

OpenVINO各AI模型对应不同处理器的效能
电子说
描述
Google于2017年制作了TeachableMachine网页版本的AI软件工具,甫一推出就受到相当好的好评与回响,原因在于这个网站几乎可以不需要任何说明与叙述,就可以自行摸索搞懂原来用AI实践计算机视觉是这么一回事!
之后更于2019年推出Teachable Machine V2,除了将原有的Image Classification(影像分类)由固定三个分类扩充为自定义分类数量,并且增加了Audio(声音)与Pose(人体姿势)两个类别的分类器,此外更支持项目的存盘与转导出功能,不但能保留数据于日后继续编辑,同时还能汇出Keras、TensorFlow、tf.js等不同格式的模型档案,大幅提高了后续转应用的可玩性!
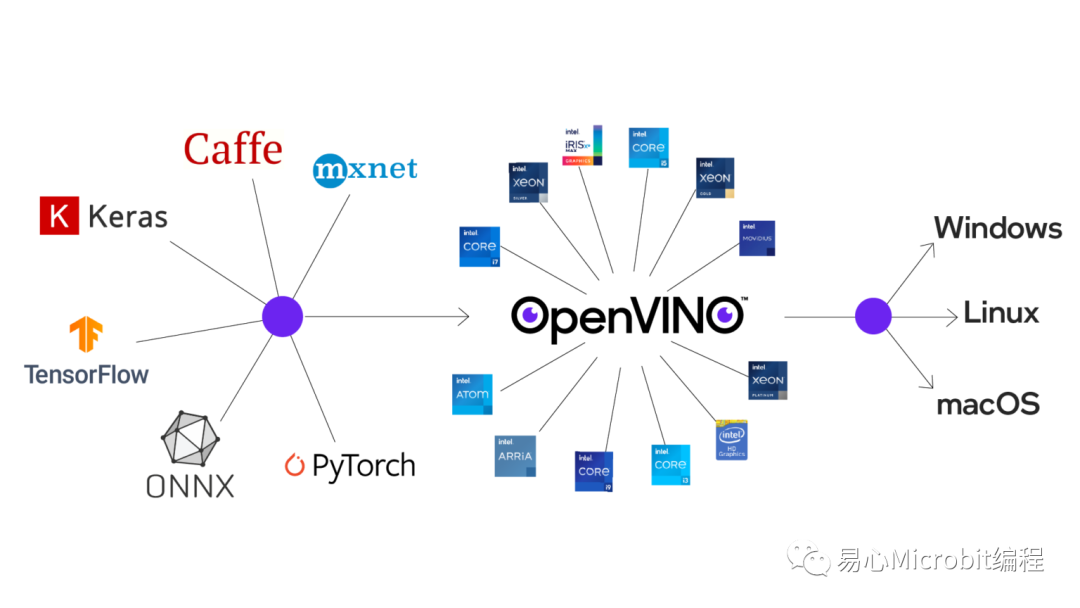
OpenVINO执行模型优化后能跨平台布署AI推论
OpenVINO为Intel于2018年推出的AI布署工具套件,支持不同深度学习软件框架如TensorFlow、PyTorch、Caffe等的模型输入,并对模型进行优化与调教后,布署于不同操作系统进行推论。其初版发布时间和Intel推出NCS2(Neural Compute Stick 2)的时间点相当接近,而一直让笔者有着「OpenVINO就是要来搭配NCS2进行AI推论优化」的一种错觉。
直到后来OpenVINO版本持续更新提其高支持完整性与提高了易用性,才让笔者确实看清,以目前Intel CPU/GPU的处理效能,已经足以负荷多数情境的AI应用推论了!如下方直方图显示着Intel的不同世代显示芯片在的AI推论效能比较,分别以第九代iGPU与第12代iGPU执行不同模型之间的效能差异。其中光是Gen12相比Gen9跑FP16模型推论FPS就已超过两倍之谱,若是将模型转换为INT8进行推论更可以在将效能再拉升至一倍左右!若要进一步了解OpenVINO各AI模型对应不同处理器的效能,也可以参照OpenVINO Benchmark Result。
https://docs.openvinotoolkit.org/latest/openvino_docs_performance_benchmarks_openvino.html
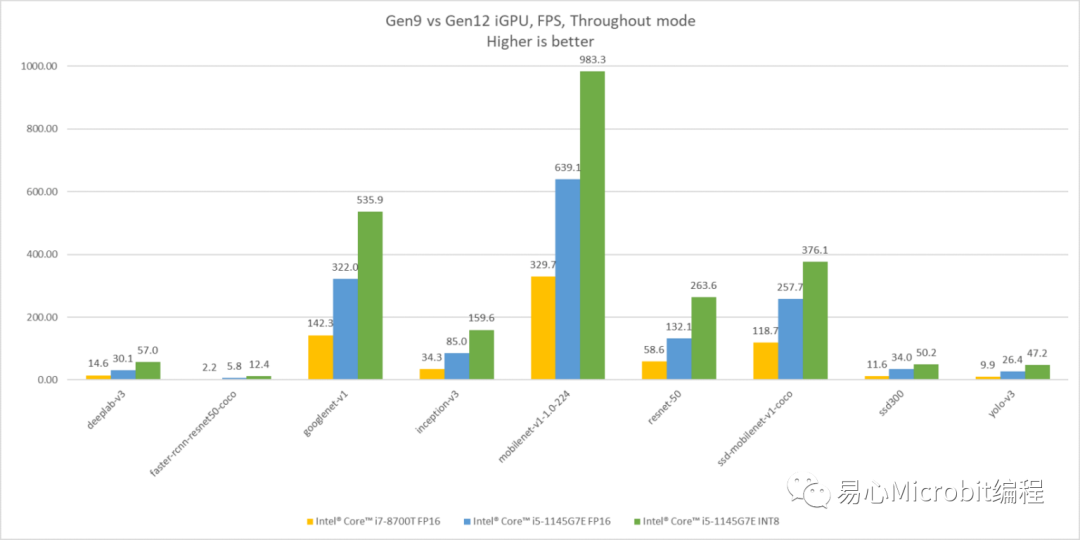
Intel Gen9 与 Gen12 iGPU AI推论效能比较
在分别接触了Teachable Machine与OpenVINO之后,不禁让人联想,是否能让这两个简单易用的酷工具结合在一起?一个负责处理模型训练,另一个负责处理推论与应用,若能成功便可让大伙享齐人之福,把复杂事情简单化,短时间内即可完成应用雏形。不啰嗦即刻来做测试!
我们先到Teachable Machine网站上去训练模型,至于要辨识的影像就直接就地取材-使用我们的双手做手势的分类。这里笔着做了五个手势分类,分别为剪刀、石头、布、赞、以及数字7的手势,各取得约略350张的影像数据作为输入的dataset。训练参数则直接用预设参数:EPOCH: 50,Batch Size: 16,Learning Rate: 0.001进行训练。最后我们就选择Export Model将模型导出,选择的格式为TensorFlow Savedmodel方便OpenVINO进行转换,顺利取得converted_savedmodel.zip档案即完成模型训练的步骤啦!
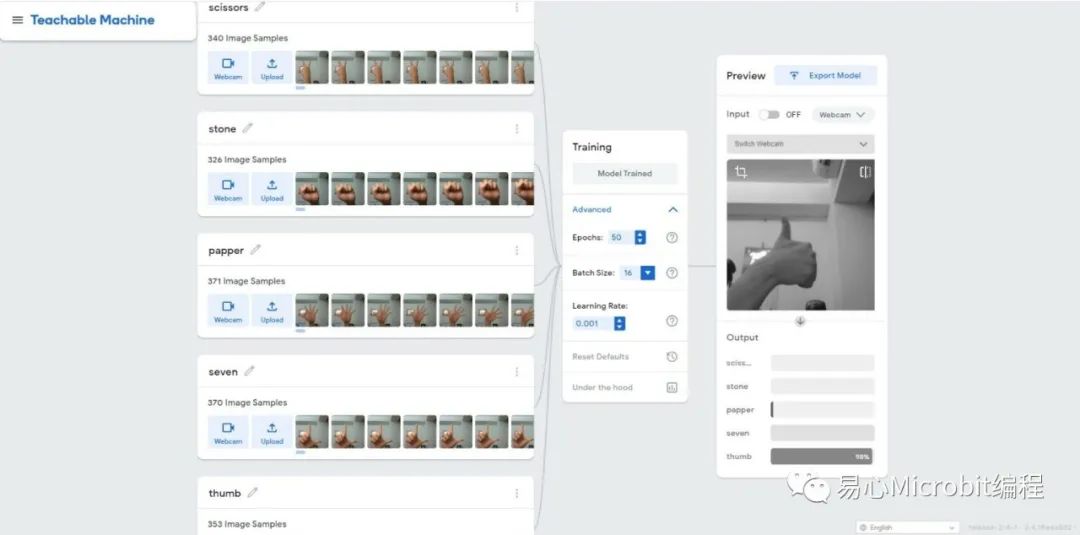
在Teachable Machine训练影像分类模型
接着我们要将从Teachable Machine取得的TensorFlow模型文件(.pb),使用OpenVINO进行转换。笔者的测试环为Ubuntu20.04操作系统,OpenVINO Tookit使用2021.4 LTS版本,处理器为Intel i7-1185GRE(搭载Iris Xe显示芯片)。要建置OpenVINO开发环境除了在原生系统下载安装包执行所有套件的安装外,现在也可以使用docker快速建置环境,过程其实没什么难度,按照官方文件指引Step by Step就可以了。
https://docs.openvinotoolkit.org/latest/openvino_docs_install_guides_installing_openvino_linux.html
https://docs.openvinotoolkit.org/latest/openvino_docs_install_guides_installing_openvino_docker_linux.html
为了方便建立一个名为tm的文件夹,存放teachable machine模型数据,并且解压缩得到saved_model.pb与labels.txt等档案。
~$ mkdirtm
~$ cd tm
~/tm$unzip converted_savedmodel.zip
Archive: converted_savedmodel.zip
creating: model.savedmodel/
extracting: model.savedmodel/saved_model.pb
creating: model.savedmodel/variables/
extracting:model.savedmodel/variables/variables.data-00000-of-00001
extracting:model.savedmodel/variables/variables.index
creating: model.savedmodel/assets/
extracting: labels.txt
~/tm$
接着执行model optimizer进行模型优化转换,指定目前文件夹取得pb档,这边要注意input_shape参数必须指定为[1,224,224,3],其意义为[N,H,W,C]:
•N: 一次抓取多少数量的影像。
•H: 影像的高度,单位为象素。
•W: 影像的宽度,单位为象素。
•C: 通道数量。若是彩色图像则有RGB三个通道。
上述若N为未知数值(负值)会造成转换上的错误,而在TensorFlow上预设输入的shape为[-1,224,224,3],因此要手动进行shape调整。此外,Teachable Machine使用MobileNet神经网络架构,转换的scale依据OpenVINO转换TensorFlow文件得知为127.5,我们便以此数值代入。
https://docs.openvinotoolkit.org/latest/openvino_docs_MO_DG_prepare_model_convert_model_Convert_Model_From_TensorFlow.html
最后笔者希望可以得到较佳的推论速度,带入data_type参数,并指定模型权重值以FP16的数值格式进行量化。输入以下指令进行模型转换:
~/tm$ source/opt/intel/openvino_2021/bin/setupvars.sh
[setupvars.sh] OpenVINO environmentinitialized
~/tm$ mo_tf.py --saved_model_dirmodel.savedmodel/ --input_shape [1,224,224,3] -s 127.5 –data_type=FP16
执行成功后会在当前目录得到IR(Intermediate Representation)檔saved_model.xml与saved_model.bin。我们就能使用这个IR模型元文件在OpenVINO上进行推论。
推论的部分在边缘装置的推论我们使用OpenVINO toolkit内建的Classification的Demo来做测试,看看实际结果如何。因影像分类Demo目前仅提供C++语言版本,我们需要先行做编译:
~$ cd/opt/intel/openvino_2021/deployment_tools/open_model_zoo/demos/
/opt/intel/openvino_2021/deployment_tools/open_model_zoo/demos$./build_demos.sh
Settingenvironment variables for building demos...
[setupvars.sh]OpenVINO environment initialized
-- The Ccompiler identification is GNU 9.3.0
... 中间讯息省略 ...
[100%]Built target human_pose_estimation_demo
Buildcompleted, you can find binaries for all demos in the/home/openvino/omz_demos_build/intel64/Release subfolder.
/opt/intel/openvino_2021/deployment_tools/open_model_zoo/demos$
编译完成后会看到提示讯息说明可执行文件的路径,同时我们将额外的手势照片存放到~/tm/pic的路径,让范例程序可以用这些图像作为测试数据。执行下方指令启动范例程序,相关参数说明如下:
•-i: <必要参数>,输入影像数据的档案路径或文件夹路径
•-m: <必要参数>,IR模型文件xml的档案路径
•-labels: <必要参数>,分类卷标文本文件的路径
•-d: 执行推论的硬件装置进行推论,可选CPU, GPU,也可以设定MULTI:CPU,GPU同时使用CPU与GPU执行推论。预设为CPU。
•-time: 重复执行推论的时间,预设为-1,代表执行到使用者中断为止。
•-no_show: 不显示影像推论结果。
•-nt: 取得前n个最大可能的类别,预设为5。
~$ cd~/omz_demos_build/intel64/Release
~/omz_demos_build/intel64/Release$./classification_demo -d GPU -m ~/tm/saved_model.xml -i ~/tm/pic/ -labels~/tm/labels.txt
[ INFO ]InferenceEngine: IE version......... 2021.4
Build ........... 0
[ INFO ]Parsing input parameters
[ INFO ]Reading input
[ INFO ]Files were added: 20. Too many to display each of them.
[ INFO ]Loading Inference Engine
[ INFO ]Device info:
[ INFO] GPU
clDNNPlugin version ......... 2021.4
Build ........... 0
Loadingnetwork files
[ INFO ]Batch size is forced to 1.
[ INFO ]Loading model to the device
待模型加载后会跳出一个图形化窗口,显示着目前进行影像分类识别的结果。我们可以看到大部分判定的结果是符合我们的预期的,而少部分判定错误的图像经测试后是在Teachable Machine上就辨识度不佳的图片,整体而言推论分类结果令人满意!
左上角同时显示着当前的效能指针Latency与FPS,因为需要额外处理影像输出的辨识结果,这会降低非常多FPS,所以此数值仅能做参考之用。若想要知道不做输出影像的效能可以每秒几张图像,只要在刚刚执行的命令后面,再加上-no_show –time 10,意思就是不输出推论的影像,并且在模型启动推论10秒后结束程序。当DEMO程序返回时就会显示Latency与FPS,笔者在仅使用GPU的情况下,效能测时得到的结果就高达654.9 FPS与7.2 ms Latency!
此外再补充一点,若我们在Teachable Machine上训练的影像分类数量少于5个分类,在执行DEMO程序时可能会出现"[ ERROR ] The model provides 2 classes, but 5 labels are requestedto be predicted"此错误讯息,原因在于DEMO程序默认会去抓取可能性最高的前5个分类,而实际模型输出的分类数量却少于5个分类而产生错误。可以再加上参数”-nt 1”指定DEMO程序只取得可能性最高的分类即可。

Image classification推论测试结果
小结
各位看过以上流程之后,是不是觉得训练影像分类模型并且布署在自己的装置上执行不再遥不可及,而且是既简单又容易的事!藉由这类简单工具组件帮助我们完成边缘算的训练、转换、到布署总体时间约略在半小时内即可完成。虽然距离实际应用可能还有一小段差距,但藉由把复杂的事情拆解成各个简单的组件与任务,短时间内就能综观全局而找到对的方向努力,各位脑中是否已浮现出各种应用可能性的想象了呢!?
-
无法将Openvino™ 2025.0与onnx运行时Openvino™ 执行提供程序 1.16.2 结合使用,怎么处理?2025-06-24 530
-
运行时OpenVINO™找不到模型优化器,为什么?2025-03-05 541
-
C#集成OpenVINO™:简化AI模型部署2025-02-17 3022
-
C#中使用OpenVINO™:轻松集成AI模型!2025-02-07 2091
-
英特尔酷睿Ultra处理器突破500个AI模型优化2024-05-09 1685
-
如何快速下载OpenVINO Notebooks中的AI大模型2023-12-12 2613
-
在AI爱克斯开发板上用OpenVINO™加速YOLOv8-seg实例分割模型2023-06-05 2102
-
AI爱克斯开发板上使用OpenVINO加速YOLOv8目标检测模型2023-05-26 2771
-
在AI爱克斯开发板上用OpenVINO™加速YOLOv8目标检测模型2023-05-12 2682
-
将数据预处理嵌入AI模型的常见技巧2022-12-16 2311
-
OpenVINO模型优化实测:PC/NB当AI辨识引擎没问题!2022-12-09 3442
-
【大联大世平Intel®神经计算棒NCS2试用申请】客戶年齡性別KIOSK廣告機AI驗證2020-08-26 946
-
AMD Cool and Quiet 处理器效能驱动程序2010-01-29 674
-
基于ESL方法的DSP微处理器行为模型设计2009-04-15 981
全部0条评论

快来发表一下你的评论吧 !
