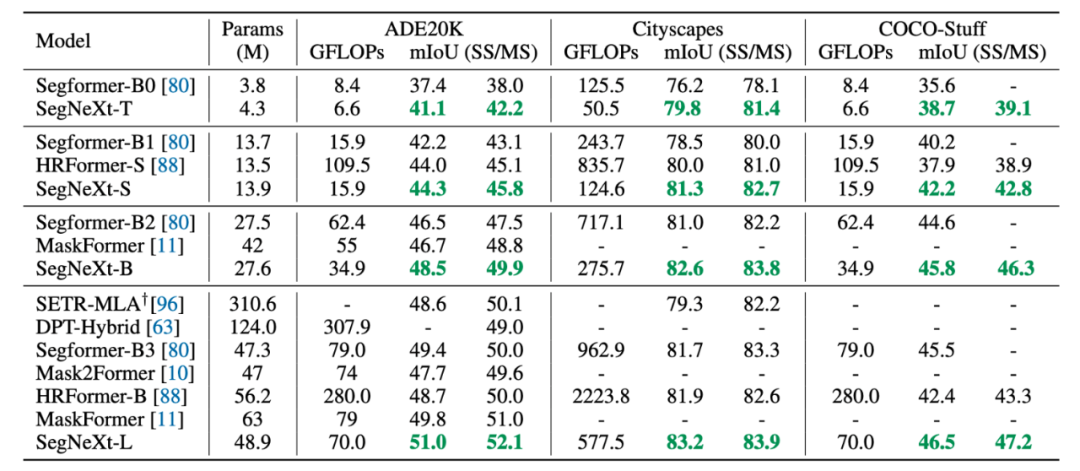
表 3 SegNeXt 在遥感数据集上的实验结果
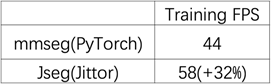
Part 2 计图语义分割算法库JSeg Jittor团队基于自主深度学习框架Jittor[5],并借鉴MMSegmentation语义分割算法库的特点,开发了语义分割算法库JSeg。MMSegmentation是广泛使用的功能强大的语义分割算法库,新推出的JSeg可以直接加载MMSegmentation的模型,同时借助Jittor深度学习平台的优势,使其更高效、稳定运行,可以实现训练和推理快速的从PyTorch向Jittor迁移。 目前JSeg已经支持4个模型、4个数据集,其中模型包括在Pascal VOC test dataset斩获第一的SegNeXt模型,数据集包括经典的ADE20K Dataset、CityScapes Dataset以及遥感分割中的iSAID Dataset等,后续JSeg也将支持更多的模型和数据集! 性能提升 我们使用SegNeX-Tiny模型,与Pytorch实现的版本在NVIDIA TITAN RTX上进行了对比,可以显著缩短模型训练所需要的时间。
表1 JSeg和mmseg(PyTorch)的训练时间对比
易用性提升
由于Jittor动态编译的特性及code算子对python内联C++及CUDA的支持,JSeg在不同环境下无需对任何算子进行手动编译,即可轻松运行不同模型,免去了用户对不同模型分别配置环境的负担,同时方便用户对不同方法进行更公平的比较。此外,JSeg的设计易于拓展,用户可以基于JSeg已有的模型和功能方便地开展进一步的研究和开发。
实践案例
下面,我们将简要介绍如何使用JSeg训练一个基础模型。
首先,下载数据集到原始数据集目录。

通过tools/convert_datasets下的数据处理脚本对原始数据进行预处理,得到处理后的数据集。然后即可对模型进行单卡或者多卡训练、评估和测试,同时提供了推理接口,用户可以使用10行代码完成一张图片的语义分割,尽可能地降低了用户的使用成本。
-
图像语义分割的实用性是什么2024-07-17 1807
-
图像分割与语义分割中的CNN模型综述2024-07-09 3622
-
深度学习图像语义分割指标介绍2023-10-09 1097
-
CVPR 2023 | 华科&MSRA新作:基于CLIP的轻量级开放词汇语义分割架构2023-07-10 2797
-
图像语义分割的概念与原理以及常用的方法2023-04-20 7437
-
基于SEGNET模型的图像语义分割方法2021-05-27 1001
-
基于深度神经网络的图像语义分割方法2021-04-02 1698
-
基于深度学习的三维点云语义分割研究分析2021-04-01 1544
-
分析总结基于深度神经网络的图像语义分割方法2021-03-19 1532
-
语义分割方法发展过程2020-12-28 6125
-
语义分割算法系统介绍2020-11-05 8118
-
DeepLab进行语义分割的研究分析2019-10-24 1221
-
Facebook AI使用单一神经网络架构来同时完成实例分割和语义分割2019-04-22 3855
-
聚焦语义分割任务,如何用卷积神经网络处理语义图像分割?2018-09-17 1068
全部0条评论

快来发表一下你的评论吧 !
