

介绍当前比较常见的几种近邻搜索算法
电子说
描述
简介
随着深度学习的发展和普及,很多非结构数据被表示为高维向量,并通过近邻搜索来查找,实现了多种场景的检索需求,如人脸识别、图片搜索、商品的推荐搜索等。另一方面随着互联网技术的发展及5G技术的普及,产生的数据呈爆发式增长,如何在海量数据中精准高效的完成搜索成为一个研究热点,各路前辈专家提出了不同的算法,今天我们就简单聊下当前比较常见的近邻搜索算法。
主要算法
Kd-Tree
K-dimension tree,二叉树结构,对数据点在k维空间(如二维 (x,y),三维(x,y,z),k维(x,y,z..))中划分。
构建过程
确定split域的值(轮询 or 最大方差)
确定Node-data的域值(中位数 or 平均值)
确定左子空间和右子空间
递归构造左右子空间
查询过程
进行二叉搜索,找到叶子结点
回溯搜索路径,进入其他候选节点的子空间查询距离更近的点
重复步骤2,直到搜索路径为空
性能
理想情况下的复杂度是O(K log(N)) 最坏的情况下(当查询点的邻域与分割超平面两侧的空间都产生交集时,回溯的次数大大增加)的复杂度为维度比较大时,直接利用K-d树快速检索(维数超过20)的性能急剧下降,几乎接近线性扫描。
改进算法
Best-Bin-First:通过设置优先级队列(将“查询路径”上的结点进行排序,如按各自分割超平面与查询点的距离排序)和运行超时限定(限定搜索过的叶子节点树)来获取近似的最近邻,有效地减少回溯的次数。采用了BBF查询机制后Kd树便可以有效的扩展到高维数据集上 。
Randomized Kd tree:通过构建多个不同方向上的Kd tree,在各个Kd tree上并行搜索部分数量的节点来提升搜索性能(主要解决BBF算法随着Max-search nodes增长,收益减小的问题)
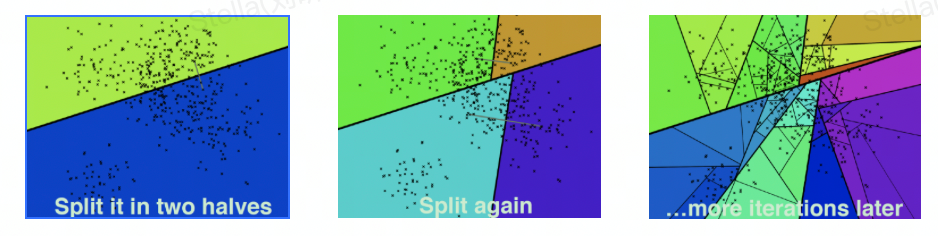
Hierarchical k-means trees
类似k-means tree,通过聚类的方法来建立一个二叉树来使得每个点查找时间复杂度是O(log n) 。
构建过程 :
随机选择两个点,执行k为2的聚类,用垂直于这两个聚类中心的超平面将数据集划分
在划分的子空间内进行递归迭代继续划分,直到每个子空间最多只剩下K个数据节点
最终形成一个二叉树结构。叶子节点记录原始数据节点,中间节点记录分割超平面的信息
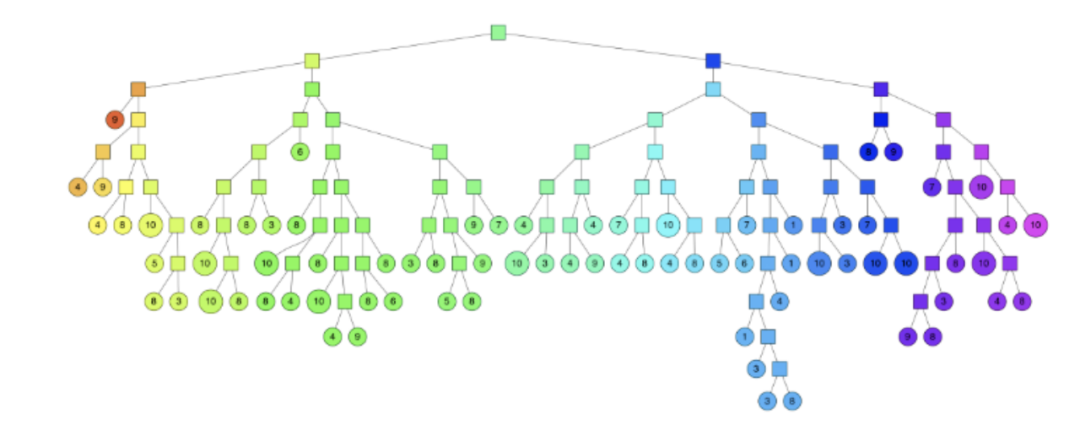
搜索过程
从根节点开始比较,找到叶子节点,同时将路径上的节点记录到优先级队列中
执行回溯,从优先级队列中选取节点重新执行查找
每次查找都将路径中未遍历的节点记录到优先级队列中
当遍历节点的数目达到指定阈值时终止搜索
性能
搜索性能不是特别稳定,在某些数据集上表现很好,在有些数据集上则有些差
构建树的时间比较长,可以通过设置kmeans的迭代次数来优化
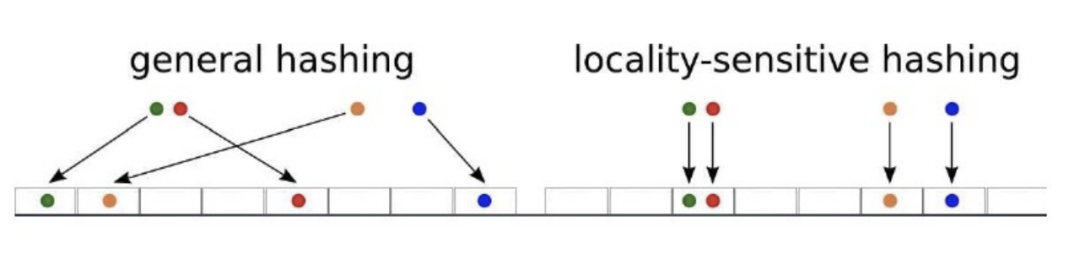
LSH
Locality-Sensitive Hashing 高维空间的两点若距离很近,他们哈希值有很大概率是一样的;若两点之间的距离较远,他们哈希值相同的概率会很小 。
一般会根据具体的需求来选择满足条件的hash函数,(d1,d2,p1,p2)-sensitive 满足下面两个条件(D为空间距离度量,Pr表示概率):
若空间中两点p和q之间的距离D(p,q)p1
若空间中两点p和q之间的距离D(p,q)>d2,则Pr(h(p)=h(q))
审核编辑:刘清
-
线性搜索与二分搜索介绍2025-12-01 162
-
五种运动搜索算法简介2019-07-17 1636
-
Viterbi搜索算法2020-04-14 2059
-
改进的双向启发式搜索算法主要流程是怎样的?2021-05-17 1945
-
改进的二进制搜索算法原理是什么?有什么优势?2021-05-20 1986
-
WebCAD中的剖面区域搜索算法2009-07-30 556
-
四轴飞行器中的自动搜索算法2016-06-08 1608
-
一种改进的邻近粒子搜索算法2017-01-07 729
-
一种改进的自由搜索算法_任诚2017-03-14 1249
-
DS18B20-ROM编码的搜索算法2017-05-04 1821
-
深层次分类中候选类别搜索算法2017-12-05 1143
-
激光散乱点云K最近邻搜索算法2017-12-11 1055
-
以进化算法为搜索策略实现神经架构搜索的方法2021-03-22 1563
-
基于麻雀搜索算法优化SVM的故障诊断2021-06-01 1541
-
图染色局部搜索算法python2023-01-03 718
全部0条评论

快来发表一下你的评论吧 !
