

关于“GPU性能的硅前预测”的5个问题
处理器/DSP
描述
当我们谈论GPU性能的时候就不能回避PPA这个概念。性能(Performance)、功耗(Power)、面积(Area)组成了现代大型芯片的三维。硬件架构、频率和工艺制程共同决定了一块芯片在PPA三角形中的表现。创造完美的“三边型战士”需要付出巨大的代价,而我们的目标是在成本可控的情况下做出更符合客户需求的芯片。PPA是在芯片立项之初就有明确的设计指标,而性能这一项涉及到了各个子模块的协作,需要从设计开始就同步进行方案的验证。
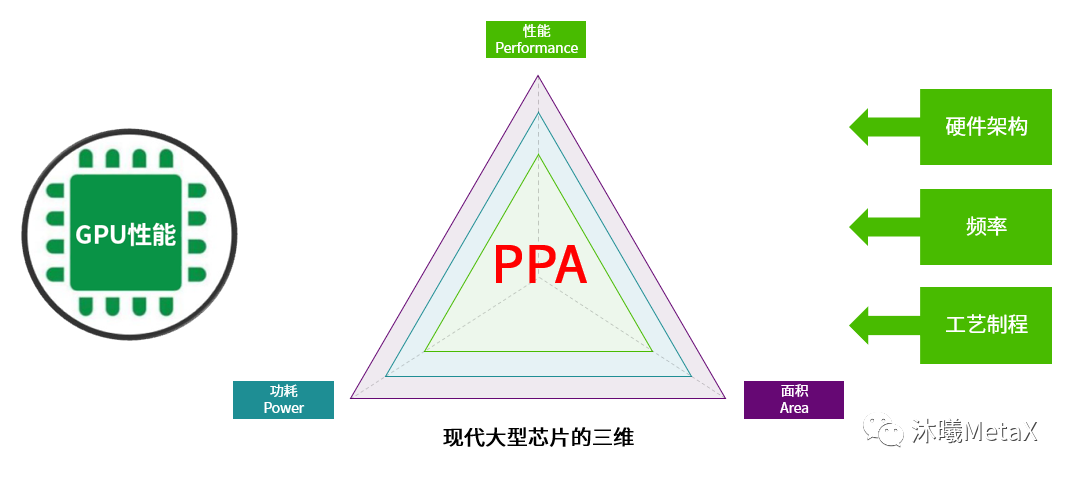
图1:PPA介绍
接下来让我们通过5个问题来进一步了解“GPU性能的硅前预测”。
#1
为什么要关心硅前性能?
人们都很认可“GPU性能非常关键”这一观点。从2011年到2022年,GPU单卡算力提高了10倍以上,而GDDR/HBM带宽提高大约2倍以上。对于国产GPU而言,能够提供与国际一线大厂媲美的性能是关键点所在。因此,无论是GPU硬件和软件架构师,还是市场客户都对Benchmark在GPU硅前阶段的性能预测很感兴趣。硅前性能的预测结果对设计验证、软件开发和市场客户极具意义和价值。其意义在于用实际数据起到定性和定量作用。芯片性能直接影响到芯片的售价,更高的性能意味着更高的售价和更强的市场竞争力。
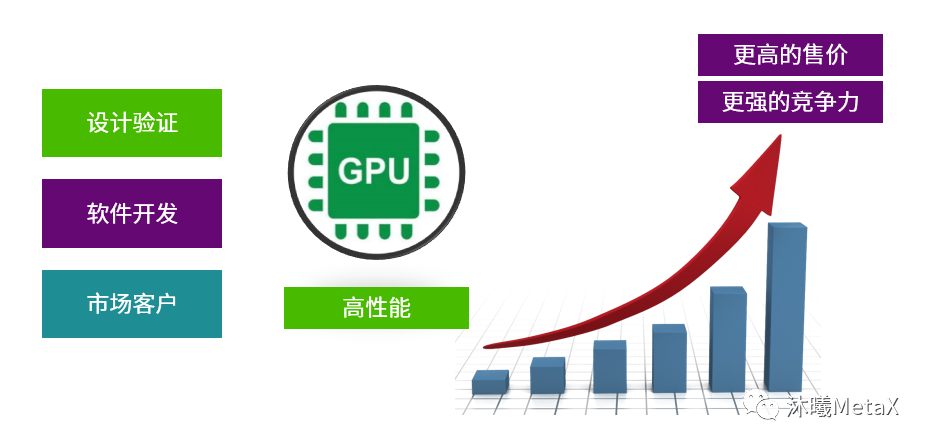
图2:硅前性能预测的意义与价值
但芯片从设计到量产的周期非常长,如果等到量产之后才开始分析性能则为时太晚,容易落入闭门造车的窘境。而硅前性能预测和验证可以提前了解芯片性能指标是否达标,进行市场调研,比对分析芯片与竞品的差距,与客户需求的差距,及时对架构的短板分析优化。
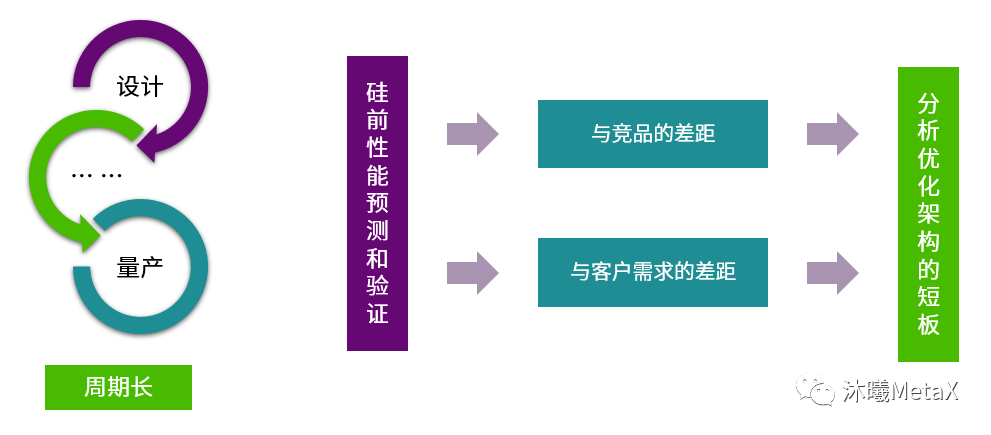
图3:硅前性能预测的作用
#2
预测和验证什么?
我们可以从两个角度来定义GPU的性能。其一是单模块的纯粹性能,例如内存带宽(Memory Bandwidth)或者浮点算力(FLOPs)。另一个是包含了所有模块协作的应用性能。业界有标准的测试来评价芯片的综合性能,而这也是产品间互相竞争的最主要评分工具。
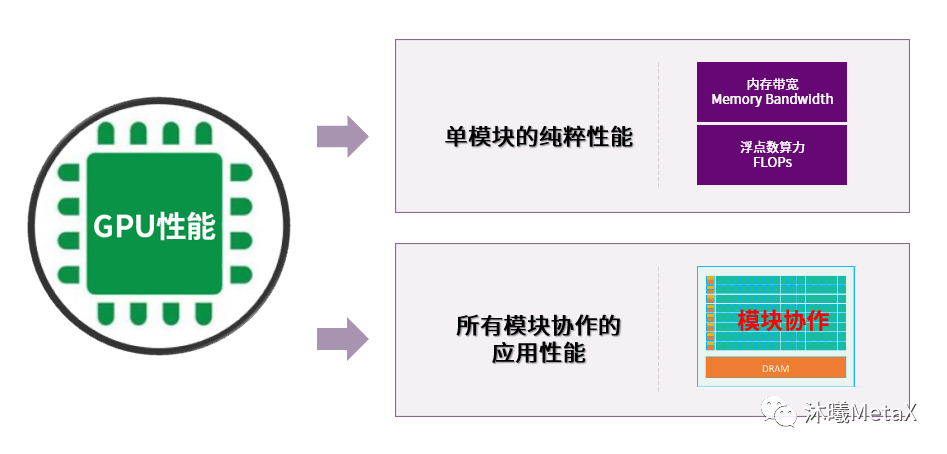
图4:定义GPU性能的两个角度
#3
如何预测?
抽象来看,GPU由多个功能系统组成。主要为核心计算系统(Core)、缓存系统(Cache)和内存系统(Memory Subsystem)。架构师会在性能预测阶段改变性能模型中不同模块的参数来探索各种组合的综合性能。例如计算系统中的核心数量、缓存中的缓存大小结构、内存的预取策略、DRAM的时序参数等。初级的性能模型可以在给定参数下给出标准测试的结果,而高级的性能模型可以分析其中的瓶颈,以帮助架构师高效地探索模块参数变化对综合性能的影响。另外架构师并不能无限堆高各种参数,而是需要在PPA三角形的限制下找到最合适的芯片架构。
#4
如何验证?
验证的整个流程分为两个层面,第一层面是在GPU核心计算模块(Core)上的本真硬件性能验证,第二层面是SoC和Multi-GPU平台性能的验证。涉及模块越少则测试仿真时间越短,模块越多则仿真时间越长,一旦遇到问题需要多个设计师共同“会诊”。
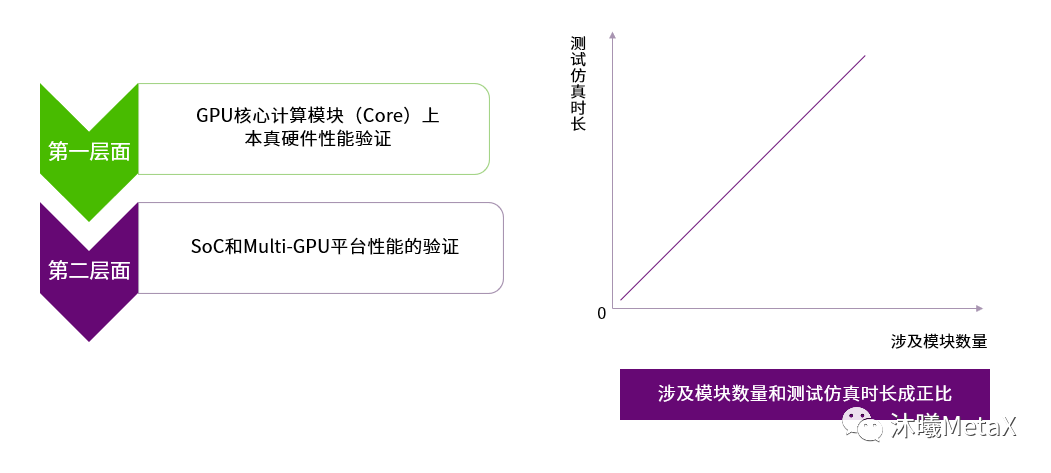
图5:验证流程
为了提升验证的速度和效率,一般会由小及大,尽量在最小的模块组合中发现问题,避免单一模块的小问题被掩盖直到芯片“大会诊”。
首先是对单个子模块进行独立的性能指标测试,确保子模块的性能达到设计要求。然后是将子模块组成大模块进行测试。此时就可以在核心模块上进行部分应用层面的测试,比如部分的Benchmark,以了解在没有后续Cache和Memory Subsystem环境下核心模块的绝对性能上限如何。我们会将所有测试分为两类:计算密集(Compute-Bound)和访存密集(Memory-Bound)。计算密集即其对核心计算模块压力很高,其性能上限取决于核心性能。这类测试就可以在核心模块的测试中完成。而访存密集的测试则会放在缓存及内存系统中进行。

图6:验证步骤和测试类别
在验证中我们会使用仿真波形、性能计数器等方式来确认设计是否符合要求。而RTL仿真所产生的性能计数器也会和性能模型中的数据进行交叉对比。一方面确认设计达标,另一方面校准性能模型,提升性能模型的可信度,这样当性能模型被用在下一代产品的预测时就能提供更加精准的预测结果。
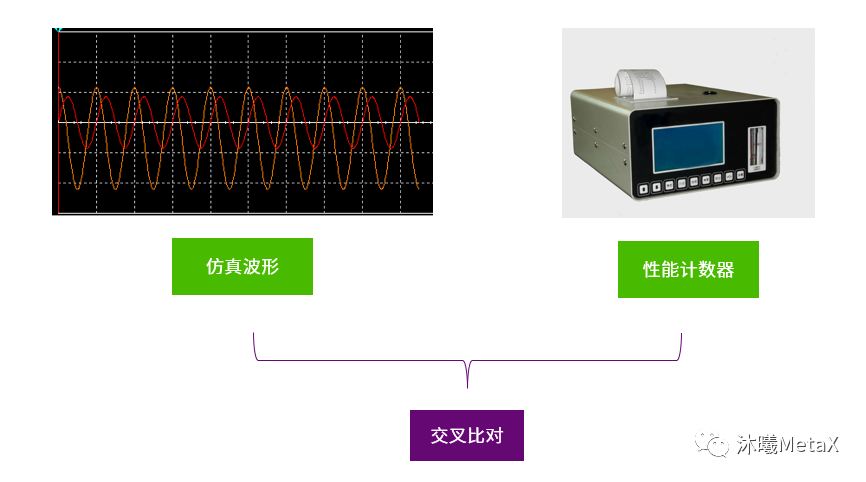
图7:确认验证结果的方式
#5
谁会参加到GPU性能硅前预测的任务中呢?
包括GPU架构和设计验证模型组都会参加到流程里。模型组(Model team)在其中会起到主导作用,主要负责提供并且校准各个子模块的模型,包括指令流水线(Instruction Pipeline)、高速缓存(Cache Hierarchy)、总线接口(Bus Interface)和简单的I/O内存子系统。在实际应用测试中发现性能不达标的情况下也会先行分析瓶颈所在,再与相关模块的设计师架构师具体分析并改进现有设计。
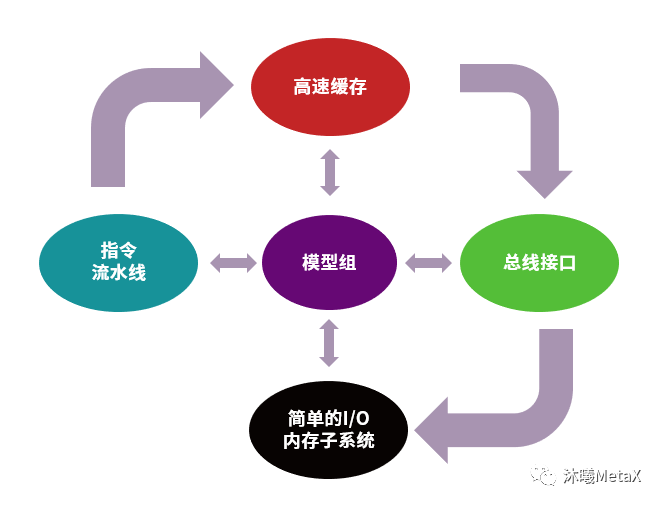
图8:模型组的工作内容
(解说词来源:沈承程,沐曦架构师)
编辑:黄飞
-
关于GPU场景与局限性2023-01-10 2937
-
关于GPU知识2013-01-15 4195
-
GPU2016-01-16 5087
-
NVIDIA火热招聘GPU高性能计算架构师2017-09-01 5170
-
如何在vGPU环境中优化GPU性能2018-09-29 3426
-
什么GPU设置可提供5-10个vWorkstations所需的性能?2018-09-30 3163
-
Intel即将推出的GPU将与Arm兼容2022-03-29 4396
-
如何使用iMX8mmini提高GPU性能?2023-04-18 738
-
Mali GPU性能分析工具2023-09-05 1130
-
关于区块链在2018年的12个预测2018-01-09 6844
-
新一代的PowerVR GPU与前一代的GPU相比2018-04-09 4005
-
2020年即将到来,关于Linux和开源给出的五个预测2019-12-26 4434
-
基于5个问题阐述GPU在增强AI和机器学习技术中的作用2023-01-30 1932
-
GPU的预测瞬态仿真分析2023-05-30 1537
-
GPU 性能原理拆解2025-02-08 1377
全部0条评论

快来发表一下你的评论吧 !
